一、语义相似检索背景
1、为什么引入语义相似检索(向量检索)
问题引出: 搜索引擎和搜索广告最难解决的问题是语义相似度
具体体现:召回和排序。
Case1: 如"从北京到上海的机票"与"携程网"的相似性
Case2"快递软件"与"菜鸟裹裹"的相似性
2、语义相似度==向量检索?
语义相似度包含:
- 深度学习模型
- 向量检索工程化实现
3、补充关键字召回率(倒排拉链截断)
- 关键字召回可能存在拉链后面的长期得不到召回
- 相关性强依赖Rwt模块分词的关键词匹配
4、 语义相似度的关键点
(1).深度学习模型
DSSM (Deep Structured Semantic Models)
CNN-DSSM(CLSM convolutional latent semantic model /CNN-DSSM)
LSTM-DSSM(Long-Short-Term Memory)
(2) 向量工程化实现
- Faiss:索引库
- Annoy: 树模型
- HNSW: 紧密图
- Milvus 服务引擎
- Vearch京东服务引擎
- 阿里NSG

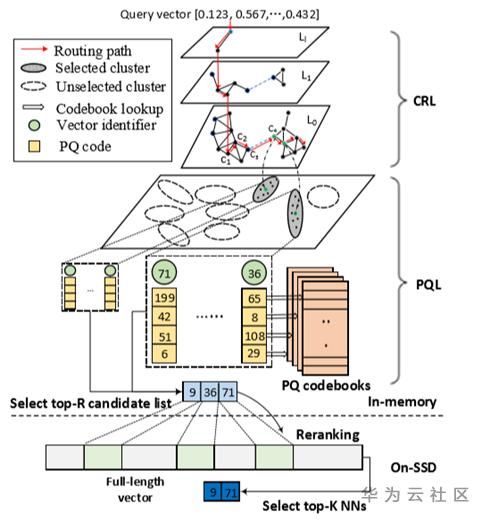
5、 Faiss索引库
向量索引需要解决的问题:
- 高维向量距离计算
- 高维向量的内存存储
名词解释:
- 查询向量:用户的查询向量
- 聚类中心向量(中心向量):在向量集合中训练出来的聚类向量,其实也是向量集合中的点
- 样本向量: 聚类中心倒排拉链的向量集合
- SDC(symmetric distance computation) 对称求距离
- ADC(asymmetric distance computation) 非对称求距离
举例: d = 128维向量, 向量维度值 float 4个字节
3000w向量 3000*10000*128*4 = 14G内存(目前似乎我们不压缩也可以)
d = 512维向量56G内存
乘积量化(Product Quantization)
量化:指的就是将一个空间划分为多个区域,然后为每个区域编码标识
乘积:指的是高维空间可以看作是由多个低维空间相乘得到的
举例:
(1)假设1024维度的向量;分4段,每段256维,比如A,B,C,D;
(2)每段256维,针对每段使用256个聚类中心编号
(3)每个聚类中心向量是256维的浮点数,256 * 4 =1024个字节
(4)一共有256 * 4 = 1024个聚类中心向量
因此,一个 1024 维的原始浮点数向量(共 1024 * 4 字节)使用乘积量化压缩后,存储空间变为了 32 个比特位
二、faiss索引库&向量化落地
1、Faiss从典型Case说起
Case: IndexIVFPQ + IndexFlatL2

2、Faiss索引库训练

(1)首先构造一级量化器(粗糙量化器)
faiss::IndexFlatL2 coarse_quantizer (d);默认构造的是L2距离;
目的:是为了把向量空间的向量第一次分堆,在查询的时候能够根据到中心点距离迅速过滤掉大部分向量,加速查询,一级量化器目前测试发现最快的是HNSW索引图方式搜索。
(2)构造二级量化器
faiss::IndexIVFPQ index (&coarse_quantizer, d, ncentroids, 4, 8);
目的:是为了查询聚类中心的向量,返回topk;二级量化器传入的一个一级量化器,一级量化器的目的是在查询的时候快速定位的聚类中心,查询的时候也是先查询一级量化器,再查询二级量化器。
(3)数据集问题
在训练量化器之前,需要构建一个向量集合,以1500w向量为例,比如128维,需要申请内存1500*10000*128*4 = 7324M,大概需要7G内存;注意我们插入向量的顺序就是召回向量的id,这个是一一对应的;
目前训练的时候是全部放内存的需要,所以需要提前计算好向量的维度,向量的数量,需要的机器内存大小等;
3、Faiss 一级量化器训练
(1) 首先构造一级量化器(粗糙量化器)
入口函数Level1Quantizer::train_q1 (…)

- K是聚类中心的数量,常规设置总向量的平方根
- max_points_per_centroid 255默认值
(2) Faiss 二级量化器训练
入口函数IndexIVFPQ::train_residual (idx_t n, const float *x)

assign返回的是n个聚类中心向量,里面可以有重复的中心向量残差可以看做是以一级量化器的为中心点的坐标系下各个向量表示,
如下图:

(3)Faiss 二级量化器计算残差
计算残差就是向量的各个维度和距离中心的差值

(4) Faiss索引写磁盘
数据下盘void write_index (const Index *idx, IOWriter *writer);
先写IndexIVFPQ * ivpq这种类型的索引,在write_ivf_header函数循环调用写了一级量化器的索引

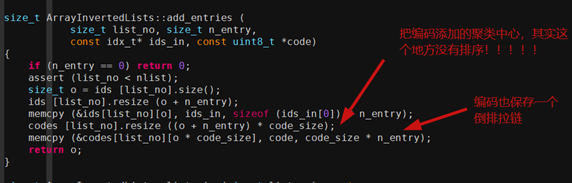
4、Faiss向量的add流程
Faiss Add流程其实是把向量集合添加到向量中心的倒排拉链中



5、Faiss向量编码
(1)向量距离计算


6、 Faiss向量检索流程
(1) 先查询一级量化器
查询以及量化器的目的是找到nprobe个聚类中心的点
(2) 二级量化器查询
扫描器类型IVFPQScanner

(3) Faiss 二级量化器查询步骤
距离计算
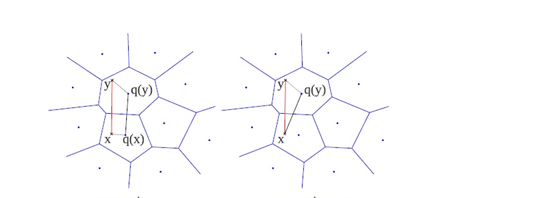
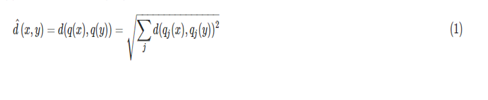
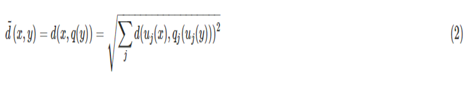
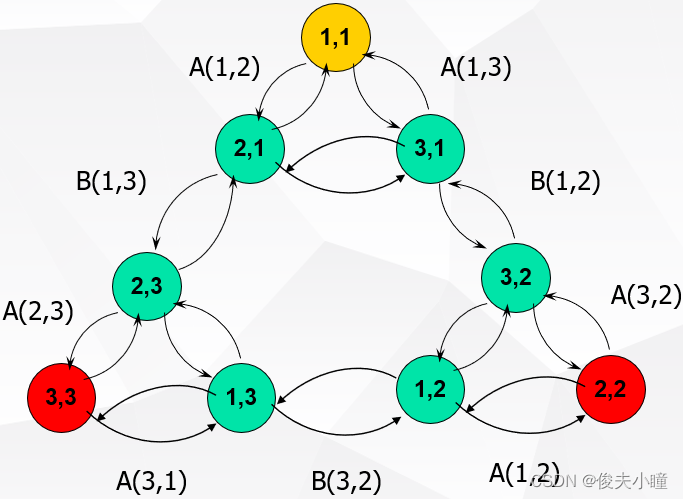
我们查询距离是非对称方法,第二张图,
SDC算法:先用PQ量化器对x和y表示为对应的中心点q(x)和q(y),然后用公式1来近似d(x,y)。
ADC算法:只对y表示为对应的中心点q(y),然后用公式2来近似d(x,y)。
参考文献:http://vividfree.github.io/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2017/08/05/understanding-product-quantization
(4) Faiss向量检索整体流程示意图


(5) Faiss 二级量化器查询核心函数
匿名函数init_result
这个函数是为了获取结果Topk,其中处理的是一个堆数据结构
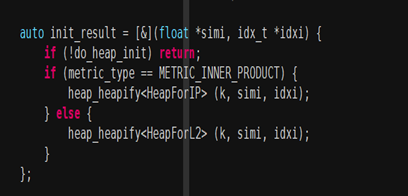
匿名函数scan_one_list 扫描一个聚类中心的倒排拉链,并把数据使用堆排序返回TopK

(6)Faiss 二级量化器查询步骤1
首先创建一个扫描器InvertedListScanner *scanner;在本例中是IVFPQScanner类型
扫描器设置查询向量query,其实这个时候已经开始计算跟所有中心向量的距离
扫描聚类中心节点列表
根据中心点去查询倒排拉链,暴力搜索向量中心周围所有的点,并求距离


(7) Faiss 二级量化器查询步骤2
查询的距离表示
距离计算是4个低维空间的距离之和,然后排序TopK

7、Faiss FAQ
(1) Faiss查询是否线程安全的?
Faiss本身是线程安全,但是Faiss内部在耗时统计代码中不是线程安全的,比如indexIVF_stats这个数据结构,就是搞了一个全局变量来统计耗时,这种方法仅仅使用在测试阶段
(2) Faiss可以同时查询N个query,每个query都查询nprobe个中心点吗?
是的,每个query一级量化器都返回nprobe个中心点
(3) Faiss查询优化问题
(4) Faiss查询优化问题
注意:(1)parallel_mode=0的时候,max_codes设置一定值,比如1000才有效,否则无效,当nprobe >1 的时候,
设置max_codes才有效,因为如果nprobe=1相当于遍历一个中心点的倒排索引,遍历完才去判断是否break,
无论max_codes设置多么小,都是需要遍历一个中心点的倒排拉链的

(5) scan_codes聚类中心点的扫描可以离线化(主要耗时点)
这个扫描是该聚类中心id周围样本向量所有距离计算,找出topk, 其实可以提前计算好分段距离,根据距离再量化成不同的分区---精度会下降
(6) faiss查询内存申请和释放问题
faiss内部为了支持线程安全每次查询都申请和释放大量内存,业务方往往在调用的时候单进程或多线程模型,大部分搜索处理模块线程数固定,不是每个query来了再启动一个线程,所以针对faiss内部频繁申请和释放内存可以使用线程存储的相关方法,循环使用内存,避免频繁申请和释放
二 向量化落地(部署)
1、独立部署向量

2、向量作为索引类型

3、无Faiss在线召回

三 未来工作展望-深度优化

- 向量召回后参考文本召回结果在底层合并
- 机器学习应用在底层索引模块打分
- 针对向量召回的特殊doc(文本匹配较差), 正排飘红优
- 在模型训练优化,提取content中的关键字+ query一起训练
四 参考文献
DSSM
https://www.cnblogs.com/wmx24/p/10157154.html
NSG
https://zhuanlan.zhihu.com/p/100716181
Faiss
https://github.com/facebookresearch/faiss/wiki
Vearch
https://vearch.readthedocs.io/zh_CN/latest/overview.html#id3
深度语义匹配模型
https://blog.csdn.net/qq_27590277/article/details/106264477
https://blog.csdn.net/ling620/article/details/95468908
https://zhuanlan.zhihu.com/p/39920446
https://www.cnblogs.com/guoyaohua/p/9229190.html
https://cloud.tencent.com/developer/article/1562482
http://www.wangqingbaidu.cn/article/dlp1516351259.html
https://www.jianshu.com/p/c578a77e7111