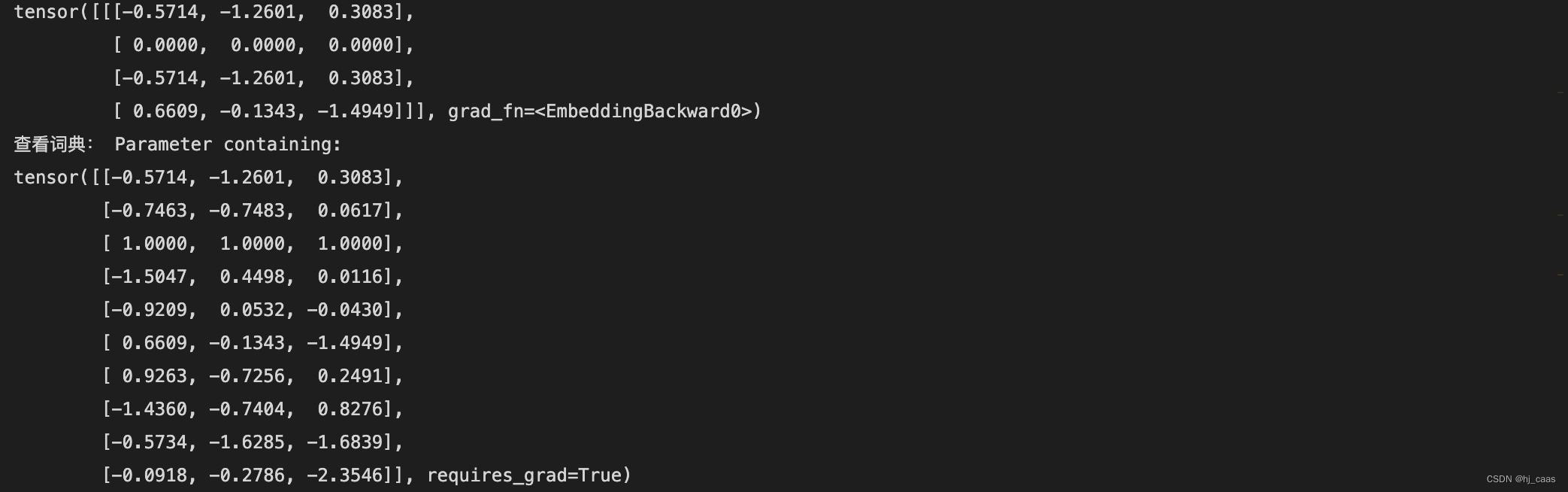
近年来流行的卷积神经网络
- 1. 回顾与目标
- 2. 近年来流行的卷积神经网络
- 2.1 VGGNet
- 2.1.1 感受野的概念
- 2.1.2 感受野的计算
- 2.2 GooleNet
- 2.3 ResNet
- 3. 结尾
- 参考资料
1. 回顾与目标
前面几讲,我们以LeNet和AlexNet为例,详细讲解了卷积神经网络的结构。从2012年AlexNet在ImageNet数据集上获得远超传统算法识别率以来,学术界在卷积神经网络方面进行了一系列的改进型研究工作,这一讲我们将描述这些重要的改进。
下图1是截至2015年卷积神经网络的发展图。

2012年AlexNet将ImageNet数据集的Top5错误率降低到16.4%。
2014年VGGNet和GooleNet分别将Top5错误率降低到7.3% 和 6.7%。
2015年ResNet将这个错误降低到3.57%,首次达到和真人不相上下的错误率。
在这一讲中,我们将大致讲解VGGNet、GooleNet和ResNet的结构。同时我们将这三个网络的论文链接附在参开资料中,供大家下载学习。
2. 近年来流行的卷积神经网络
2.1 VGGNet
首先是VGGNet,下图2是16层和19层的VGGNet(VGG16和VGG19)以及它们与AlexNet的对比图。

VGGNet对AlexNet的改进包括两个方面:
- 增加了网络的深度
- 用多个3×3卷积核叠加代替更大的卷积核,用以增加感受野(
Receptive Field)
2.1.1 感受野的概念
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(Feature Map)上的像素点在输入图片上映射的区域大小。在通俗一点的解释是特征图上的一个点对应输入图上的区域,如下图3所示。

图3最右边绿色特征图上左上角的一个点对应的感受野是最左边原图像上5×5的方格。
2.1.2 感受野的计算
下面我们通过两个例子来介绍感受野是如何计算的。
例1:两层3×3的卷积核卷积操作之后,第三层特征图上的每一个点的感受野是5×5,其中卷积核(filter)的步长(stride)为1、padding为0。其计算的方式如下图所示。

例2:如果步长stride=2,则两层3×3卷积核操作之后,第三层特征图上每一个点的感受野是15×15。
计算感受野的一般公式为:
R F i = ( R F i − 1 − 1 ) × s t r i d e i − 1 + K S I Z E i RF_i=(RF_{i-1}-1)×stride_{i-1}+KSIZE_i RFi=(RFi−1−1)×stridei−1+KSIZEi
其中, R F i RF_i RFi第 i i i层的感受野, s t r i d e i stride_i stridei第 i i i层的步长, K S I Z E i KSIZE_i KSIZEi是 i i i层的卷积核大小。
可见,在步长stride=1的情况下,两个3×3的卷积核叠加后的感受野和5×5的卷积核相同,这也就是VGGNet为什么要用多个3×3的卷积核叠加取代AlexNet中较大卷积核的原因。
更详细的分析一下,2个3×3的卷积核待求参数18个,而1个5×5的卷积核待求参数25个。因此用更小的卷积核叠加代替大的卷积核可以起到降低待估计参数的作用。但是多层卷积需要更大的计算量,中间过程过程特征图也需要更多的储存空间,因此VGGNet是一个计算和存储开销都较大的网络。
2.2 GooleNet
2014年提出的GooleNet也采用了这种利用小卷积核叠加来代替大卷积核的思路,GooleNet提出了Inception结构,Inception结构是用一些1×1,3×3和5×5的小卷积核用固定方式组合到一起来代替大的卷积核,达到增加感受野和减少参数个数的目的。
下图是GooleNet的结构。

共有22层,利用Inception结构,GooleNet将参数个数缩小到500万个左右,比AlexNet小了12倍,同时GooleNet获得了ILSVRC'14测试冠军(6.7%top 5 error)
2014年研究人员分析了深度神经网络,并从理论和实践上证明更深的卷积神经网络能够达到更高的识别准确率(L.J. Ba and R.Caruana,Do deep nets really need to be deep? NIPS 2014.)。因此,如何构建让更深的卷积神经网络收敛成了研究领域共同关注的问题。
2.3 ResNet
在2015年,Kaiming He等人发明了ResNet,使得训练深层的神经网络成为了可能(K. He,X. Zhang S. Ren and J.sun, Deep residual learning forimage recognition,cVPR2016.)。ResNet的作者首先发现训练一个浅层的网络无论是在训练集还是测试集上都比深层网络表现得好,而且是在训练的各个阶段持续的表现得好。如下图6所示,20层的卷积神经网络在不同的数据集上都比56层的卷积神经网络要好。

于是作者产生了一个很简单的想法,竟然20层的网络表现比56层要好,那么我们大不了另外36层什么都不做,直接将第20层的输出加入到第56层中,因此就产生了ResNet的核心思想,如下图7所示。

将浅层的输出直接加到深层当中去,当然在实际的添加中,由于浅层和深层的特征图在维度上有可能不一致导致无法直接相加,我们可以用一个线性变换直接把浅层特征图的维度变为深层特征图的维度。例如假设浅层特征图用向量 X X X 表示,那么用一个线性变换 X ′ = w T X + B X'=w^TX+B X′=wTX+B可以使变化后的向量 X ′ X' X′与生成的特征图维度一致,而矩阵 w w w 和 B B B 可以作为待求变量被学习。这是2015年提出的ResNet50的结构,如下图8所示。

共有50层,可以看到中间有很多浅层加入深层的操作,训练技巧如下:
-- Batch Normalization
-- Xavier initialization
-- SGD + Momentum (0.9)
-- Learning Rate:0.1
-- Batch size 256
-- Weight decay 1e-5
-- No dropout
经过前面的学习能够相对容易的看懂这些技巧。
ResNet在2015年将ImageNet测试集错误率降低到3.57%。到目前为止,ResNet这种将浅层的输出直接加入到深层的结构被广泛应用于深度学习的训练中,运用ResNet的结构已经可以训练成百上千层的卷积神经网络了。
寻找更好的神经网络结构的努力一直在持续,严格的说这是一个需要在识别精度、计算量、存储量三个方面平衡取舍的问题。近年来,流行的趋势是利用紧凑的、小而深的网络代替以往稀疏的、大而浅的网络,同时在具体的实践过程中加入一些创意和技巧。近年来流行的例如ShuffleNet、MobileNet等都是其中的典型代表,另一方面,网络结搜索(Network Architecture Search),即如何从一大堆网络结构中搜索适合具体的网络结构成为领域内另一个热点问题。
本讲最后,给出截至2016年各种不同的卷积神经网络在ImageNet上的计算量和识别率的对比图。横坐标是网络的计算量,纵坐标是网络的Top1识别率。


可以看到,近年来涌现出了很多在计算量和识别精度上都远远超过AlexNet的卷积神经网络。
3. 结尾
本讲主要讲了继AlexNet之后的卷积神经网络的发展历史,我们以VGGNet为例介绍了感受野的概念,也讲到了训练深层卷积神经网络常用的ResNet结构。
最后有一道讨论题:
如果大家对卷积神经网络感兴趣,可以查询最近几年流行的卷积神经网络的论文,总结这些神经网络的优势与劣势,同时,请大家讨论为什么这些网络结构能够流行?其中是否有一些设计网络结构的技巧和规律呢?
参考资料
- 浙江大学《机器学习》课程—胡浩基老师主讲
- Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
- Christian Szegedy, Wei Liu, Yangqing Jia et al “Going Deeper with Convolutions.” arXiv:1409.4842
- K. He,X. Zhang S. Ren and J.sun, Deep residual learning forimage recognition,cVPR2016.
- L.J. Ba and R.Caruana,Do deep nets really need to be deep? NIPS 2014.