最近在拜读陈院士的宽度学习论文,受益匪浅,在此先感谢陈院士团队的开源代码!
在复现代码的过程中,发现了一些小问题,在此记录,方便自己日后翻阅。
此博客仅代表个人观点,姑且算作个人读书笔记。
[1] C. L. P. Chen and Z. Liu, “Broad Learning System: An effective and efficient incremental learning system without the need for deep architecture,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 1, pp. 10–24, Jan. 2018.
[2] C. L. P. Chen, Z. Liu, and S. Feng, “Universal approximation capability of broad learning system and its structural variations, IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 4, pp. 1191–1204, Apr. 2019.
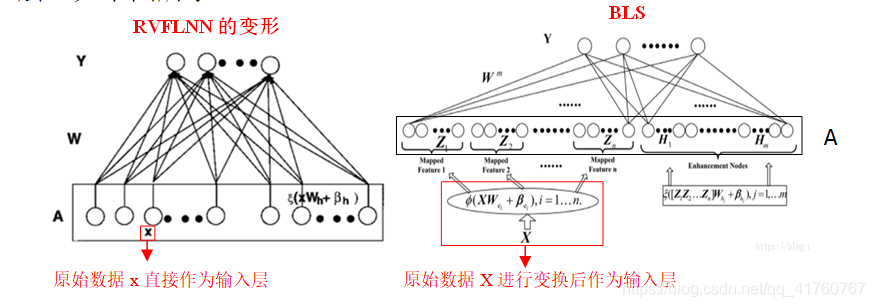
陈院士团队的开源代码中包含了3种宽度学习框架:(所有图都来自论文[1])
1. 最原始的宽度学习
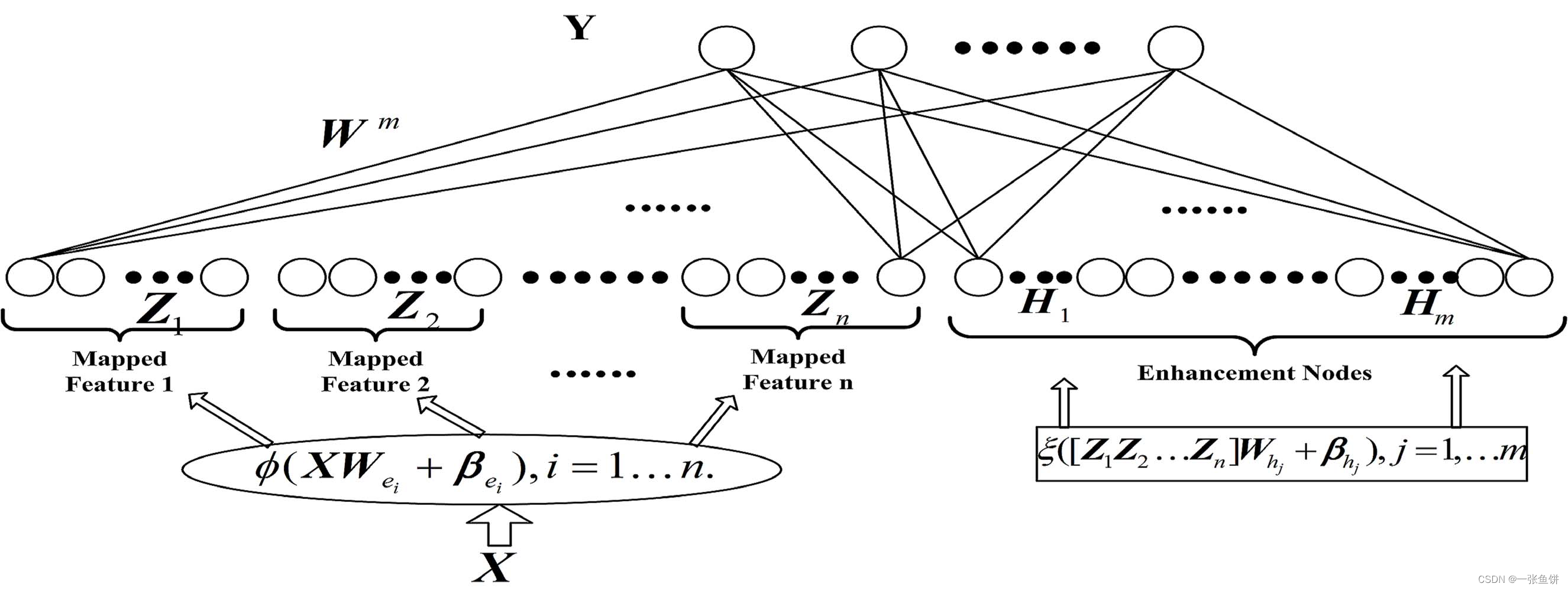
2. 增加强化节点的宽度学习
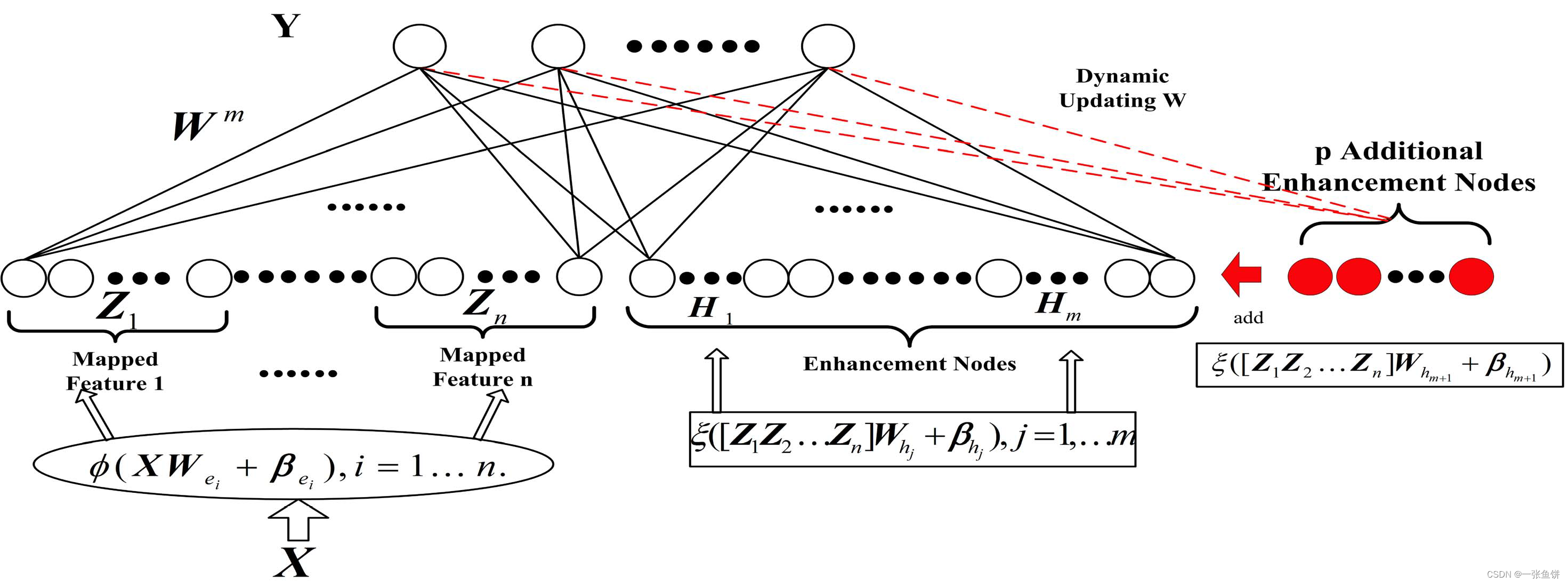
3. 增加特征映射节点和强化节点的宽度学习
其中出现问题的代码为第三种(python版本),问题记录如下
在生成特征映射节点的过程中
for i in range(N2):random.seed(i+u)weightOfEachWindow = 2 * random.randn(train_x.shape[1]+1,N1)-1FeatureOfEachWindow = np.dot(FeatureOfInputDataWithBias,weightOfEachWindow) scaler1 = preprocessing.MinMaxScaler(feature_range=(-1, 1)).fit(FeatureOfEachWindow)FeatureOfEachWindowAfterPreprocess = scaler1.transform(FeatureOfEachWindow)betaOfEachWindow = sparse_bls(FeatureOfEachWindowAfterPreprocess,FeatureOfInputDataWithBias).TBeta1OfEachWindow.append(betaOfEachWindow)outputOfEachWindow = np.dot(FeatureOfInputDataWithBias,betaOfEachWindow)distOfMaxAndMin.append(np.max(outputOfEachWindow,axis = 0) - np.min(outputOfEachWindow,axis = 0))minOfEachWindow.append(np.mean(outputOfEachWindow,axis = 0))outputOfEachWindow = (outputOfEachWindow-minOfEachWindow[i])/distOfMaxAndMin[i]OutputOfFeatureMappingLayer[:,N1*i:N1*(i+1)] = outputOfEachWindowdel outputOfEachWindow del FeatureOfEachWindow del weightOfEachWindow 在第5行中, MinMax归一化应将特征归一化到[0,1]的空间中,应修改为:
scaler1 = preprocessing.MinMaxScaler(feature_range=(0, 1)).fit(FeatureOfEachWindow)在第11行中,取最小值应使用np.min()函数,应修改为
minOfEachWindow.append(np.min(outputOfEachWindow,axis = 0))与之对应的,在增加特征映射节点和强化节点的代码段中,也存在上述问题,源代码为:
'''增加Mapping 和 强化节点'''WeightOfNewFeature2 = list()WeightOfNewFeature3 = list()for e in list(range(L)):time_start = time.time()random.seed(e+N2+u)weightOfNewMapping = 2 * random.random([train_x.shape[1]+1,M1]) - 1NewMappingOutput = FeatureOfInputDataWithBias.dot(weightOfNewMapping)scaler2 = preprocessing.MinMaxScaler(feature_range=(-1, 1)).fit(NewMappingOutput)FeatureOfEachWindowAfterPreprocess = scaler2.transform(NewMappingOutput)betaOfNewWindow = sparse_bls(FeatureOfEachWindowAfterPreprocess,FeatureOfInputDataWithBias).TBeta1OfEachWindow.append(betaOfNewWindow)TempOfFeatureOutput = FeatureOfInputDataWithBias.dot(betaOfNewWindow)distOfMaxAndMin.append( np.max(TempOfFeatureOutput,axis = 0) - np.min(TempOfFeatureOutput,axis = 0))minOfEachWindow.append(np.mean(TempOfFeatureOutput,axis = 0))outputOfNewWindow = (TempOfFeatureOutput-minOfEachWindow[N2+e])/distOfMaxAndMin[N2+e]OutputOfFeatureMappingLayer = np.hstack([OutputOfFeatureMappingLayer,outputOfNewWindow])NewInputOfEnhanceLayerWithBias = np.hstack([outputOfNewWindow, 0.1 * np.ones((outputOfNewWindow.shape[0],1))])其中scaler2与minOfEachWindow两行应修改为
# scaler2
scaler2 = preprocessing.MinMaxScaler(feature_range=(0, 1)).fit(NewMappingOutput)
# minOfEachWindow
minOfEachWindow.append(np.min(TempOfFeatureOutput,axis = 0))