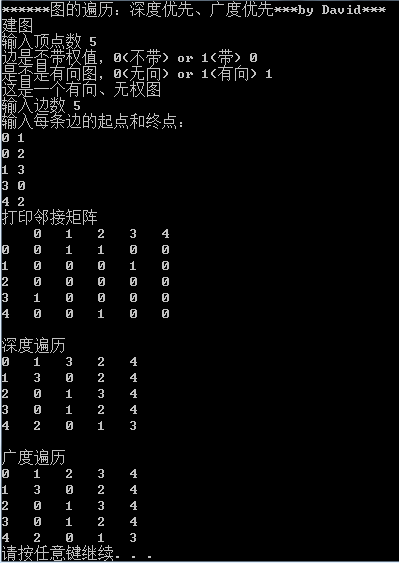
深度优先遍历简称DFS(Depth First Search),广度优先遍历简称BFS(Breadth First Search),它们是遍历图当中所有顶点的两种方式。
深度优先遍历:
选取一个节点开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。
实现方式:回溯(利用栈的先入后出特性)和递归遍历;
首先访问顶点0、1、7、8,这四个顶点依次入栈,此时顶点8是栈顶:
从顶点8退回到顶点7,顶点8出栈: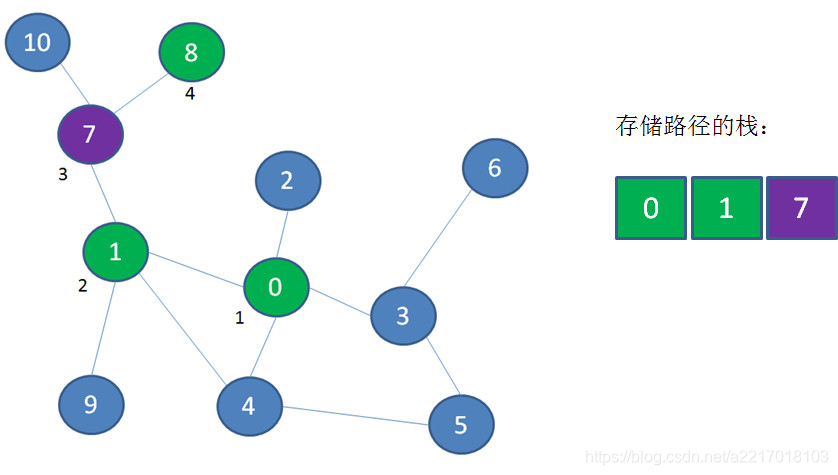
接下来访问顶点10,顶点10入栈: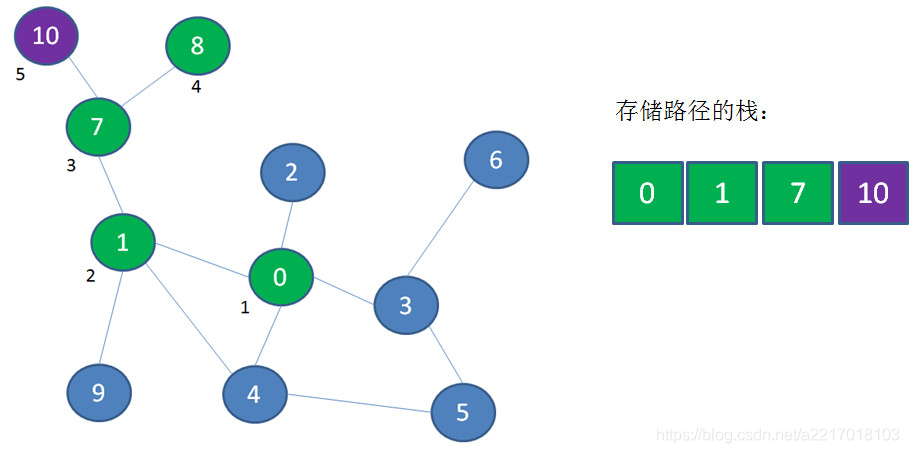
从顶点10退到顶点7,从顶点7退到顶点1,顶点10和顶点7出栈: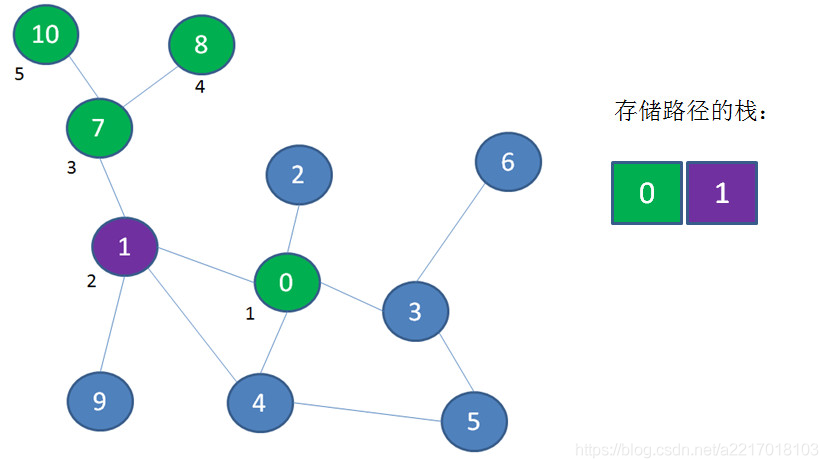
探索顶点9,顶点9入栈: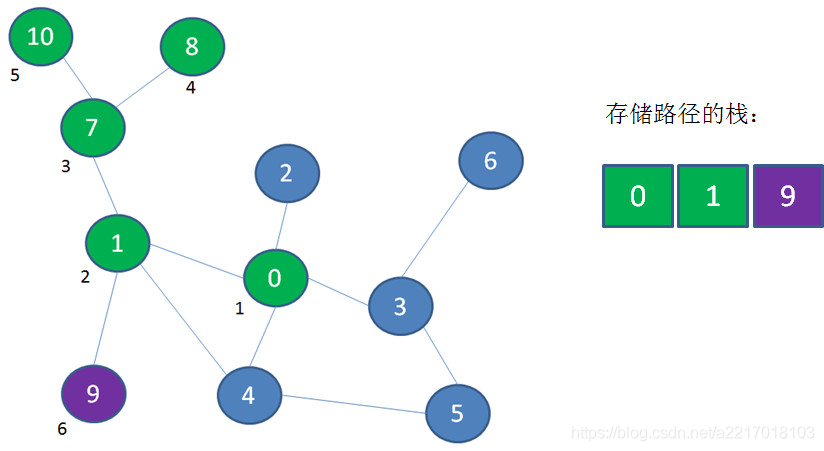
以此类推,利用这样一个临时栈来实现回溯,最终遍历完所有顶点。
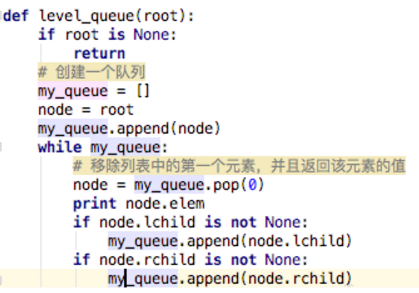
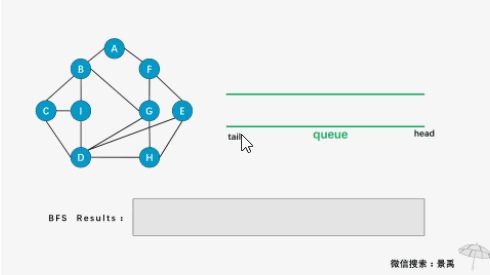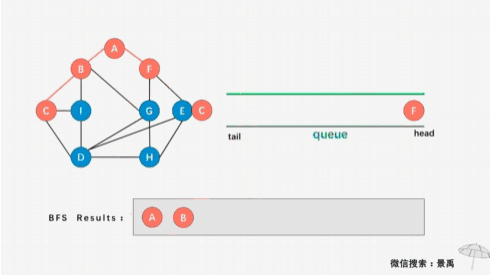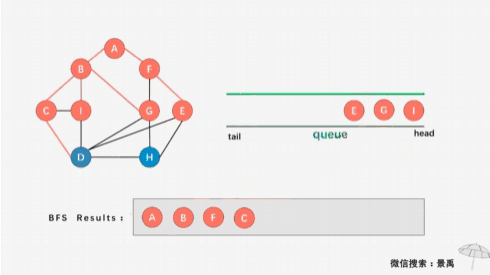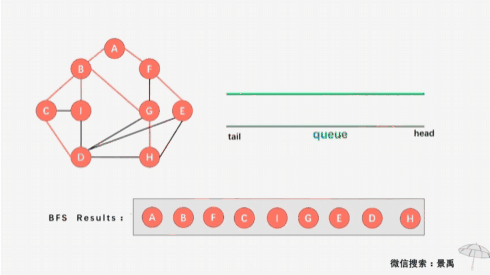
广度优先遍历:
从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点
按照广度优先遍历的思想,我们首先遍历顶点0,然后遍历了邻近顶点1、2、3、4:
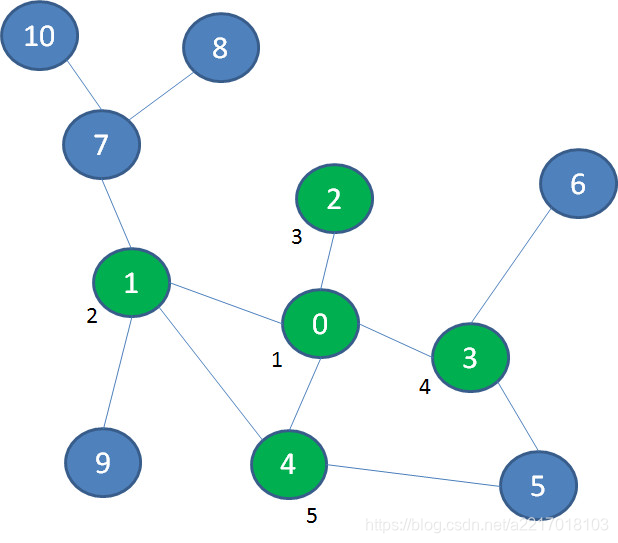
接下来我们要遍历更外围的顶点,可是如何找到这些更外围的顶点呢?我们需要把刚才遍历过的顶点1、2、3、4按顺序重新回顾一遍,从顶点1发现邻近的顶点7、9;从顶点3发现邻近的顶点5、6。
像这样把遍历过的顶点按照之前的遍历顺序重新回顾,就叫做重放。同样的,要实现重放也需要额外的存储空间,可以利用队列的先入先出特性来实现。
下面我们来演示一下具体实现过程。
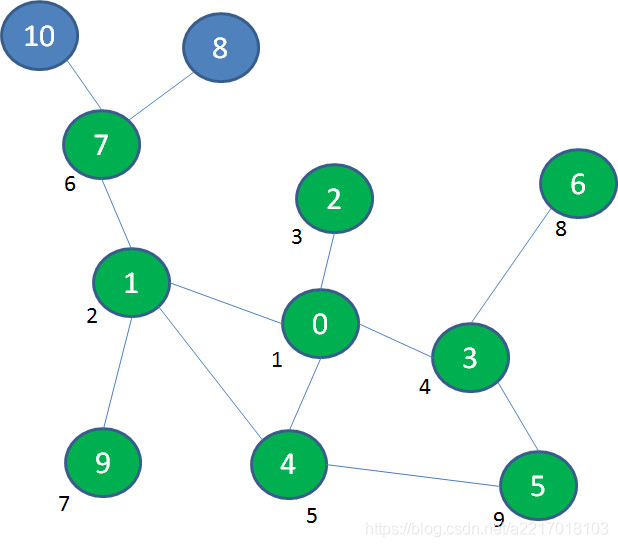
首先遍历起点顶点0,顶点0入队:
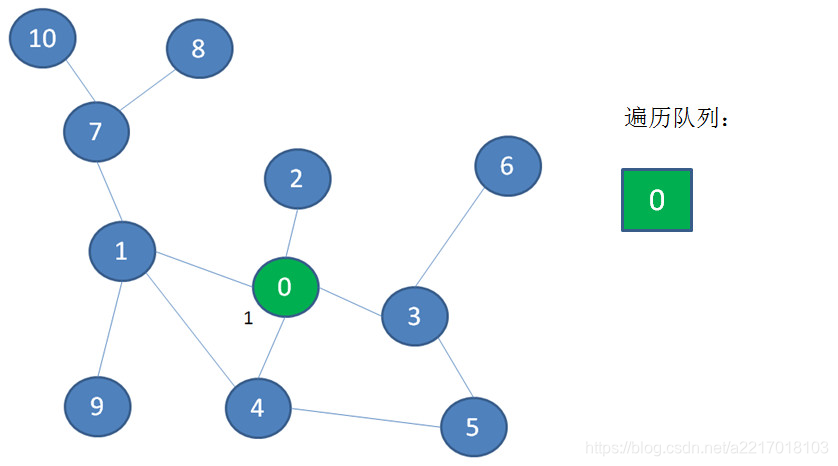
接下来顶点0出队,遍历顶点0的邻近顶点1、2、3、4,并且把它们入队:

然后顶点1出队,遍历顶点1的邻近顶点7、9,并且把它们入队:
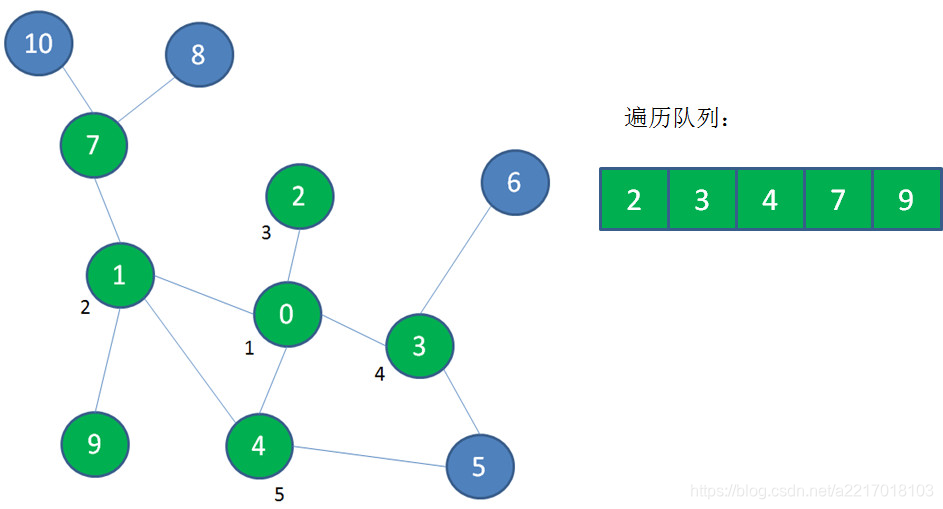
然后顶点2出队,没有新的顶点可入队:

以此类推,利用这样一个队列来实现重放,最终遍历完所有顶点。
参考资料:
(25条消息) 深度优先遍历和广度优先遍历_a2217018103的博客-CSDN博客_广度优先遍历和深度优先遍历![]() https://blog.csdn.net/a2217018103/article/details/90678830
https://blog.csdn.net/a2217018103/article/details/90678830
算法:深度优先遍历和广度优先遍历_OceanStar的学习笔记的博客-CSDN博客_深度优先遍历和广度优先遍历什么是深度、广度优先遍历深度优先遍历简称DFS(Depth First Search),广度优先遍历简称BFS(Breadth First Search),它们是遍历图当中所有顶点的两种方式。这两种遍历方式有什么不同呢?举个例子。我们来到一个游乐场,游乐场里有11个景点。我们从景点0开始,要玩遍游乐场的所有景点,可以有什么样的游玩次序呢?第一种是一头扎到底的玩法。我们选择一条支路,尽可能不断地深入,如果遇到死路就往回退,回退过程中如果遇到没探索过的支路,就进入该支路继续深入。在图中,我们首先选择https://blog.csdn.net/zhizhengguan/article/details/122468043