前言:现代深度学习实践中很多场景其实都是对输入数据进行处理、嵌入,最终获得一个 embedding,然后对 embedding 进行相似度检索,而工业界中的被检索数据往往是海量的,因此深度学习模型落地的最后一步也就是大规模向量检索。本文介绍在工业界实践中常用的向量检索方案。
- 参考网上资料经过个人理解和汇总完成本文撰写,每节参考文章见附录↓
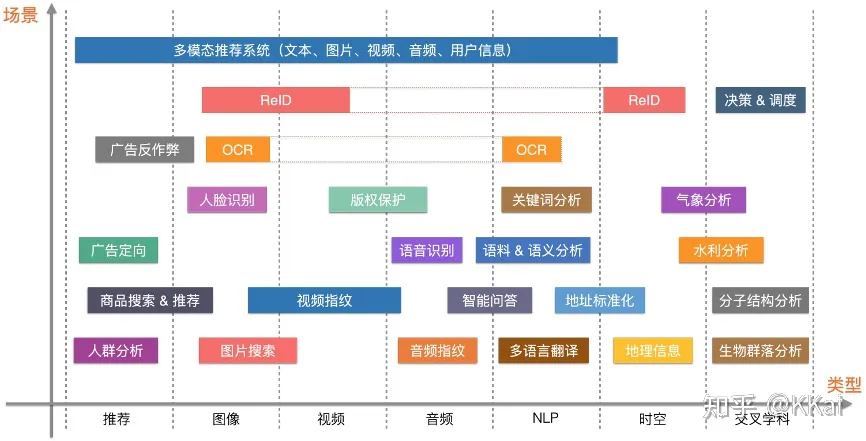
需要用到向量检索的场景举例:
引言
Embedding 本质上就是一个向量,向量检索即在一个给定的向量数据集中,以某种度量方式,检索出与 query vector 最邻近的K个向量(K-Nearest Neighbor, KNN) 。但 KNN 的精确计算的计算量过大,在工业界的大规模向量检索场景下是不可接受的,因此一般工业界采用的是近似最近邻查询(Approximate Nearest Neighbor, ANN)。
根据上述描述,可以知道一个向量检索引擎的关键包含四个要素:特征提取(生成Embedding)、距离度量(如何衡量Embedding的距离)、检索算法(如何高效召回向量)、数据存储(候选向量库如何存储);
- 特征提取模块与要解决的问题和解决问题采用的模型有关;
- 向量距离度量常见方式有:欧式距离、余弦距离、内积距离、海明距离等;
不同的度量方式对应不同的场景:通常欧式距离用于图片检索,余弦用于人脸识别,内积多用于推荐,海明距离由于向量比较小,通常用于大规模视频检索场景。 - 存储取决于具体采用的方案,实践中可以采用 ElasticSearch 或其开源版 OpenSearch 来存储(不用关心内部存储细节)。
向量检索用召回率来评估效果:对于给定的向量q,其在数据集上的K近邻为N,通过检索召回的K个近邻集合为M,则 Recall= ∣ N ∩ M ∣ K \frac{|N\cap{M}|}{K} K∣N∩M∣。
- 评估不同索引结合和向量检索算法召回率的两个项目:ann-benchmarks 、big-ann-benchmarks
- 评估向量检索算法召回的数据集:SIFT,GIST 等;
- 向量检索的优化技巧:1. 减少候选向量集;2. 降低单个向量计算的复杂度(向量压缩);
【可以跳过这里】向量检索方法综述:
- 基于空间划分:
- 暴力搜索:作为答案的基准数据,在人脸识别的场景中经常要求100%的召回率,这种情况下一般直接暴力计算。
- tree-based:KDTree、BallTree、VPTree 等;
- hash-based:Locality Sensitive Hashing
- ( d 1 d_1 d1, d 2 d_2 d2, p 1 p_1 p1, p 2 p_2 p2)-sensitive hash
- 如果d(x,y) <= d1,则h(x) = h(y)的概率至少为p1
- 如果d(x,y) >= d2,则h(x) = h(y)的概率最多为p2;
- ( d 1 d_1 d1, d 2 d_2 d2, p 1 p_1 p1, p 2 p_2 p2)-sensitive hash
- 倒排索引 IVF:计算与聚类簇中心的距离来粗排
- 聚类:K-means、K-means++、K-means#、one pass K-means、YinYang K-means 等;
- 多层聚类
- graph-based:KGraph、NSG、HNSW、NGT 等;【目前召回率上最优的方法;缺点也很大:存储、内存开销】
- a.选好入口点;b.遍历图;c.收敛;
- 裁边优化,连通性增强,指令加速,多线程处理
- 空间编码和转换法:
- 向量量化:
- 乘积量化:PQ、OPQ、LOPQ 等;
- 二值量化:ITQ(Iterative Quantization)、DeepHash 等;
- 内积转换 ∗ ^* ∗:因为内积没有LSH且不满足三角不等式,因此很多索引结构不能使用内积,有方法可以转化内积使得内积和欧式能够实现负相关,对向量转换后,可直接用欧式距离度量方式检索。而在图上,目前已经证明可以直接使用内积。
- 向量量化:
- 发展中的向量检索方法:
- graph+量化
- graph+倒排
目前业界知名的开源向量检索框架:Faiss、FLANN等;基于此产生的服务化的工程引擎:milvus、vearch 等;
向量检索的挑战:1.标签+向量联合检索;2.超大规模索引的精度和性能;3.流式索引的在线更新;4.分布式构建和检索;5.复杂多场景适配;
Reference
- 一文纵览KNN(ANN)向量检索
- 【推荐文章】图像检索:向量索引
Faiss
- wiki | Github
Faiss(Facebook AI Similarity Search) 是 Meta 公司(原名 Facebook )开源的大规模向量相似度检索和聚类框架,支持十亿级别的向量搜索。Faiss 基于 C++ 实现,并提供了支持 Numpy 的 Python 接口,其部分核心算法提供了 GPU 实现。
能加速的原理无非就是把精确解的暴力搜索,变成了近似解的搜索,并且用一定的预处理计算量构建索引,在进行检索前利用索引降低检索范围或者是计算量以此实现加速。因此 Faiss 工作流程大致分为三步:1. 导入向量库;2. 根据向量进行训练(聚类);3. 构建索引(index);
以相似用户检索为例,流程如下:

近似解必然有精度损失,一般用召回率来衡量模糊检索相对于精确检索的损失。在实际的工程中,候选向量的数量级、索引所占内存的大小、检索所需时间(离线检索 or 在线检索)、索引构建时间、检索的召回率等都是我们选择索引时常常需要考虑的地方。工业界最常见使用的方式是 IVF+PQ。
参考网上的资料给出一个不同索引对比:
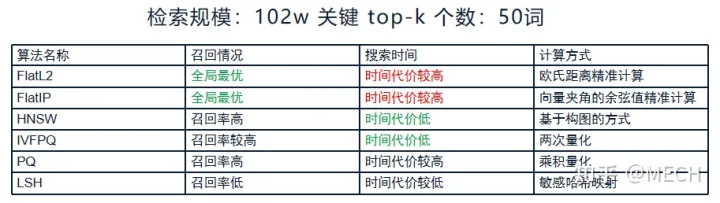

- 注意:向量库很大时,索引是否支持分批导入和是否可以增量构建索引的性质很重要,不是所有索引类型都支持该特性;官方的 Guidelines to choose an index;支持的索引类型 Index types;
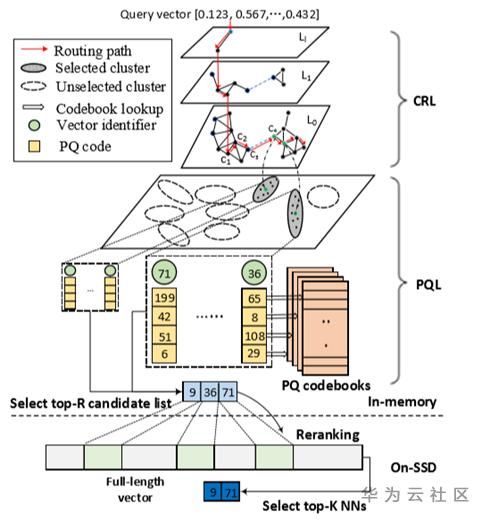
IVF+PQ
倒排索引(Inverted File System,IVF)和乘积量化(Product Quantization,PQ) 算法是 Faiss 实现快读、低内存开销以及精确检索的主要手段(分别代表了横向切分、纵向压缩来加速检索的技巧)。若无特殊情况,工业界一般使用该方法构建索引。
倒排索引
倒排索引算法↓

倒排索引确定子空间:计算query向量和所有子空间中心(eg.子空间内所有向量的均值)的距离,选出距离最近的K个子空间。Faiss 中的参数 nlist 指定聚类个数、参数 nprobe 指定检索的子空间数;一般而言,nlist 越大,训练时间越长,但最终检索速度越快(因为 TopK 子空间内待比较的向量总数变少),而 nprobe 越大则一般精度越高,但相应检索时间变长。
- 缺点:可能损失精度,局部最优;速度不稳定:聚类的不同簇包含的向量个数并不平均,因此不能达到期望的下界时间(暴搜时间/nlist),而会带上一个常数;
乘积量化
乘积量化算法↓
Cluster步骤:参数 m_split 控制向量被切分的段数,假设向量维度为128,每个向量被切分4个小的向量,对每个小向量分别进行聚类(256个簇)。

Assign步骤:对每个 cluster 进行编码0~255;对每个向量来说,先切分成四段,对每一段小向量,分别计算其对应的最近的簇心,使用这个簇心的ID当做该向量的第一个量化编码,依次类推,每个向量都可以由4个ID进行编码。每个ID长度为1个字节,向量编码共需4个字节(32bits),这样便实现了向量的压缩(128->32)。这一步即流程图中的 Faiss 训练,通过该步骤获得了索引(Index)。
向量查询:对查询向量,首先对其切分,这样就可以得到四小段的向量,然后计算每个小向量和对应的256个类中心的距离,存在一个距离矩阵中,接着就可以通过查表,来计算查询向量Query和每个向量之间的距离。计算方式就是累加每个小向量之间的距离之和。
- 为什么能相加? 由于乘积量化的计算需要 Faiss 在计算 L2 距离(欧氏距离)时没有开平方;对于余弦相似度(向量的内积除以两个向量的模)一般只先计算内积(归一化内积就是余弦相似度)因此是可以相加的;

在暴力查询中,计算量是N*128次,但在PQ算法中,计算量变为:4*N+4*256*32次。但PQ中的4*N主要是查表,远比暴力查询中的浮点运算快。因此计算效率远大于32倍。
结合倒排索引和乘积量化:先倒排索引横向切分缩小计算区域,然后通过乘积量化纵向压缩向量减小向量相似度计算代价,最终实现向量检索效率的极大提升。
假设 nlist=2000,常数C=5,最终优化效率: n l i s t C ∗ 128 ∗ N 4 ∗ N + 4 ∗ 256 ∗ 32 \frac{nlist}{C}*\frac{128*N}{4*N+4*256*32} Cnlist∗4∗N+4∗256∗32128∗N 大约有1200倍,降低三个数量级。
局部敏感性哈希
局部敏感哈希(Locality Sensitive Hashing, LSH) 不同于传统哈希尽量不产生碰撞,局部敏感哈希依赖碰撞来查找近邻。高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希值计算,使得他们哈希值有很大的概率是一样的,若两点之间的距离较远,他们哈希值相同的概率会很小。不同距离度量方式的哈希函数不同,不是所有距离度量(如内积)都能找到对应局部敏感哈希。
优点: 训练快、支持分批导入、索引占内存很小、检索快;
缺点: 召回率下降幅度较大;在亿级数据下速度有所下降(秒级);
使用情况: 候选向量库非常大,离线检索,内存资源比较稀缺的情况;
分层可导航小世界图* HNSW
分层小世界导航(Hierarchical Navigable Small World,HNSW)图算法
参数:构建图时每个点最多连接参数x个节点,x越大,构图越复杂,查询越精确,构建索引时间越慢,x取值在4~64;
优点: 基于图检索的改进方法,检索速度极快,10亿级别秒出检索结果,而且召回率几乎可以媲美Flat(暴搜),能达到惊人的97%。检索的时间复杂度为O(loglogn),几乎可以无视候选向量的量级。支持分批导入,极其适合线上任务,毫秒级别体验。
缺点: 构建索引极慢,占用内存极大(是Faiss中最大的)。
使用情况: 不在乎内存,并且有充裕的时间来构建索引;
跳表(SkipList)是一种简单高效的索引结构在 Redis、LevelDB 等系统中获得广泛应用,而 HNSW 本质上是跳表(SkipList)的思想迁移在图上的应用。
Reference
- 相似向量检索库-Faiss-简介及原理
- Faiss入门及应用经验记录
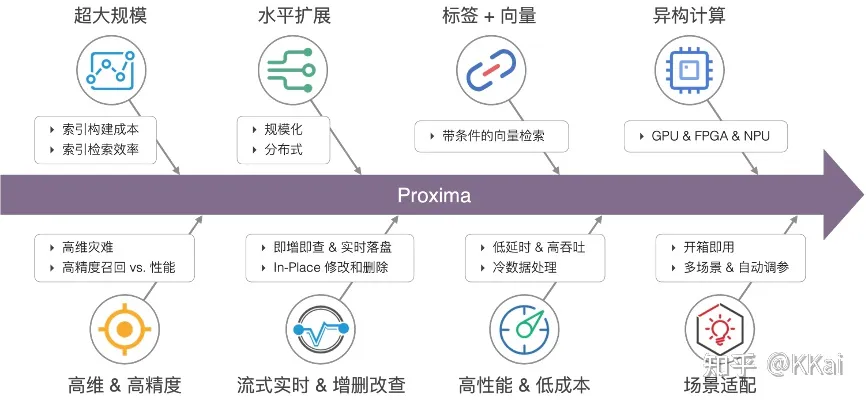
Proxima
Proxima 是阿里巴巴达摩院自研的向量检索内核。目前,其核心能力广泛应用于阿里和蚂蚁内众多业务,如淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等。同时 Proxima 还深度集成在云产品中,如阿里云 Hologres、开放搜索 OpenSearch、搜索引擎 ElasticSearch 和 ZSearch、离线引擎 MaxCompute (ODPS) 等,为其提供向量检索的能力。
- 智能开放搜索 OpenSearch - 阿里云
- 智能推荐 AIRec - 阿里云
Proxima 支持 ARM64、x86、GPU 等多种硬件平台,支持嵌入式设备和高性能服务器,从边缘计算到云计算全面覆盖,支持单片索引十亿级别下高准确率、高性能的索引构建和检索。
Proxima 应用举例
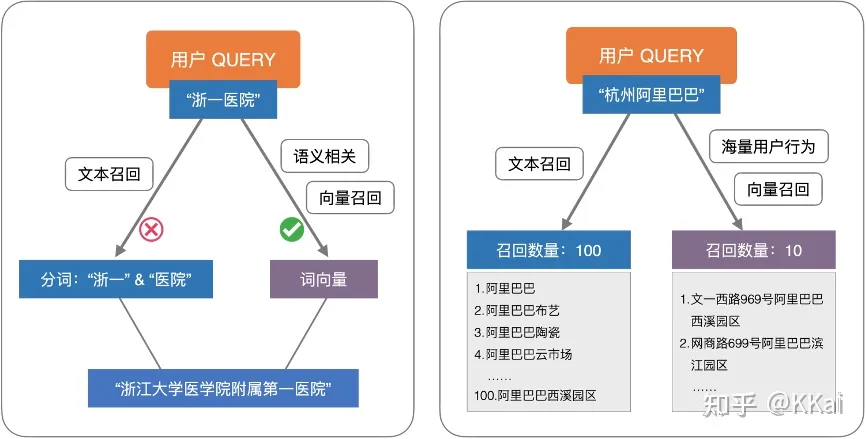
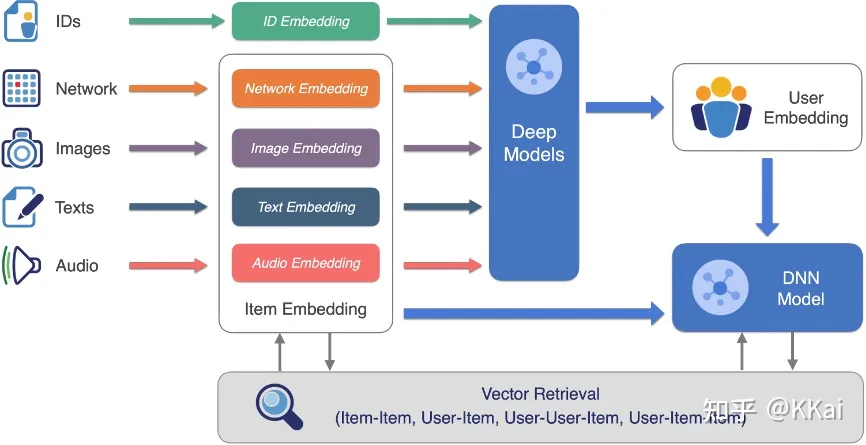
电商

向量召回在商品搜索多路召回中的应用:
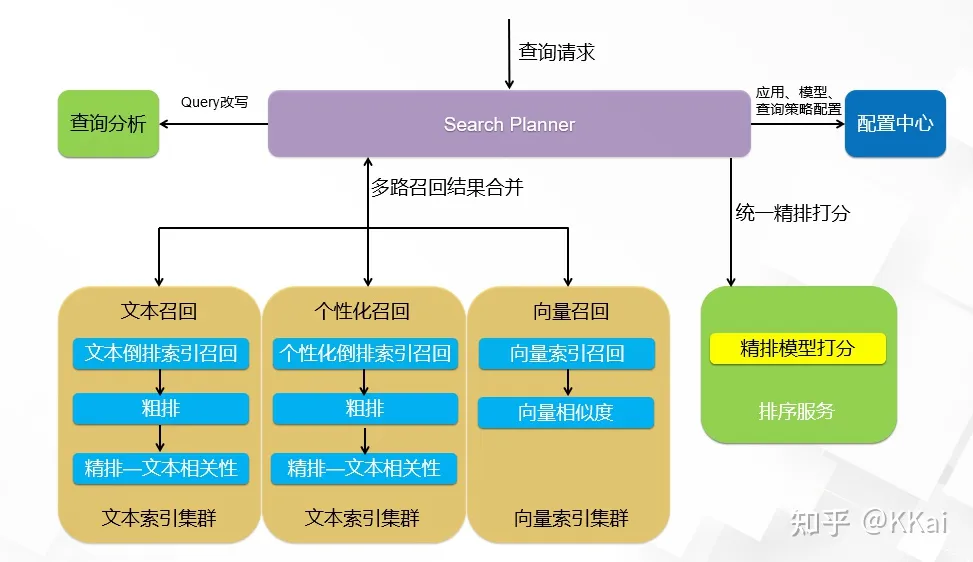
在线教育
拍照搜题解决方案:

为什么搜题要做多路召回? 教育拍照搜题场景相比网页/电商的文本搜索有显著差异:
- 搜索query特别长:常规检索term数上限30,搜题需要放到100;
- 搜索query是由拍照OCR识别之后得到的文本,关键term的识别错误会严重影响召回排序;
- 纯文本查询方案:OR逻辑查询latency高,计算消耗大;AND逻辑查询,无结果率高,整体准确性不如OR逻辑;
如何去兼顾计算消耗和搜索准确性 =》 文本向量检索 - 文本向量检索:通过文本向量检索召回,结合AND逻辑查询,做到latency和计算消耗低于OR逻辑的情况下准确性更高;向量召回采用 BERT 模型,其中针对教育搜题做的特别优化有:
- 达摩院自研的 StructBERT:针对教育行业优化
- 向量检索引擎基于 proxima:准确率和速度超过开源方案

向量检索的挑战和 Proxima 的优化
向量检索的挑战↓
- 分布式索引的构建和检索:向量检索目前多通过数据分片的方式实现水平扩展,然而过多的分片容易造成计算量的上升,从而导致检索效率的下降。在分布式方面,仍存在向量索引快速合并算法的难题,这导致了数据一旦分片之后,无法很好套用 Map-Reduce 计算模型合并成效率更高的索引。
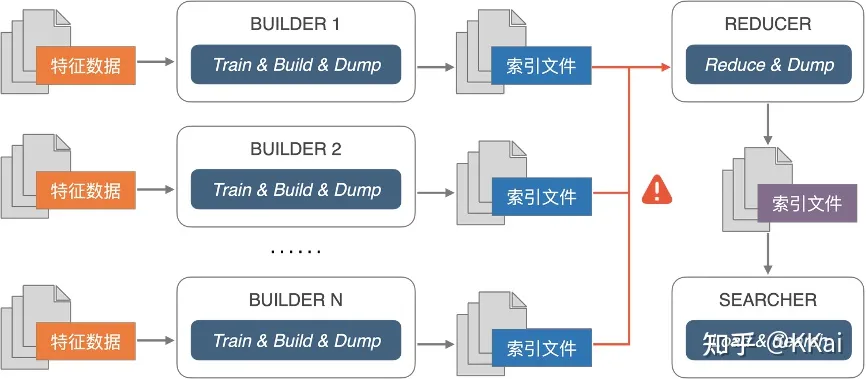
- 流式索引的在线更新:传统的检索方法能很方便的实现增查改删(CRUD)的操作,向量检索依赖数据分布和距离度量,部分方法还有数据集训练的要求,数据点的变更甚至动一发而牵全身。因此,要实现向量索引的从 0 到 1 的全流式构建,并满足即增即查、即时落盘、索引实时动态更新的要求,对算法和工程仍存在着一些挑战。
目前,对于非训练的检索方法,能较方便的支持全内存索引的在线动态新增和查询,然而面对即时落盘、内存不足、在线向量动态更新和删除等要求,操作成本很大,满足不了实时性。
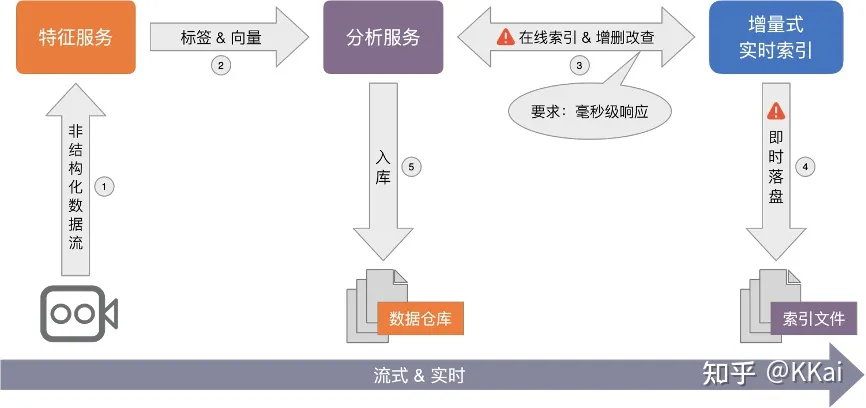
- 标签+向量的联合检索:需要同时满足标签检索条件和相似性检索的要求,如查询某些属性条件组合下相似性的图片等,称这种检索为“带条件的向量检索”。
目前,业内采用多路归并的方式,即分别检索标签和向量再进行结果合并,虽可以解决部分问题,但多数情况下结果不甚理想。

- 复杂的多场景适配:不同场景的算法超参数不一样,想让用户变得更简单,必然需要考虑场景适配的问题,主要包括数据适配(如:数据规模、数据分布、数据维度等)和需求适配(如:召回率、吞吐、时延、流式、实时性等)两方面。基于不同的数据分布,通过选择合适的算法和参数,以满足实际的业务需求。
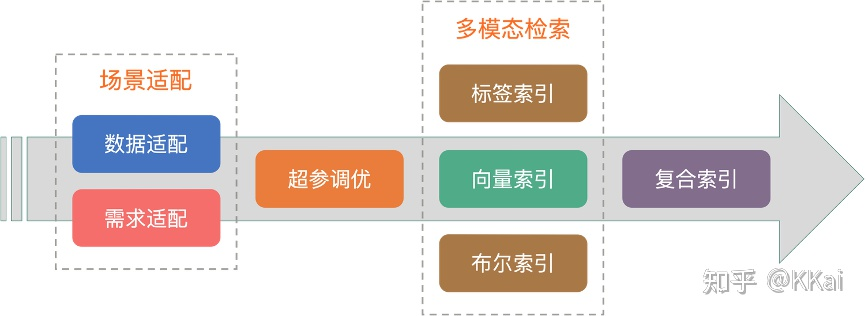
Proxima 针对上述问题都做了相关优化,笔者目前尚不清楚 Faiss 是否也做了相应处理(根据达摩院文章来看似乎并没有实现相关功能,欢迎读者补充~),因此考虑支持流式索引、带条件的向量检索等场景可以使用 Proxima。
Reference
- 达摩院自研向量检索引擎Proxima在行业搜索中的应用