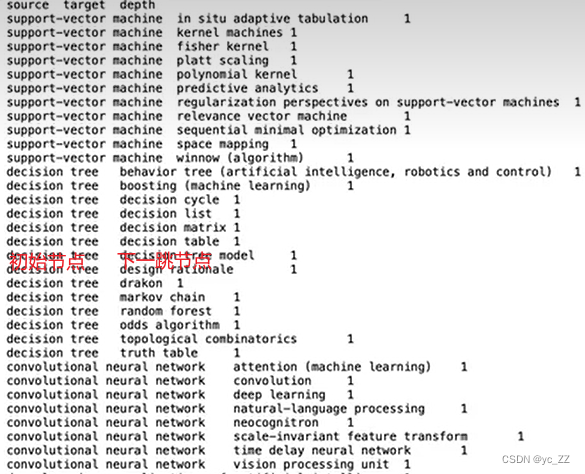
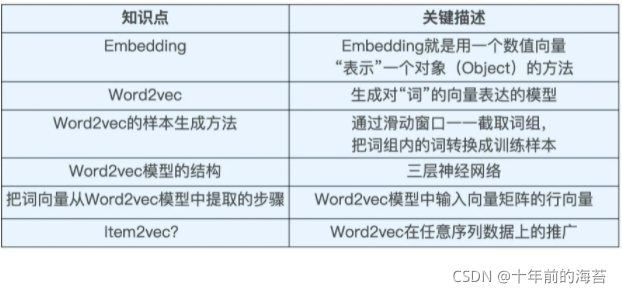
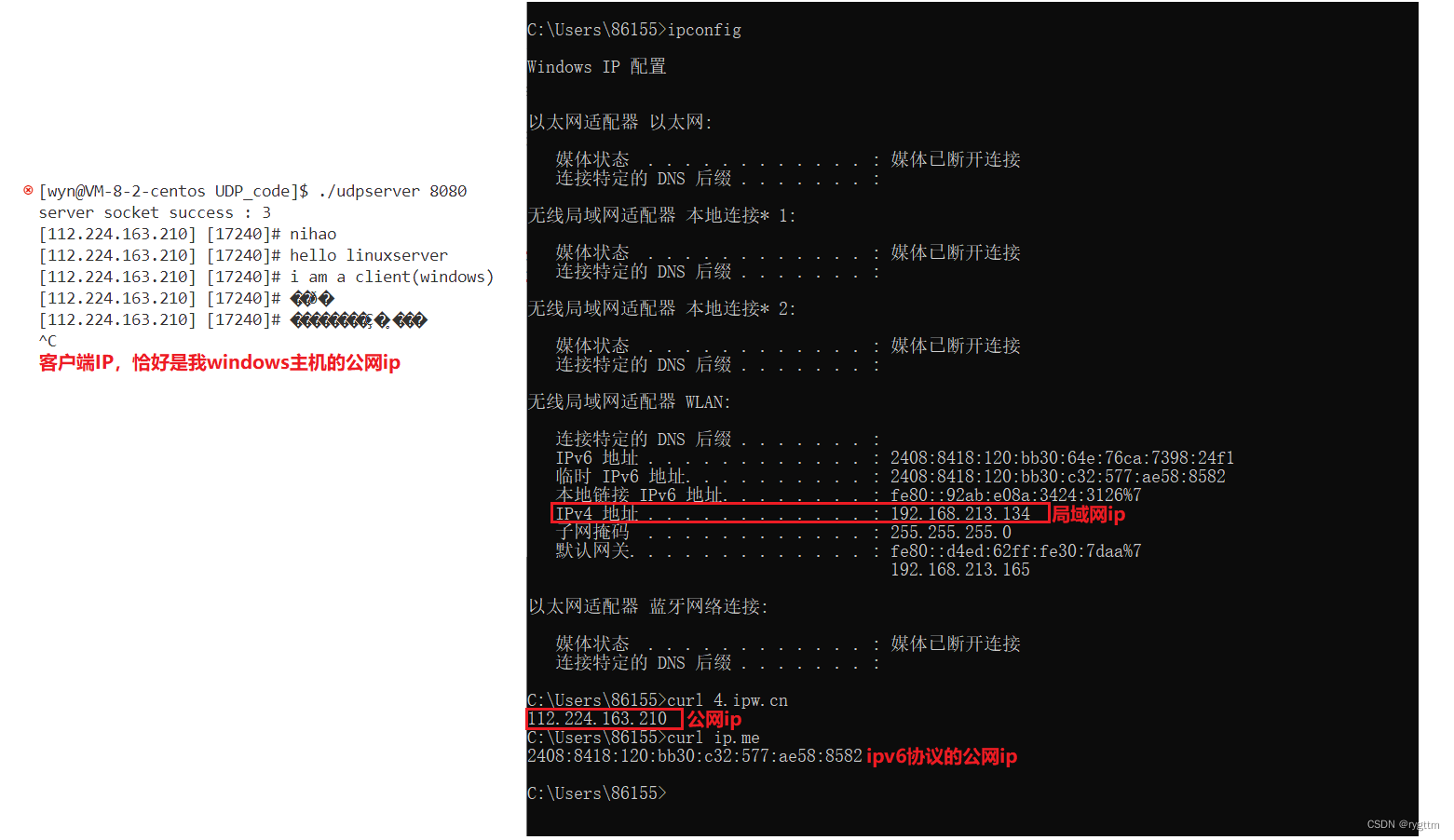
这篇文章把embedding单独提出来,梳理一下embedding在推荐系统中的应用。以下内容主要从深度学习方法和传统的协同过滤方法两个方面加深和理解在推荐系统领域对embedding的认识,详细解读下“embedding”这一重要思想。
什么是Embedding?
Embedding(嵌入)是拓扑学里面的词,在深度学习领域经常和Manifold(流形)搭配使用。
可以用几个例子来说明,比如三维空间的球体是一个二维流形嵌入在三维空间(2D manifold embedded in 3D space)。之所以说他是一个二维流形,是因为球上的任意一个点只需要用一个二维的经纬度来表达就可以了。
又比如一个二维空间的旋转矩阵是2x2的矩阵,其实只需要一个角度就能表达了,这就是一个一维流形嵌入在2x2的矩阵空间。
什么是深度学习里的Embedding?
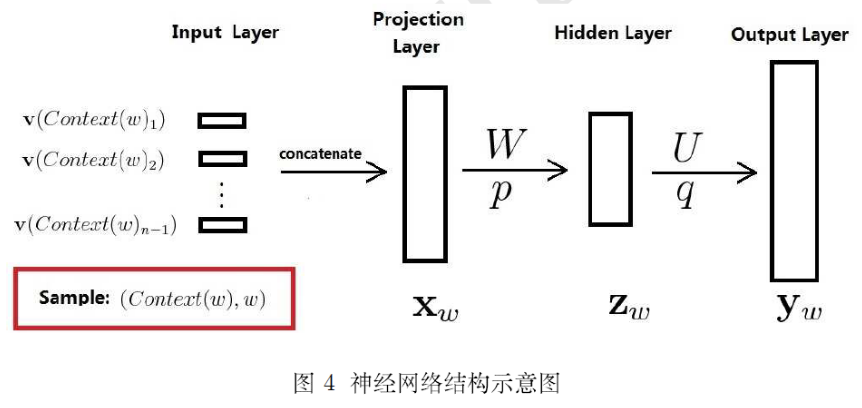
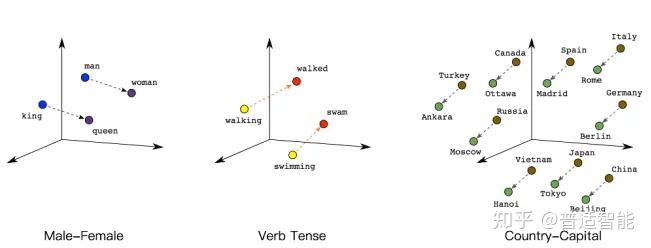
这个概念在深度学习领域最原初的切入点是所谓的Manifold Hypothesis(流形假设)。流形假设是指“自然的原始数据是低维的流形嵌入于(embedded in)原始数据所在的高维空间”。那么,深度学习的任务就是把高维原始数据(图像,句子)映射到低维流形,使得高维的原始数据被映射到低维流形之后变得可分,而这个映射就叫嵌入(Embedding)。比如Word Embedding,就是把单词组成的句子映射到一个表征向量。但后来不知咋回事,开始把低维流形的表征向量叫做Embedding,其实是一种误用。。
如果按照现在深度学习界通用的理解(其实是偏离了原意的),Embedding就是从原始数据提取出来的Feature,也就是那个通过神经网络映射之后的低维向量。
具体可以参考:Neural Networks, Manifolds, and Topology
深度学习方法
先拿一篇推荐系统领域中最为经典的论文之一“Deep Neural Networks for YouTubeRecommendations”来讲,Youtube的这篇视频推荐模型框架基本上奠定了后面推荐系统的主要步骤:召回和排序,如下图所示: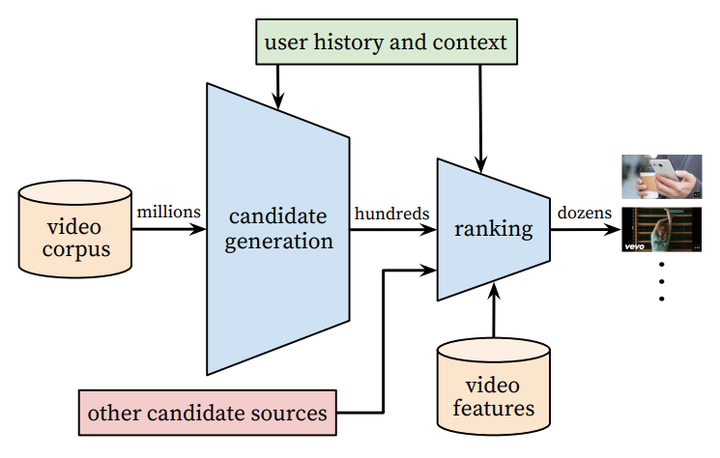 其中召回阶段(candidate generation)就是要从推荐的百万级别的视频库中筛选出用户可能感兴趣的视频,把推荐的视频库量级从百万级降到几百个。但是到底怎样才能快速高效的完成筛选呢?
其中召回阶段(candidate generation)就是要从推荐的百万级别的视频库中筛选出用户可能感兴趣的视频,把推荐的视频库量级从百万级降到几百个。但是到底怎样才能快速高效的完成筛选呢?
要知道youtube是非常活跃的视频网站,每秒同时访问的人数成千上万,要同时实现每秒对每个用户都个性化的