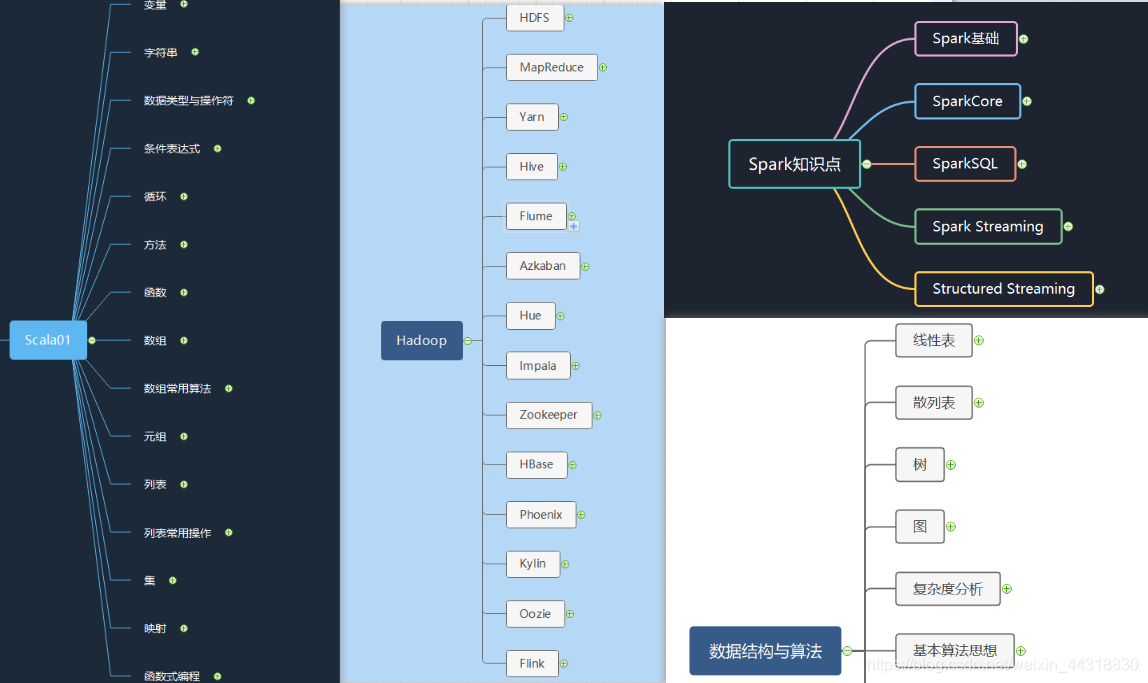
Spark
什么是Spark
基于内存的,用于大规模数据处理(离线计算、实时计算、快速查询(交互式查询))的统一分析引擎。
Spark特点
快:
Spark计算速度是MapReduce计算速度的10-100倍
易用:(算法多)
MR支持1种计算模型,Spsark支持更多的计算模型。
通用:
Spark 能够进行离线计算、交互式查询(快速查询)、实时计算、机器学习、图计算等
兼容性:
Spark支持大数据中的Yarn调度,支持mesos。可以处理hadoop计算的数据。
Spark运行模式
- local本地模式(单机)–开发测试使用
- standalone独立集群模式–开发测试使用
- standalone-HA高可用模式–生产环境使用
- on yarn集群模式–生产环境使用
- on cloud集群模式–中小公司未来会更多的使用云服务
Spark编写代码
- 创建一个 Sparkconf对象,设置app名称
- 创建一个SparkContext,
- 读取数据,对数据进行计算
- 保存数据
Spark概念
- Application:指的是用户编写的Spark应用程序/代码,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
- Driver:Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等
- Cluster Manager:指的是在集群上获取资源的外部服务,Standalone模式下由Master负责,Yarn模式下ResourceManager负责;
- Executor:是运行在工作节点Worker上的进程,负责运行任务,并为应用程序存储数据,是执行分区计算任务的进程;
- RDD:Resilient Distributed Dataset弹性分布式数据集,是分布式内存的一个抽象概念;
- DAG:Directed Acyclic Graph有向无环图,反映RDD之间的依赖关系和执行流程;
- Job:作业,按照DAG执行就是一个作业;Job==DAG
- Stage:阶段,是作业的基本调度单位,同一个Stage中的Task可以并行执行,多个Task组成TaskSet任务集
- Task:任务,运行在Executor上的工作单元,一个Task计算一个分区,包括pipline上的一系列操作
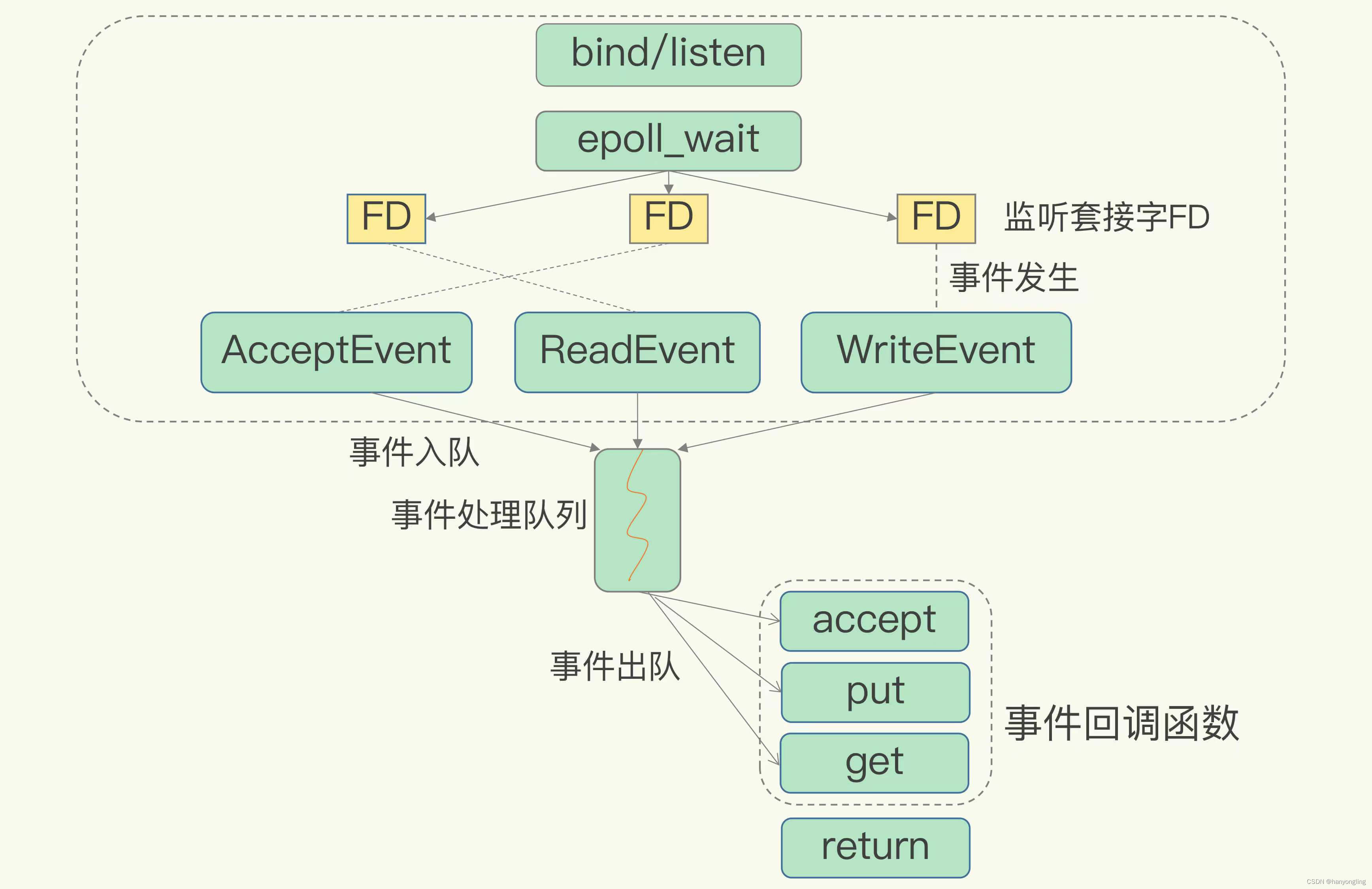
Spark执行任务的基本流程
- Spark应用被提交–>SparkContext向资源管理器注册并申请资源 (??) -->启动Executor
- RDD–>构建DAG–>DAGScheduler划分Stage形成TaskSet–>TaskScheduler提交Task–>Worker上的Executor执行Task
SparkCore
什么是RDD
弹性分布式数据集(数据存储在内存),一个不可变、可分区、里面的元素可并行计算的集合
RDD的主要属性
- 数据集的基本组成单位是一组分片(Partition)或一个分区(Partition)列表
每个分片都会被一个计算任务处理,分片数决定并行度。 - 一个函数会被作用在每一个分区。
- 一个RDD会依赖于其他多个RDD,RDD的每次转换都会生成一个新的RDD
RDD的算子分为两类:
- 对多次使用的rdd进行缓存,缓存到内存,当后续频繁使用时直接在内存中读取缓存的数据,不需要重新计算。 (Persist、Cache)
- 将RDD结果写入硬盘(容错机制),当RDD丢失数据时,或依赖的RDD丢失数据时,可以使用持久化到硬盘的数据恢复。
(MEMORY_ONLY(默认)、MEMORY_AND_DISK、DISK_ONLY)
SparkContext.setCheckpointDir(“目录”) //HDFS的目录
RDD.checkpoint()
cache和Checkpoint的区别
位置:
- Persist 和 Cache将数据保存在内存
- Checkpoint将数据保存在HDFS
生命周期: - Persist 和 Cache 程序结束后会被清除或手动调用unpersist方法。
- Checkpoint永久存储不会被删除。
RDD依赖关系(血统Lineage): - Persist和Cache,不会丢掉RDD间的依赖链/依赖关系
- Checkpoint会斩断依赖链
什么是宽窄依赖
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
什么是DAG
DAG:指的是数据转换执行的过程,有方向,无闭环(其实就是RDD执行的流程)
DAG边界
开始:通过SparkContext创建的RDD
结束:触发Action,一旦触发Action就形成了一个完整的DAG
说明:
- 一个Spark应用中可以有一到多个DAG,取决于触发了多少次Action
- 一个DAG中会有不同的阶段/stage,划分阶段/stage的依据就是宽依赖
- 一个阶段/stage中可以有多个Task,一个分区对应一个Task
累加器的作用
累加器accumulators:累加器支持在所有不同节点之间进行累加计算
广播变量的作用
在每个机器上缓存一份、不可变的、只读的、相同的变量,该节点每个任务都能访问。起到节省资源的作用,和优化的所用。
SparkSQL基本介绍
什么是SparkSQL?
用于处理结构化数据的Spark模块。
SparkSQL底层的数据抽象
DataFrame和DataSet
Hive和SparkSQL的对比
- Hive是将sql转化成MapReduce进行计算(降低学习成本、提高开发效率)
- SparkSQL是将sql转化成rdd集进行计算(降低学习成本、提高开发效率)
什么是DataFrame??
DataFrame是以RDD为基础的带有Schema元信息的分布式数据集。

什么是DataSet??
- 含有类型信息的DataFrame就是DataSet
(DataSaet=DataFrame+类型= Schema+RDD*n+类型)
SparkSQL查询数据的形态
- 类似方法调用,领域特定语言(DSL)。
personDF.select( " i d " , "id", "id",“name”, " a g e " + 1 ) . f i l t e r ( "age"+1).filter( "age"+1).filter(“age”>25).show - SQL语句
spark.sql(“select * from personDFT where age >25”).show
添加Schema的方式
第1种:指定列名添加Schema
第2种:通过StructType指定Schema
第3种:编写样例类,利用反射机制推断Schema
指定列名添加Schema代码流程
- 创建sparksession
- 创建sc
- 读取数据并加工
- 设置表结构 ttRDD.toDF(“id”,“name”,“age”)
- 注册成表并查询
- 关闭sc sparksession
通过StructType指定Schema代码流程
- 创建sparksession
- 创建sc
- 读取数据并加工
- 设置表结构
types.StructType(
// 字段类型 (字段名,字段类型,是否为空)
List(StructField(“id”,IntegerType,true)
)
) - 创建DS DF
val ttDF: DataFrame = spark.createDataFrame(RowRDD,structTable) - 注册成表并查询
- 关闭sc sparksession
利用反射机制推断Schema代码流程
准备样例类
- 创建sparksession
- 创建sc
- 读取数据并加工
val PersonRDD: RDD[Person] = ttRDD.map(z=>Person(z(0).toInt,z(1),z(2).toInt)) - RDD转DF
val personDF: DataFrame = PersonRDD.toDF() - 注册成表并查询
- 关闭sc sparksession
RDD、DF、DS三者之间的转化
- 转换成RDD .rdd
- 转换成DF .toDF()
- 转换成DS
- RDD->DS .toDS()
- DF->DS .as[Person]
Spark SQL自定义函数
spark.udf.register(“toUpperAdd123”,(str:String)=>{
//根据业务逻辑对数据进行处理
//str.toUpperCase()+ " 123"
//str.length10
str.length10/2/2.toDouble
})
开窗函数的作用
既显示聚集前/排序前的原始的数据,又显示聚集后/排序后的名次 的数据。
开窗函数的分类
- 聚和开窗函数
聚合函数(列) OVER(选项),这里的选项可以是PARTITION BY 子句 - 排序聚和函数
排序函数(列) OVER(选项),这里的选项可以是ORDER BY 子句,也可以是 OVER(PARTITION BY 子句 ORDER BY 子句)
聚和开窗函数
select name, class, score, count(name) over() name_count from scores
select name, class, score, count(name) over(PARTITION BY class) name_count from scores
排序聚和函数
select name, class, score, row_number() over(order by score) rank from scores
select name, class, score, row_number() over(partition by class order by score) rank from scores
RANK跳跃排序
select name, class, score, rank() over(order by score) rank from scores
select name, class, score, rank() over(partition by class order by score) rank from scores
DENSE_RANK连续排序
select name, class, score, dense_rank() over(order by score) rank from scores
NTILE分组排名
select name, class, score, ntile(6) over(order by score) rank from scores
Spark Streaming
什么是Spark Streaming
Spark Streaming是一个基于Spark Core之上的实时计算框架
什么是DStream
代表持续性的输入的数据流和经过各种Spark算子操作后的输出的结果数据流。
本质上就是按照时间间隔划分成一批一批的连续的RDD
阐明RDD、DataFrame、DataSet、DStream数据抽象之间的关系。
DStream=RDD1(t1)+ RDD2(t2)+ RDD3(t3)+ RDD4(t4)+….
DataSet = DataFrame+类型 = RDD+结构+类型
DataFrame = RDD+结构
SparkStreaming代码过程
- 创建sparkConf
- 创建一个sparkcontext
- 创建streamingcontext
- 接收数据并根据业务逻辑进行计算
- 开启计算任务
- 等待关闭
窗口宽度和滑动距离的关系

0.8版本SparkStreaming集成kafka是的差异
Receiver接收方式
- 多个Receiver接受数据效率高,但有丢失数据的风险。
- 开启日志(WAL)可防止数据丢失,但写两遍数据效率低。
- Zookeeper维护offset有重复消费数据可能。
- 使用高层次的API
Direct直连方式
- 不使用Receiver,直接到kafka分区中读取数据
- 不使用日志(WAL)机制。
- Spark自己维护offset
- 使用低层次的API
Structured Streaming
什么是Structured Streaming
Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎
Structured Streaming模型
是一个不断增长的动态表格,新数据被持续不断地添加到表格的末尾
对动态数据源进行实时查询,就是对当前的表格内容执行一次 SQL 查询。
Structured Streaming应用场景
将数据源映射为类似于关系数据库中的表,(SparkSQL中的DF/DS)
然后将经过计算得到的结果映射为另一张表.
详细描述下图内容

如图所示:
- 第一行表示从socket不断接收数据,
- 第二行可以看成是之前提到的“unbound table",
- 第三行为最终的wordCounts是结果集。
当有新的数据到达时,Spark会执行“增量"查询,并更新结果集;
该示例设置为Complete Mode(输出所有数据),因此每次都将所有数据输出到控制台;
在第1秒时,此时到达的数据为"cat dog"和"dog dog",因此我们可以得到第1秒时的结果集cat=1 dog=3,并输出到控制台;
当第2秒时,到达的数据为"owl cat",此时"unbound table"增加了一行数据"owl cat",执行word count查询并更新结果集,可得第2秒时的结果集为cat=2 dog=3 owl=1,并输出到控制台;
当第3秒时,到达的数据为"dog"和"owl",此时"unbound table"增加两行数据"dog"和"owl",执行word count查询并更新结果集,可得第3秒时的结果集为cat=2 dog=4 owl=2;