what is emdding
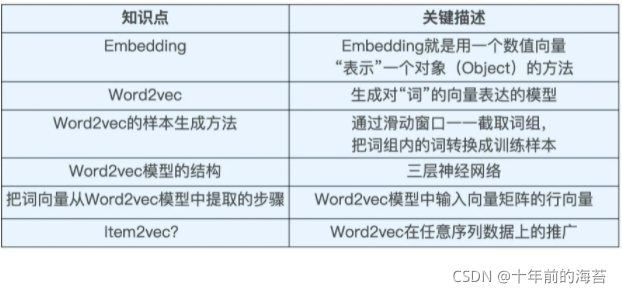
embedding就是把字词用向量表示出来,相当于是对字词做encoding
motivation
比如 猫,狗,我们当然可以直接把他们表示为一些独立的离散符号,但是这样的表示毫无意义,而且会产生大量稀疏数据。使我们在训练统计模型时不得不寻求更多的数据。而词汇的向量表示将克服上述的难题。
background
VSM(vector space model)
核心思想就是把一些词用向量空间的表示方法。最基本的应用,就是tf-idf。
我们把一篇文档用一组向量表示,然后计算文档之间的余弦值来衡量文档相似度。vsm在nlp有着非常丰富的应用历史,不过这一模型又是基于分布式假设的。
分布式假设
其核心思想是:认为出现在上下文情景中的词汇都有着相似的语义。
基于这一假设的方法,大致可以分为两类:
– 计数方法。潜在语义分析(latent sematics analysis)
– 预测方法。神经概率化模型
用神经网络训练语言模型,比较经典就是Bengio于2003年发表在JMLR上的《A Neural Probabilistic Language Model》
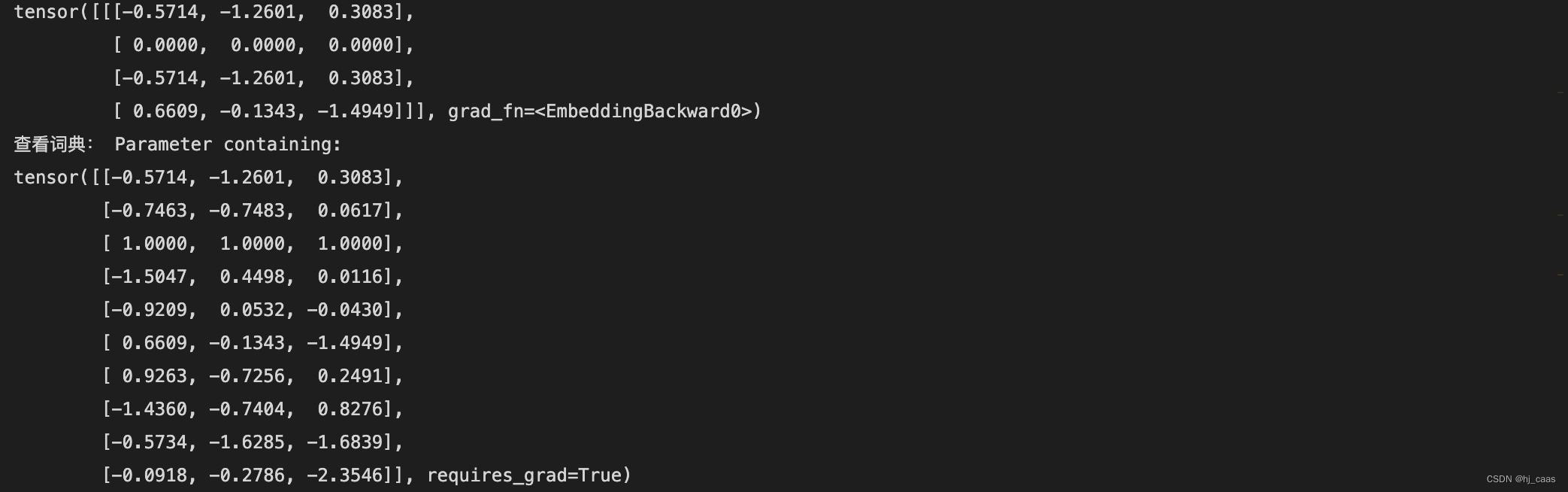
最简单的词向量,当属于one-hot的表示,这种表示并不是很理想,而distributed represention则比one-hot的好很多,一个猜测是:one-hot的表示相当于是空间中一个孤立的点,而distributed representation,则有种风险平摊的感觉,就像文档表示,被分摊到很多词上面。神经概率语言模型
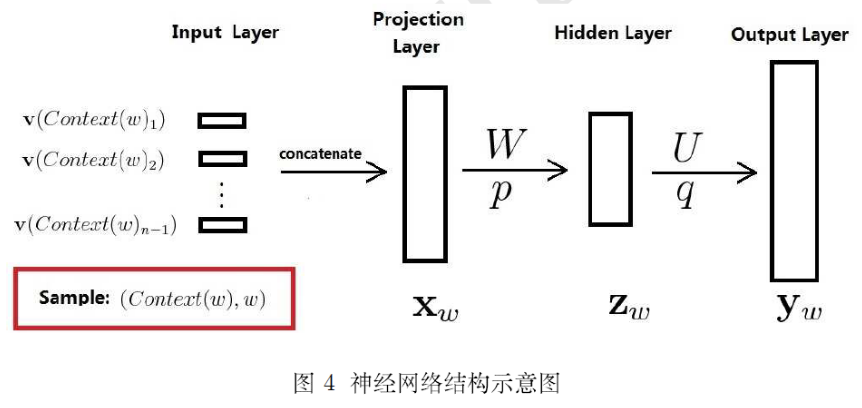
比较经典就是Bengio于2003年发表在JMLR上的《A Neural Probabilistic Language Model》,该论文提出的模型如下:
其中,w,u都是权重。p和q表示偏置项(bias)
输入的v是一个已经训练好的词向量。
输入的个数类似于n-gram,比如假设只跟其前n-1个词语有关于,那么输入层就是n-1,如果向量大小为m,那么投影层就是(n-1)*m的大小,隐层是由语料库的大小决定的,假设有C个。
那么神经网络语言模型和传统的n-gram的区别是什么呢?
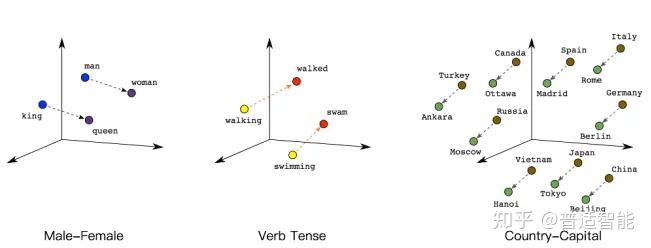
(1) 词语之间的相似性可以通过词向量来体现。(句子层面)
(2) 自带平滑功能。(词层面)
【这里不是很懂,再看看原文章】
http://blog.csdn.net/itplus/article/details/37969817
Word2Vec
最初的提出者:Tomas Mikolov
经典文章:
两种衍生:CBOW Skip-gram