来源:AI科技评论
摘要:如何赋予机器自主学习的能力,一直是人工智能领域的研究热点。
强化学习与宽度学习
如何赋予机器自主学习的能力,一直是人工智能领域的研究热点。在越来越多的复杂现实场景任务中,需要利用深度学习、宽度学习来自动学习大规模输入数据的抽象表征,并以此表征为依据进行自我激励的强化学习,优化解决问题的策略。深度与宽度强化学习技术在游戏、机器人控制、参数优化、机器视觉等领域中的成功应用,使其被认为是迈向通用人工智能的重要途径。
澳门大学讲座教授,中国自动化学会副理事长陈俊龙在中国自动化学会第5期智能自动化学科前沿讲习班作了题目为「从深度强化学习到宽度强化学习:结构,算法,机遇及挑战」的报告。
陈俊龙教授的报告大致可以分为三个部分。首先讨论了强化学习的结构及理论,包括马尔科夫决策过程、强化学习的数学表达式、策略的构建、估计及预测未来的回报。然后讨论了如何用深度神经网络学习来稳定学习过程及特征提取、如何利用宽度学习结构跟强化学习结合。最后讨论了深度、宽度强化学习带来的机遇与挑战。
强化学习结构与理论
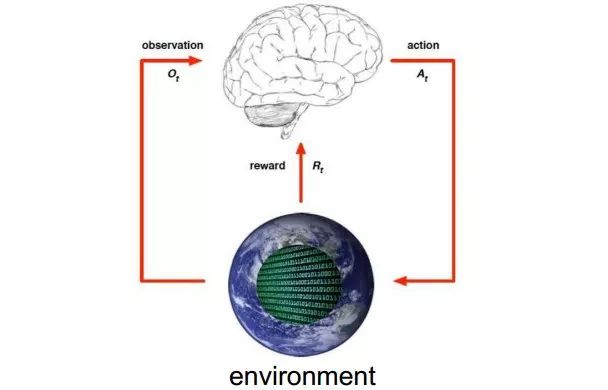
陈教授用下图简单描述强化学习过程。他介绍道所谓强化学习就是智能体在完成某项任务时,通过动作A与环境(environment)进行交互,在动作A和环境的作用下,智能体会产生新的状态,同时环境会给出一个立即回报。如此循环下去,经过数次迭代学习后,智能体能最终地学到完成相应任务的最优动作。
提到强化学习就不得不提一下Q-Learning。接着他又用了一个例子来介绍了强化学习Q-Learning的原理。
Q-learning
原文地址:
https://blog.csdn.net/Maggie_zhangxin/article/details/73481417
假设一个楼层共有5个房间,房间之间通过一道门连接,如下图所示。房间编号为0~4,楼层外的可以看作是一个大房间,编号5。
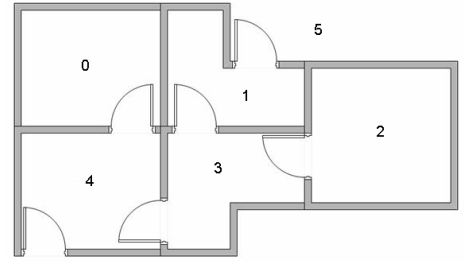
可以用图来表示上述的房间,将每一个房间看作是一个节点,每道门看作是一条边。
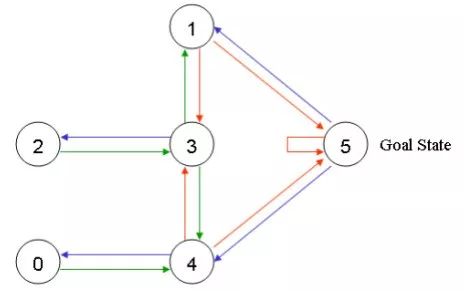
在任意一个房间里面放置一个智能体,并希望它能走出这栋楼,也可以理解为进入房间5。可以把进入房间5作为最后的目标,并为可以直接到达目标房间的门赋予100的奖励值,那些未与目标房间相连的门则赋予奖励值0。于是可以得到如下的图。
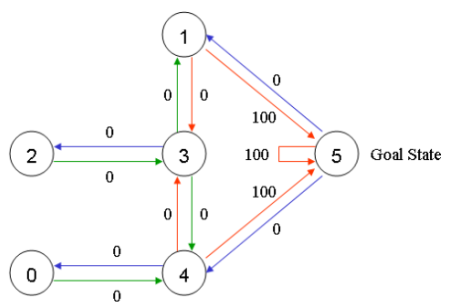
根据上图可以得到奖励表如下,其中-1代表着空值,表示节点之间无边相连。
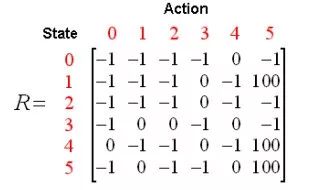
再添加一个类似的Q矩阵,代表智能体从经验中所学到的知识。矩阵的行代表智能体当前的状态,列代表到达下一状态的可能动作。

然后陈教授又介绍了Q-Learning的转换规则,即Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])。
依据这个公式,矩阵Q中的一个元素值就等于矩阵R中相应元素的值与学习变量Gamma乘以到达下一个状态的所有可能动作的最大奖励值的总和。
为了具体理解Q-Learning是怎样工作的,陈教授还举了少量的例子。
首先设置Gamma为0.8,初始状态是房间1。
对状态1来说,存在两个可能的动作:到达状态3,或者到达状态5。通过随机选择,选择到达状态5。智能体到达了状态5,将会发生什么?观察R矩阵的第六行,有3个可能的动作,到达状态1,4或者5。根据公式Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100,由于矩阵Q此时依然被初始化为0,Q(5, 1), Q(5, 4), Q(5, 5) 全部是0,因此,Q(1, 5) 的结果是100,因为即时奖励R(1,5) 等于100。下一个状态5现在变成了当前状态,因为状态5是目标状态,故算作完成了一次尝试。智能体的大脑中现在包含了一个更新后的Q矩阵。

对于下一次训练,随机选择状态3作为初始状态。观察R矩阵的第4行,有3个可能的动作,到达状态1,2和4。随机选择到达状态1作为当前状态的动作。现在,观察矩阵R的第2行,具有2个可能的动作:到达状态3或者状态5。现在计算Q 值:Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 2), Q(1, 5)] = 0 + 0.8 *Max(0, 100) = 80,使用上一次尝试中更新的矩阵Q得到:Q(1, 3) = 0 以及 Q(1, 5) = 100。因此,计算的结果是Q(3,1)=80。现在,矩阵Q如下。

智能体通过多次经历学到更多的知识之后,Q矩阵中的值会达到收敛状态。如下。

通过对Q中的所有的非零值缩小一定的百分比,可以对其进行标准化,结果如下。
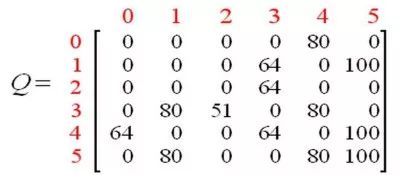
一旦矩阵Q接近收敛状态,我们就知道智能体已经学习到了到达目标状态的最佳路径。
至此陈教授已经把Q-learning简单介绍完了。通过上文的介绍大致可以总结出强化学习的六个特点:
无监督,只有奖励信号
不需要指导学习者
不停的试错
奖励可能延迟(牺牲短期收益换取更大的长期收益)
需要探索和开拓
目标导向的智能体与不确定的环境间的交互是个全局性的问题
四个要素:
一、策略:做什么?
1)确定策略:a=π(s)
2)随机策略:π(a|s)=p[at=a|st=s],st∈S,at∈A(St),∑π(a|s)=1
二、奖励函数:r(在状态转移的同时,环境会反馈给智能体一个奖励)
三、累积奖励函数:V(一个策略的优劣取决于长期执行这一策略后的累积奖励),常见的长期累积奖励如下:
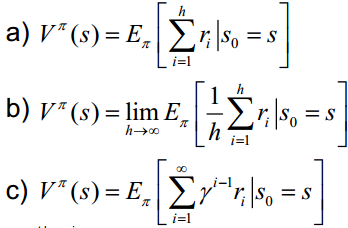
四、模型:用于表示智能体所处环境,是一个抽象概念,对于行动决策十分有用。
所有的强化学习任务都是马尔科夫决策过程,陈教授对MDP的介绍如下。

一个马尔可夫决策过程由一个五元组构成M =(S,A,p,γ,r)。其中S是状态集,A是动作集,p是状态转移概率,γ是折扣因子,r是奖励函数。
陈教授在介绍强化学习这部分的最后提到了目前强化学习面临的两大挑战。
信度分配:之前的动作会影响当前的奖励以及全局奖励
探索开拓:使用已有策略还是开发新策略
Q-Learning可以解决信度分配的问题。第二个问题则可以使用ε-greedy算法,SoftMax算法,Bayes bandit算法,UCB算法来处理等。
值函数(对未来奖励的一个预测)可分为状态值函数和行为值函数。
1. 状态值函数 Vπ(s):从状态s出发,按照策略π采取行为得到的期望回报,
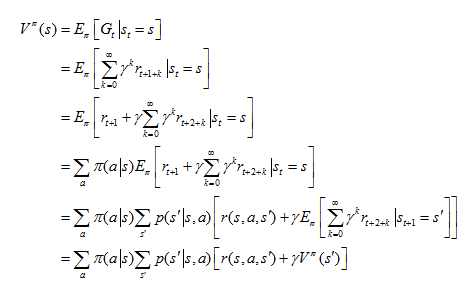
也被称为Bellman方程。
2. 行为价值函数Qπ(s,a):从状态s出发采取行为a后,然后按照策略π采取行动得到的期望回报,
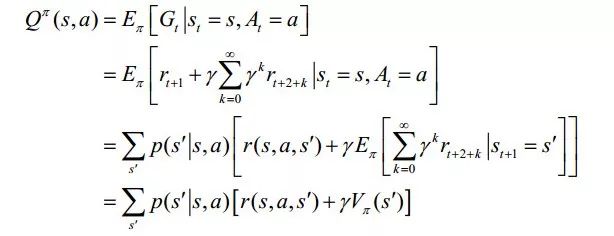
同样被称为动作‐值函数的Bellman方程。
类似的给出了相应的最优值函数为:
1. 最优值函数V*(s)是所有策略上的最大值函数:
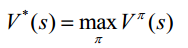
2. 最优行为值函数Q*(s,a)是在所有策略上的最大行为值函数:
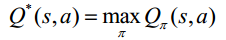
从而的到Bellman最优方程:
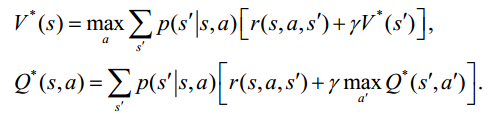
及对应的最优策略:
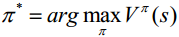
陈教授介绍了求解强化学习的方法,可分为如下两种情况:
模型已知的方法:动态规划
模型未知的方法:蒙特卡洛方法,时间差分算法
陈教授进一步主要介绍了时间差分算法中两种不同的方法: 异策略时间差分算法Q‐learning和同策略时间差分算法Sarsa, 两者的主要区别在于at+1的选择上的不同,
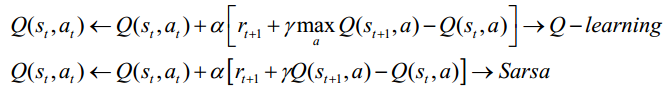
普通的Q‐learning是一种表格方法,适用于状态空间和动作空间是离散且维数比较低的情况;当状态空间和动作空间是高维连续的或者出现一个从未出现过的状态,普通的Q‐learning是无法处理的。为了解决这个问题,陈教授进一步介绍了深度强化学习方法。
深度强化学习
深度强化学习是深度神经网络与强化学习的结合方法, 利用深度神经网络逼近值函数,利用强化学习的方法进行更新,根据解决问题思路的不同可分为:
1.基于价值网络:状态作为神经网络的输入,经过神经网络分析后,输出时当前状态可能执行的所有动作的值函数,即利用神经网络生成Q值。
2.基于策略网络:状态作为神经网络的输入,经过神经网络分析后,输出的是当前状态可能采取的动作(确定性策略),或者是可能采取的每个动作的概率(随机性策略)。
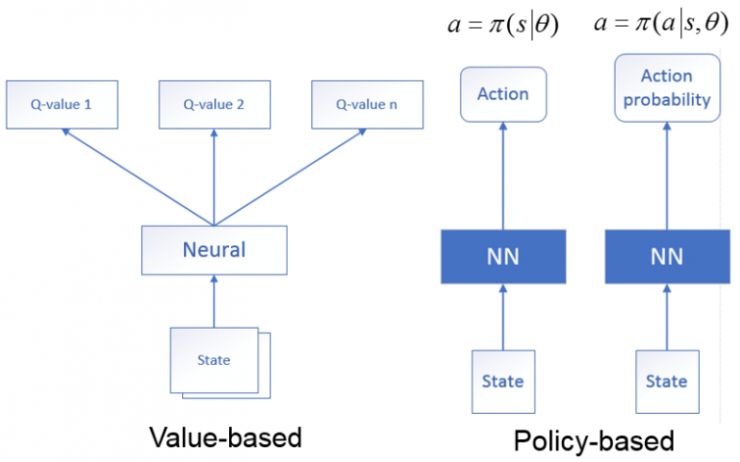
陈教授也提到了Deepmind公司在2013年的Playing Atari with Deep Reinforcement Learning (DRL) 提出的DQN算法,Deep Q‐learning是利用深度神经网络端到端的拟合Q值,采用Q‐learning算法对值函数更新。DQN利用经验回放对强化学习过程进行训练,通过设置目标网络来单独处理时间差分算法中的TD偏差。
基于上面内容,陈教授进一步介绍了另外一种经典的时间差分算法,即Actor-Critic的方法,该方法结合了值函数(比如Q learning)和策略搜索算法(Policy Gradients)的优点,其中Actor指策略搜索算法,Critic指Qlearning或者其他的以值为基础的学习方法,因为Critic是一个以值为基础的学习法,所以可以进行单步更新,计算每一步的奖惩值,与传统的PolicyGradients相比提高了学习效率,策略结构Actor,主要用于选择动作;而值函数结构Critic主要是用于评价Actor的动作,agent根据Actor的策略来选择动作,并将该动作作用于环境,Critic则根据环境给予的立即奖赏,根据该立即奖赏来更新值函数,并同时计算值函数的时间差分误差TD-error,通过将TDerror反馈给行动者actor,指导actor对策略进行更好的更新,从而使得较优动作的选择概率增加,而较差动作的选择概率减小。
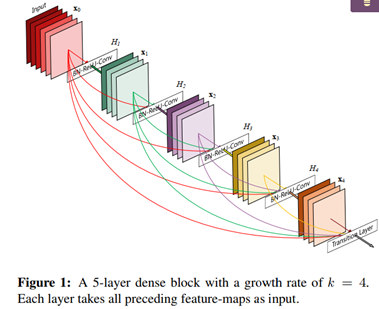
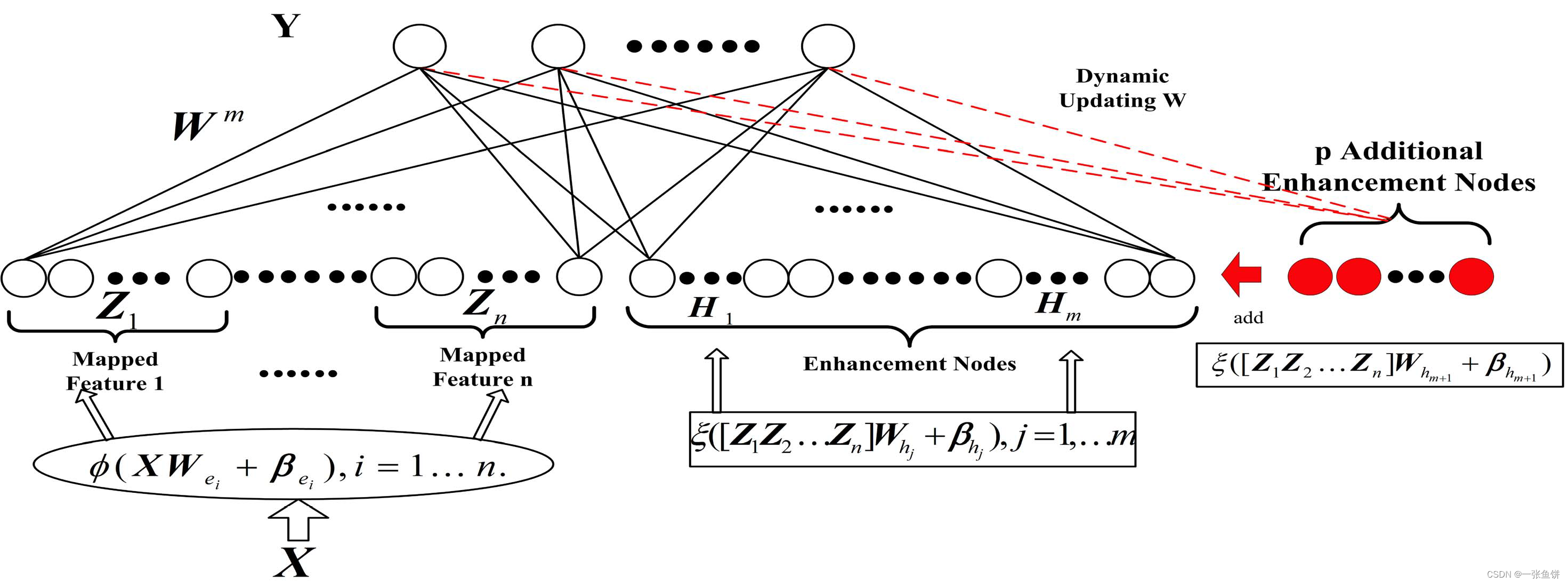
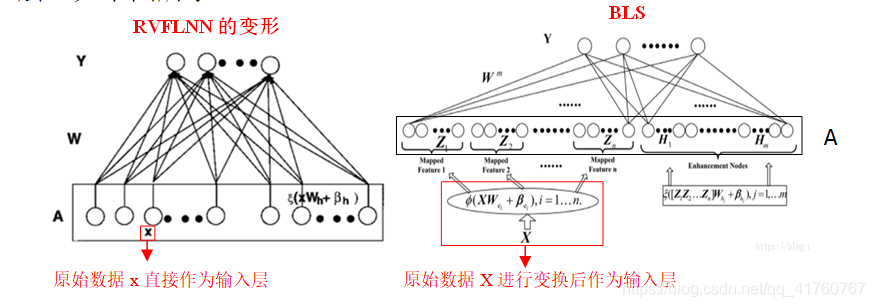
宽度学习
虽然深度结构网络非常强大,但大多数网络都被极度耗时的训练过程所困扰。首先深度网络的结构复杂并且涉及到大量的超参数。另外,这种复杂性使得在理论上分析深层结构变得极其困难。另一方面,为了在应用中获得更高的精度,深度模型不得不持续地增加网络层数或者调整参数个数。因此,为了提高训练速度,宽度学习系统提供了一种深度学习网络的替代方法,同时,如果网络需要扩展,模型可以通过增量学习高效重建。陈教授还强调,在提高准确率方面,宽度学习是增加节点而不是增加层数。基于强化学习的高效性,陈教授指出可以将宽度学习与强化学习结合产生宽度强化学习方法,同样也可以尝试应用于文本生成、机械臂抓取、轨迹跟踪控制等领域。
报告的最后陈教授在强化学习未来会面临的挑战中提到了如下几点:
安全有效的探索
过拟合问题
多任务学习问题
奖励函数的选择问题
不稳定性问题
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”