目录
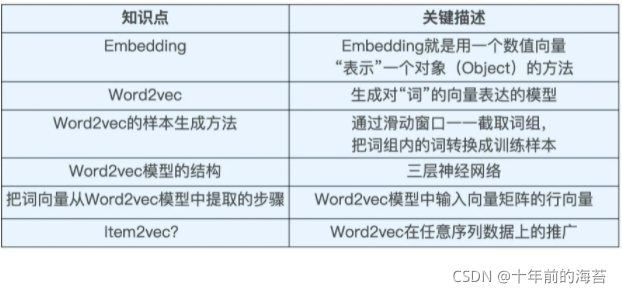
- Embedding
- 主要思想
- Word2vec
- 主要思想
- 两种模型:
- 目的:
- 算法
- 一、定义超参数
- 二、将语料库转换one-hot编码表示
- 三、模型训练
- 代码手动实现 skip-gram模型
- 一、数据准备
- 二、定义超参数
- 三、定义word2vec模型
- 数据清洗及生成词汇表
- 训练模型
- 四、 获取词向量和相似词
- 完整代码
- Item2vec
- 主要思想
- 运用
- 局限性
- Deepwalk-基础的Graph Embedding算法
- 主要思想
- 算法
- 代码
Embedding
主要思想
把世界万物变成一个向量,让计算机看这个向量,再进行处理
万物都可嵌入
Word2vec
主要思想
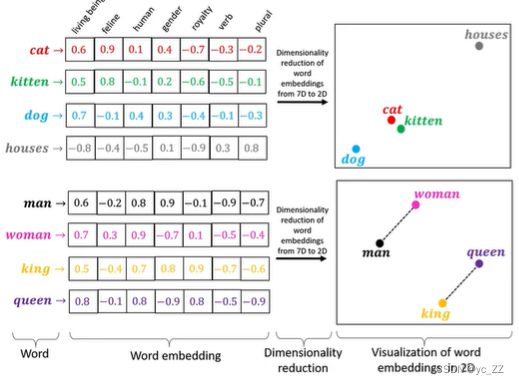
就是把每个单词变成一个向量,并且这个向量还保留了单词的语义关系
example:man<->woman,queen<->king
两种模型:
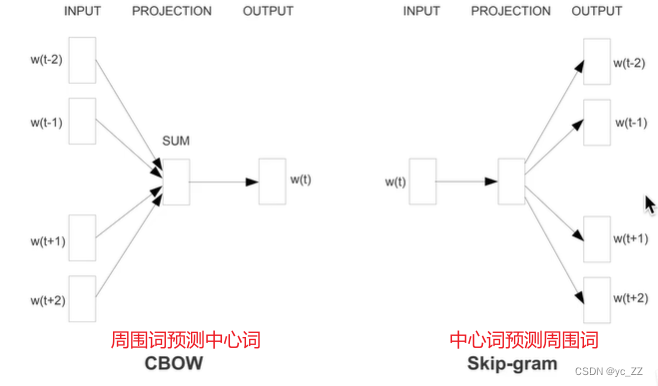
CBOW、Skip-gram(用处广)
目的:
把每个词都用向量表示,同时还保留他们之间语义关系
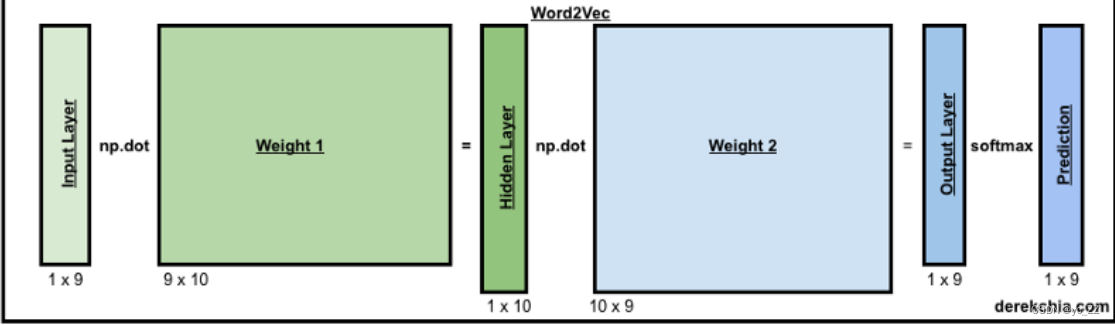
算法
一、定义超参数
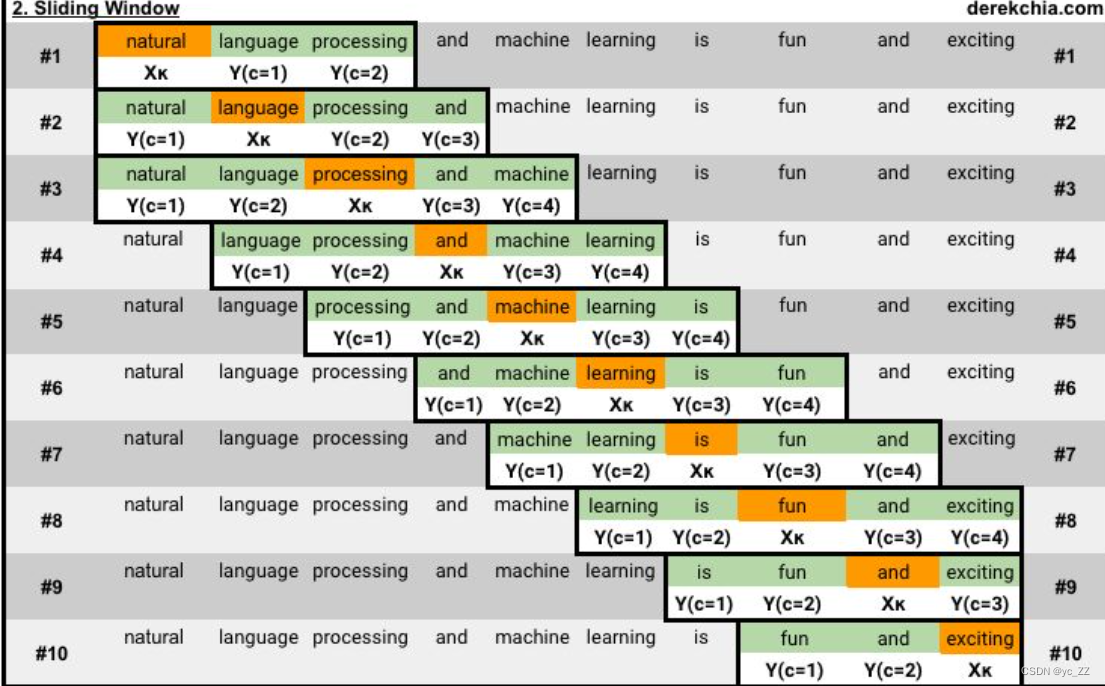
学习率、训练次数、窗口尺寸、嵌入(embedding)尺寸
以下是窗口为二的滑动窗口
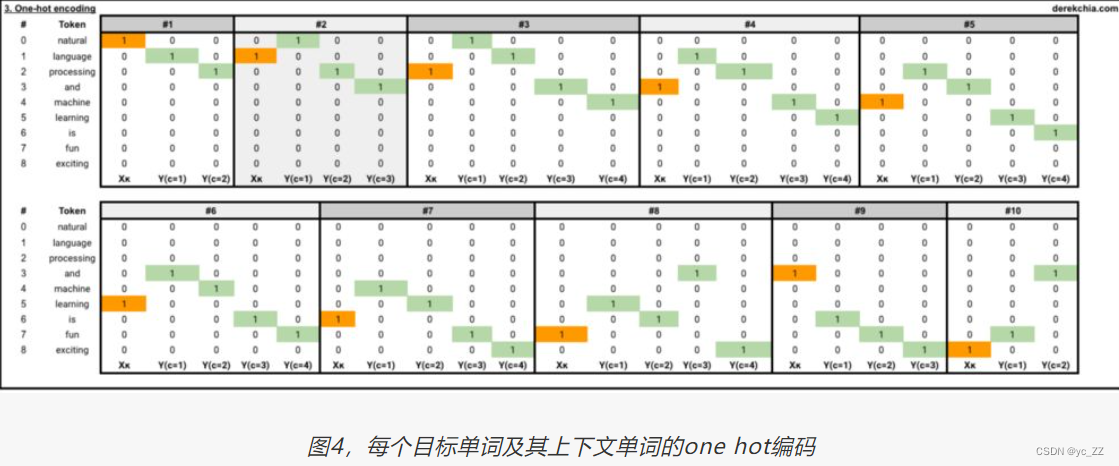
二、将语料库转换one-hot编码表示
三、模型训练
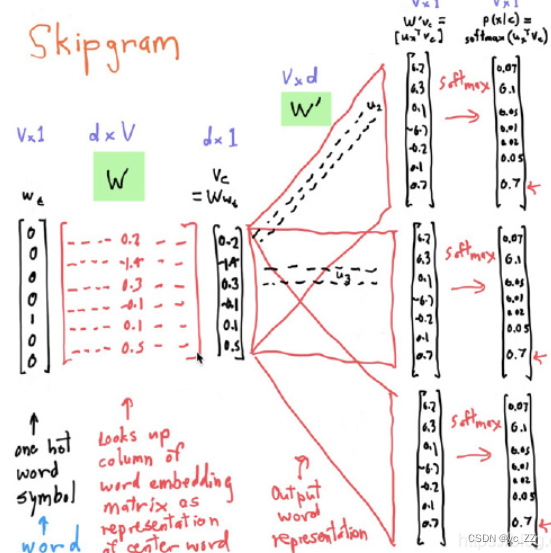
1、目标词的one-hot编码传入神经网络模型中训练,最后得到输出结果
2、训练得到的输出结果运用softmax函数归一化处理
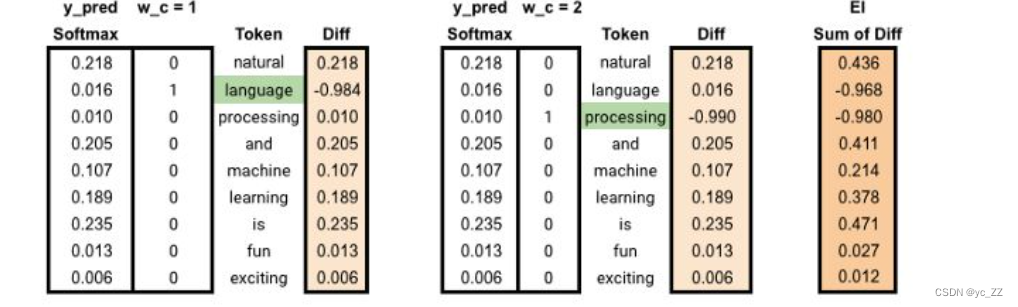
3、处理后的结果和相邻窗口的单词one-hot编码分别做差得到各自的误差
4、将各自误差相加得到总误差
5、交叉熵损失函数处理
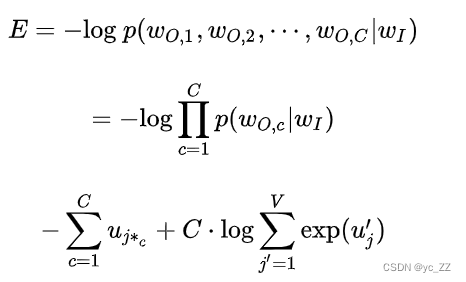
6、通过对参数求偏导,梯度下降方法求更新的参数,反向传播更新权重矩阵
7、最终求得更新迭代过后的输入层到隐藏层的权重矩阵即为对应词的embedding词向量
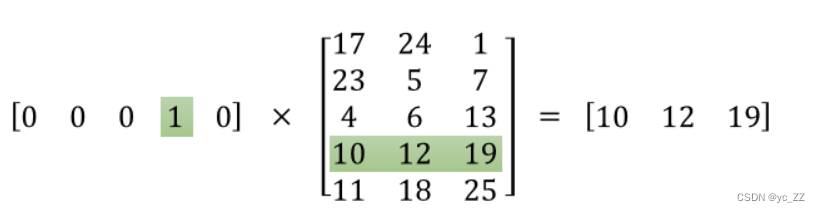
代码手动实现 skip-gram模型
一、数据准备
#准备语料库text="natural language processing and machine learning is fun and exciting"#分词处理corpus=[[word for word in text.split()]]
二、定义超参数
#准备超参数settings = {'window_size': 2, # 窗口大小(目标单词的左边和右边最近的2个单词被视为上下文单词)'n': 10, # 单词嵌入维度,取决于词汇库大小,也是隐藏层大小'epochs': 50, # 训练次数'learning_rate': 0.01 # 学习率}
三、定义word2vec模型
class word2vec():
def __init__(self):self.n = settings['n']self.lr = settings['learning_rate']self.epochs = settings['epochs']self.window = settings['window_size']
数据清洗及生成词汇表
为后续把数据放入神经网络做准备
在函数train_data内部,我们进行以下操作:
self.v_count: 词汇表的长度(注意,词汇表指的就是语料库中不重复的单词的数量)
self.words_list: 在词汇表中的单词组成的列表
self.word_index: 以词汇表中单词为key,索引为value的字典数据
self.index_word: 以索引为key,以词汇表中单词为value的字典数据
for循环给用one-hot表示的每个目标词和其的上下文词添加到train_data中,one-hot编码用的是word2onehot函数。
def train_data(self,settings,corpus):#先对语料库进行去重,得到去重后的每个词语对应的个数 返回的是一个字典word_counts=defaultdict(int)for row in corpus:for word in row: #这里的word是二维数组里的单词word_counts[word]+=1# 计算有多少个不同的单词self.v_count = len(word_counts.keys())#去重后单词放入列表self.words_list=list(word_counts.keys())#做成 单词:索引(这里要提出i,word两个参数 所以用enumerate)self.word_index=dict((word,i) for i,word in enumerate(self.words_list))#做成 索引:单词self.index_word = dict((i,word) for i, word in enumerate(self.words_list))#开始存入目标及窗口范围内的词语train_data=[]for sentence in corpus:sent_len = len(sentence)for i, word in enumerate(sentence):w_target=self.word2onehot(sentence[i])#保存窗口范围内的词语w_context=[]for j in range(i-self.window,i+self.window):if j != i and j <= sent_len - 1 and j >= 0:w_context.append(self.word2onehot(sentence[j]))train_data.append([w_target,w_context])#这里就是最终存入神经网络输出层的格式return np.array(train_data) #定义Onehot函数def word2onehot(self,word):#初始化都是0word_vec=[0 for i in range(0,self.v_count)]#找到传入单词在句子中的索引word_index=self.word_index[word]#将对应位置改为1word_vec[word_index]=1return word_vec
训练模型
#训练模型def train(self,train_data):#定义权重矩阵self.w1=np.random.uniform(-1,1,(self.v_count,self.n))self.w2=np.random.uniform(-1,1,(self.n,self.v_count))#迭代训练for i in range(self.epochs):self.loss=0for w_t,w_c in train_data:#将目标词语进入前向传递y_pred,h,u=self.forward_pass(w_t)#将窗口误差相加EI=np.sum([np.subtract(y_pred,word) for word in w_c],axis=0)#反向传播self.backprop(EI,h,w_t)#计算误差self.loss += -np.sum([u[word.index(1)] for word in w_c]) + len(w_c) * np.log(np.sum(np.exp(u)))print('Epoch:', i, "Loss:", self.loss)def forward_pass(self,x):h=np.dot(x,self.w1)u=np.dot(h,self.w2)y_c=self.softmax(u)return y_c,h,udef softmax(self,x):e_x=np.exp(x-np.max(x))return e_x/e_x.sum(axis=0)def backprop(self,e,h,x):dl_dw2 = np.outer(h, e)dl_dw1 = np.outer(x, np.dot(self.w2, e.T))self.w1 = self.w1 - (self.lr * dl_dw1)self.w2 = self.w2 - (self.lr * dl_dw2)
四、 获取词向量和相似词
# 获取词向量def word_vec(self, word):w_index = self.word_index[word]v_w = self.w1[w_index]return v_w#获取相似词def vec_sim(self,word,top_n):v_w1=self.word_vec(word)word_sim={}for i in range(self.v_count):v_w2=self.w1[i]theta_sum=np.dot(v_w1,v_w2)theta_den=np.linalg.norm(v_w1)*np.linalg.norm(v_w2)theta=theta_sum/theta_denword=self.index_word[i]word_sim[word]=thetawords_sorted=sorted(word_sim.items(),key=lambda kv:kv[1],reverse=True)for word,sim in words_sorted[:top_n]:print(word,sim)
完整代码
import numpy as np
import math
from collections import defaultdict#定义模型
class word2vec():def __init__(self):self.n = settings['n']self.lr = settings['learning_rate']self.epochs = settings['epochs']self.window = settings['window_size']#定义训练数据函数(一个目标词,以及窗口范围内的词语 把他们都转化为one-hot编码)#清洗数据def train_data(self,settings,corpus):#先对语料库进行去重,得到去重后的每个词语对应的个数 返回的是一个字典word_counts=defaultdict(int)for row in corpus:for word in row: #这里的word是二维数组里的单词word_counts[word]+=1# 计算有多少个不同的单词self.v_count = len(word_counts.keys())#去重后单词放入列表self.words_list=list(word_counts.keys())#做成 单词:索引(这里要提出i,word两个参数 所以用enumerate)self.word_index=dict((word,i) for i,word in enumerate(self.words_list))#做成 索引:单词self.index_word = dict((i,word) for i, word in enumerate(self.words_list))#开始存入目标及窗口范围内的词语train_data=[]for sentence in corpus:sent_len = len(sentence)for i, word in enumerate(sentence):w_target=self.word2onehot(sentence[i])#保存窗口范围内的词语w_context=[]for j in range(i-self.window,i+self.window):if j != i and j <= sent_len - 1 and j >= 0:w_context.append(self.word2onehot(sentence[j]))train_data.append([w_target,w_context])return np.array(train_data)#定义Onehot函数def word2onehot(self,word):#初始化都是0word_vec=[0 for i in range(0,self.v_count)]#找到传入单词在句子中的索引word_index=self.word_index[word]#将对应位置改为1word_vec[word_index]=1return word_vec#训练模型def train(self,train_data):#定义权重矩阵self.w1=np.random.uniform(-1,1,(self.v_count,self.n))self.w2=np.random.uniform(-1,1,(self.n,self.v_count))#迭代训练for i in range(self.epochs):self.loss=0for w_t,w_c in train_data:#将目标词语进入前向传递y_pred,h,u=self.forward_pass(w_t)#将窗口误差相加EI=np.sum([np.subtract(y_pred,word) for word in w_c],axis=0)#反向传播self.backprop(EI,h,w_t)#计算误差self.loss += -np.sum([u[word.index(1)] for word in w_c]) + len(w_c) * np.log(np.sum(np.exp(u)))print('Epoch:', i, "Loss:", self.loss)def forward_pass(self,x):h=np.dot(x,self.w1)u=np.dot(h,self.w2)y_c=self.softmax(u)return y_c,h,udef softmax(self,x):e_x=np.exp(x-np.max(x))return e_x/e_x.sum(axis=0)def backprop(self,e,h,x):dl_dw2 = np.outer(h, e)dl_dw1 = np.outer(x, np.dot(self.w2, e.T))self.w1 = self.w1 - (self.lr * dl_dw1)self.w2 = self.w2 - (self.lr * dl_dw2)# 获取词向量def word_vec(self, word):w_index = self.word_index[word]v_w = self.w1[w_index]return v_w#获取相似词def vec_sim(self,word,top_n):v_w1=self.word_vec(word)word_sim={}for i in range(self.v_count):v_w2=self.w1[i]theta_sum=np.dot(v_w1,v_w2)theta_den=np.linalg.norm(v_w1)*np.linalg.norm(v_w2)theta=theta_sum/theta_denword=self.index_word[i]word_sim[word]=thetawords_sorted=sorted(word_sim.items(),key=lambda kv:kv[1],reverse=True)for word,sim in words_sorted[:top_n]:print(word,sim)"""
word_counts: {'natural': 1, 'language': 1, 'processing': 1, 'and': 2, 'machine': 1,
'learning': 1, 'is': 1, 'fun': 1, 'exciting': 1}
words_list: ['natural', 'language', 'processing', 'and', 'machine', 'learning', 'is', 'fun', 'exciting']
"""
if __name__ == '__main__':#准备超参数settings = {'window_size': 2, # 窗口大小(目标单词的左边和右边最近的2个单词被视为上下文单词)'n': 10, # 单词嵌入维度,取决于词汇库大小,也是隐藏层大小'epochs': 50, # 训练次数'learning_rate': 0.01 # 学习率}#准备语料库text="natural language processing and machine learning is fun and exciting"#分词处理corpus=[[word for word in text.split()]]# print(corpus)"""[['natural', 'language', 'processing', 'and', 'machine', 'learning', 'is', 'fun', 'and', 'exciting']]"""#模型实例化w2v=word2vec()train_data=w2v.train_data(settings,corpus)w2v.train(train_data)print(w2v.word_vec("machine"))print(w2v.vec_sim("machine",3))Item2vec
Word2vec诞生后,Embedding思想从自然语言处理领域扩散到了所有机器学习领域。
主要思想
将物品转化为向量,保留物品之间的语义关系
相比于Word2vec利用“词序列”生成词Embedding。Item2vec利用“物品序列”构造物品Embedding。物品之间两两计算cosine相似度即为商品的相似度。
Item2vec摒弃了时间窗口的概念,认为序列中任意两个物品都相关,除此之外模型与skip-gram完全一致
运用
通过矩阵分解产生了用户隐向量和物品隐向量,从Embedding的角度看待矩阵分解,则用户隐向量和物品隐向量就是用户Embedding向量和物品Embedding向量。
item embedding: 利用用户行为序列,采用word2vec思想,生成每个item的Embedding
user embedding:由历史item embedding平均或聚类得到。
局限性
只能利用序列型数据,在处理互联网场景下大量的网络化数据时往往捉襟见肘,由此出现了
Graph Embedding
Deepwalk-基础的Graph Embedding算法
主要思想
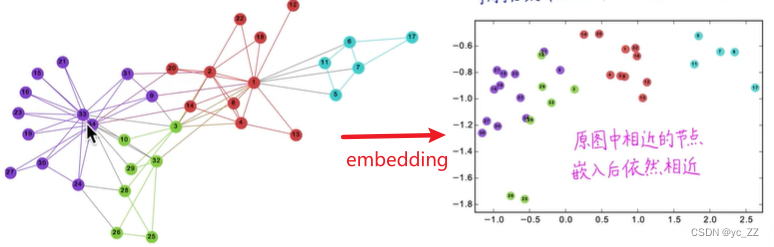
解决的是图嵌入问题,把图节点转成n维向量
其中原图中相近的节点,嵌入后依然相近
能够在向量种反映出原图中结构信息,连接信息。
算法
通过在图里像醉汉一样随机游走,生成一连串随机游走序列,每个序列都类似一句话,其中序列里的每个节点都类似word2vec里的单词。
为何需要随机游走?
图本身非常复杂,我们只能用海量的随机游走序列来捕捉图的信息和模式
可直接套用word2vec种skip-gram方法(中间节点预测相邻节点)可以捕获相邻的关联信息,最后迭代优化生成的每个节点的词嵌入向量表。最终能反映出每个节点的相似关系
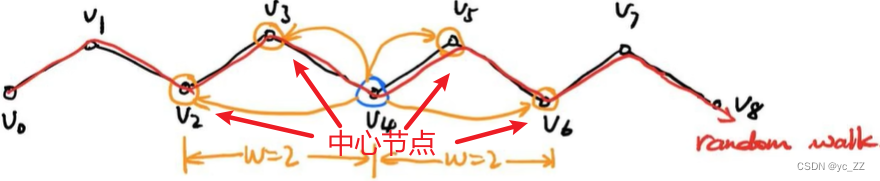
其中word2vec里假设相邻单词是相关的,deepwalk假设在随机游走序列里相邻的节点是相关的
代码
维基百科词条图嵌入

通过网站爬取,保存到了tsv文件内构成数据集
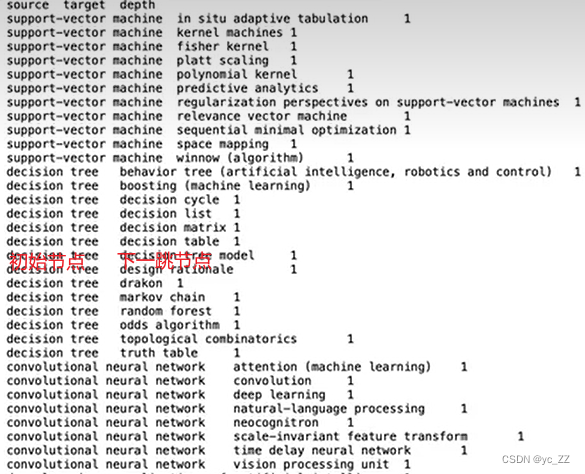
数据集:
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/11/space_data.zip
#图数据挖掘
import networkx as nx
#数据分析
import pandas as pd
import numpy as np
#随机数
import random
#进度条
from tqdm import tqdm
#降维模块
from sklearn.decomposition import PCA
#word2vec模块
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings('ignore')
#可视化模块
import matplotlib.pyplot as plt
#自然语言处理
from gensim.models import Word2Vec
#降维算法
from sklearn.decomposition import PCA#获取数据
df = pd.read_csv("space_data.tsv",sep='\t') #分隔符是\t
print(df.head())############################################## 构建无向图 ###################################################
G=nx.from_pandas_edgelist(df,"source","target",edge_attr=True,create_using=nx.Graph())#edge_attr: edge属性的列名称 nx.Graph()无向图
# print(len(G)) #生成的节点数all_nodes=list(G.nodes()) #将无向图的所有节点放入列表中
print(all_nodes)################################ 构建生成随机游走节点序列的函数(输入起始节点和路径长度,生成随机游走序列)###############
def get_randomwalk(node,path_length):random_walk=[node]for i in range(path_length-1):temp=list(G.neighbors(node)) #汇总邻接节点random_node=random.choice(temp) #随机选择一个邻接节点random_walk.append(random_node) #将此邻接节点放入列表内node=random_node #最后从此邻接节点当作第二次的初始节点return random_walk
# print(get_randomwalk('space exploration',4))###################################### 对每个节点都去做生成随机游走序列 ############################################
gamma=10 #每个节点作为起始节 点生成随机游走序列个数
walk_length=5 #随机游走序列最大长度random_walks=[]
for n in tqdm(all_nodes): #遍历每个节点for i in range(gamma): #每个节点作为起始节点生成gamma个随机游走序列random_walks.append(get_randomwalk(n,walk_length))
print(len(random_walks))
# print(random_walks[2])############################################ 训练word2vec模型 #################################################
model=Word2Vec(vector_size=256, #embedding维数window=4, #窗口宽度sg=1, #skip-gram模型hs=0, #不加分层softmaxnegative=10, #负样本采样alpha=0.03, #学习率min_alpha=0.0007,#最小学习率seed=14 #随机数种子
)
#用随机游走序列构建词汇表
model.build_vocab(random_walks,progress_per=2)
#训练
model.train(random_walks,total_examples=model.corpus_count,epochs=50,report_delay=1)
#查看某个节点的Embedding
# print(model.wv.get_vector('space exploration'))
#找相似词语
# print(model.wv.similar_by_word('in-space propulsion technologies'))################################# PCA降维可视化 (256维(高维能捕获更丰富的信息)是看不到的只能转化为2维)#################
X=model.wv.vectors
#将Embedding用PCA降维到2维
pca=PCA(n_components=2)
embed_2d=pca.fit_transform(X)
print(embed_2d.shape)plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:,0],embed_2d[:,1])
plt.show()