StarGAN
论文:
《StarGAN: Unified Generative Adversarial Networksfor Multi-Domain Image-to-Image Translation》
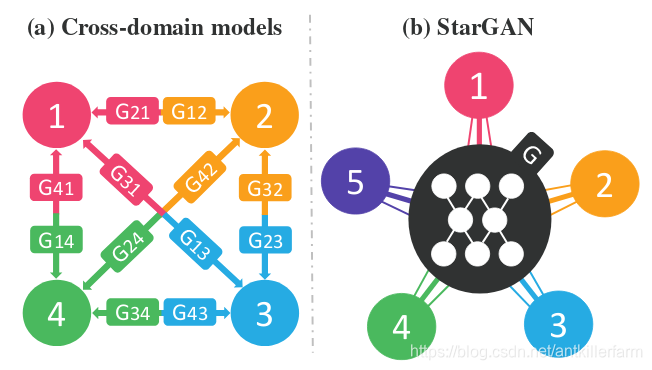
CycleGAN的局限在于:对于两个Domain之间的变换,需要两个G网络。可以想象,当Domain的数量上升时,所需G网络的个数将呈指数级增长。如上图左半部分所示。
StarGAN给出的办法是:所有的Domain共享一个G网络。如上图右半部分所示。
具体的操作如下图所示:
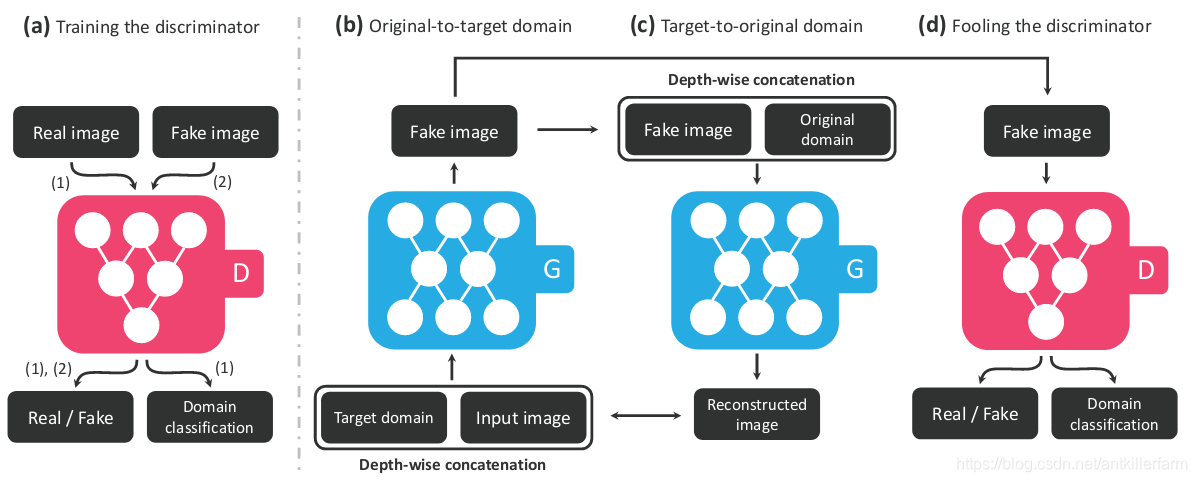
1.D网络除了常规的Real/Fake判别器之外,还有一个Domain分类器。
2.G网络的结构和CycleGAN类似,也包括了两部分: G X → Y G_{X\to Y} GX→Y和 G Y → X G_{Y\to X} GY→X。区别在于:后者的两个G网络是不同的网络,而前者是同一个网络。
3.既然G网络只有一个,那么如何完成Domain变换呢?答案就是:把目标Domain的信息也输进G网络中。
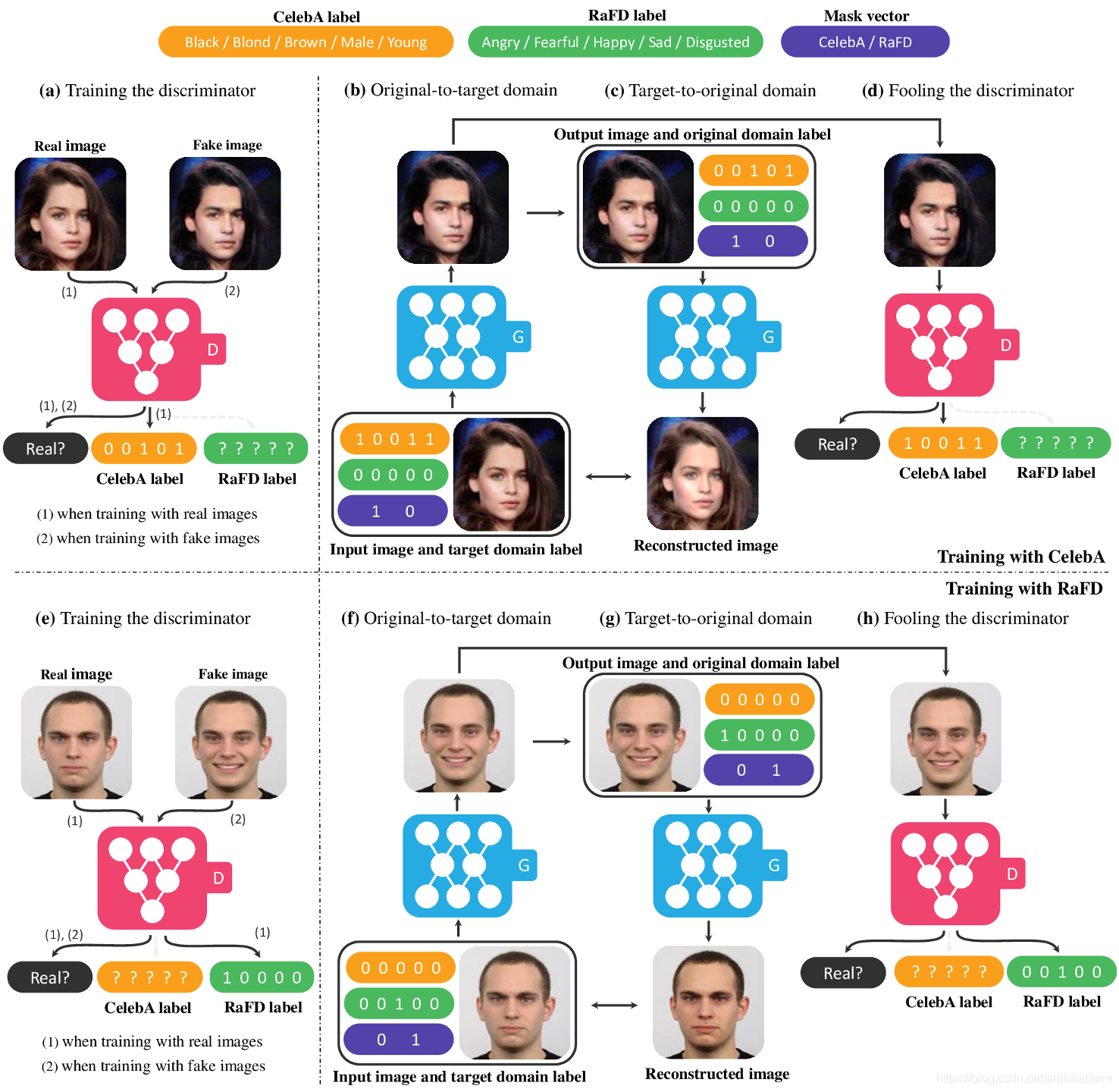
StarGAN不仅可在同一数据集中进行Domain变换,还可在不同数据集之间进行Domain变换。上图展示的是StarGAN在CelebA和RaFD数据集上的训练过程:
1.两个数据集的标签不是完全相同的。(实际上是完全不同,囧)
2.对标签进行编码。例如图中使用的Onehot编码。
3.**利用Mask区分是哪个数据集。**这一步是关键。
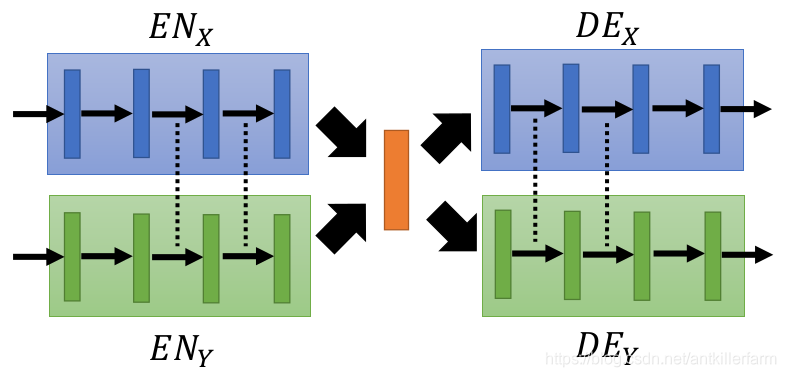
除此之外,同期的Couple GAN也采用了类似的设计。上图是Couple GAN的网络结构图,其中的虚线表示网络的参数是共享的。
参考:
https://mp.weixin.qq.com/s/rPDvLnG4MBDRUMCWs2fjcQ
最新StarGAN对抗生成网络实现多领域图像变换
https://mp.weixin.qq.com/s/CsIKES2APuxTP33RfX81fg
升级版StarGAN来袭!你想要的多目标域多风格图像变换它都有
InfoGAN
论文:
《InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets》
CGAN虽然已经有了些user control的能力,然而还不够强。比如人脸图片,user control的点(例如肤色、发型、表情等)就非常多,简单的标签不足以表达这么多含义。InfoGAN主要就是用来提升user control能力的。
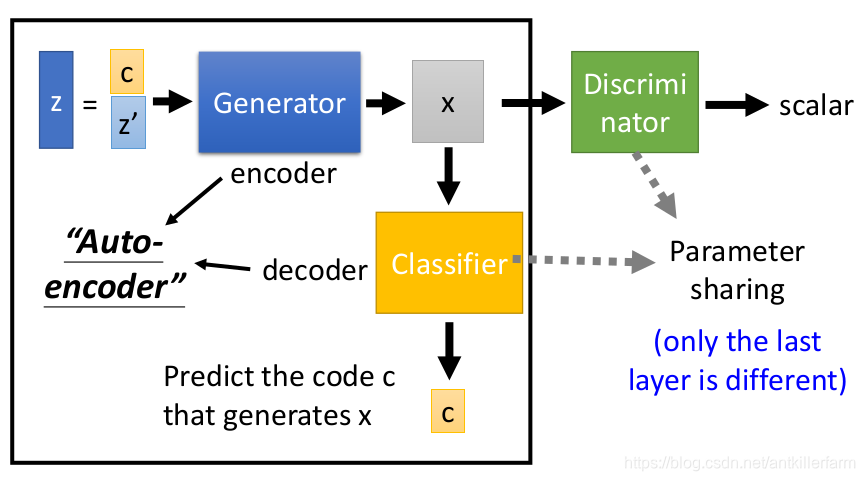
上图是InfoGAN的网络结构图。相比CGAN,它的改进在于:
1.将控制变量嵌入网络中。
2.Discriminator和Classifier共享大多数参数,仅最后一层不同。
参考:
https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247492415&idx=1&sn=a359e72ee99555f7a2fb4e21b2ad51db
InfoGAN:一种无监督生成方法
https://zhuanlan.zhihu.com/p/140544756
InfoGAN与betaVAE
ProGAN
论文:
《Progressive Growing of GANs for Improved Quality, Stability, and Variation》
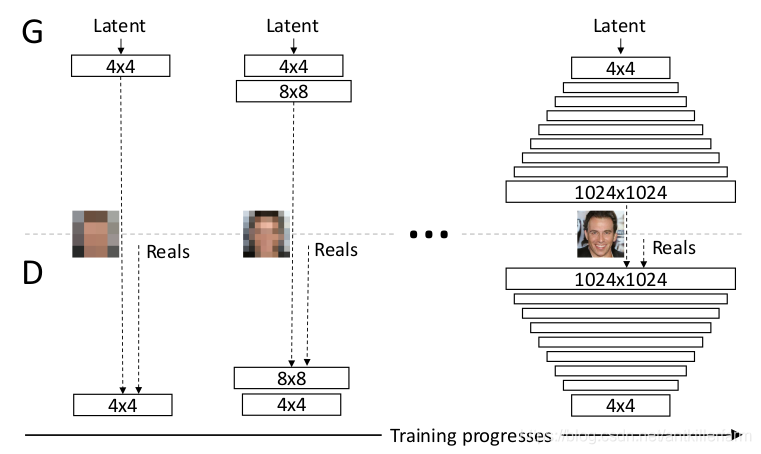
如果现在我们想生成超高分辨率的图像,譬如1024×1024图片,假设我们采用StackGAN或者是LapGAN的话,我们需要用到的 GANs结构会非常多,这样会导致网络深度巨大,训练起来非常慢。
为了解决这一问题,ProGAN(也称PGGAN)提出的想法是,我们只需要一个GANs就能产生1024×1024图片。但是一开始的时候GANs的网络非常浅,只能学习低分辨率(4x4)的图片生成,随着训练进行,我们会把GANs的网络层数逐渐加深,进而去学习更高分辨率的图片生成,最终不断的更新GANs,从而能学习到1024×1024分辨率的图片生成。
也就是说,PGGAN与StackGAN和LapGAN的最大不同在于,后两者的网络结构是固定的,但是PGGAN随着训练进行网络会不断加深,网络结构是在不断改变的。这样做最大的好处就是,PGGAN大部分的迭代都在较低分辨率下完成,训练速度比传统GANs提升了2-6倍。
当然,这也带来了另一个问题:网络结构切换的时候,Loss会发生抖动现象,论文中专门提出了如何smooth的方法,这里不再赘述。
参考:
https://mp.weixin.qq.com/s/X8osUSPROJqGVTvw0gieDQ
T2T:利用StackGAN和ProGAN从文本生成人脸
StyleGAN
StyleGAN是Nvidia Lab的Tero Karras的作品。(2018.12)
论文:
《A Style-Based Generator Architecture for Generative Adversarial Networks》
参考:
https://mp.weixin.qq.com/s/Pmr2yPZ3Mi32W5JuJCco_A
用英伟达StyleGAN生成老婆吧,他生成了一百多只明日香
https://mp.weixin.qq.com/s/i3lNcbOblgVKUTBtwKIFwg
AI秒造全球房源:StyleGAN快速生成假房子,连图说都配好了!
https://mp.weixin.qq.com/s/e1g1B-6bLe0IjNAHMJtGOw
英伟达发布最强图像生成器StyleGAN2,生成图像逼真到吓人
https://zhuanlan.zhihu.com/p/136392096
看GAN如何一步步控制图像生成风格?详解StyleGAN进化过程
BigGAN
论文:
《Large Scale GAN Training for High Fidelity Natural Image Synthesis》
参考:
https://mp.weixin.qq.com/s/b3EVdPGY2jxliwdbbB1kcQ
“史上最强GAN图像生成器”BigGAN的demo出了!
https://mp.weixin.qq.com/s/kSyXd5dgdEcqupDeouhObQ
BigGAN论文解读
https://mp.weixin.qq.com/s/akLvNQZMNTaVbkbUrZY4tw
史上最强图像生成器BigGAN变身DeepGAN?四倍深度实现更强效果
https://mp.weixin.qq.com/s/jglebP4Zb9rZtb2EhWiQDA
BigGAN被干了!DeepMind发布LOGAN:FID提升32%,华人一作领衔
FUNIT
https://mp.weixin.qq.com/s/KupmZpMi1A46f5_NKbTU2A
深入理解风格迁移三部曲(一)–UNIT
https://mp.weixin.qq.com/s/3hv44bkXYHn2wN_2OZmhxA
四大指标超现有模型!少样本的无监督图像翻译效果逆天(FUNIT)
https://mp.weixin.qq.com/s/H0kl1i4P3Dak2COdzQNG4A
一图生万物!英伟达推超强图像转换神器,小样本一秒猫变狗(FUNIT)
https://mp.weixin.qq.com/s/isrB3yda9sGgbOb4dBXMrQ
更自由的GAN图像联想:无监督跨类的图像转换模型FUNIT,英伟达&康奈尔大学
https://mp.weixin.qq.com/s/nAaKnI1ADKfeQ8UA_VP0Fw
FUNIT
条件VAE
最后,因为目前的VAE是无监督训练的,因此很自然想到:如果有标签数据,那么能不能把标签信息加进去辅助生成样本呢?这个问题的意图,往往是希望能够实现控制某个变量来实现生成某一类图像。当然,这是肯定可以的,我们把这种情况叫做Conditional VAE,或者叫CVAE。正如在GAN中我们有个CGAN。
但是,CVAE不是一个特定的模型,而是一类模型,总之就是把标签信息融入到VAE中的方式有很多,目的也不一样。这里基于前面的讨论,给出一种非常简单的CVAE。
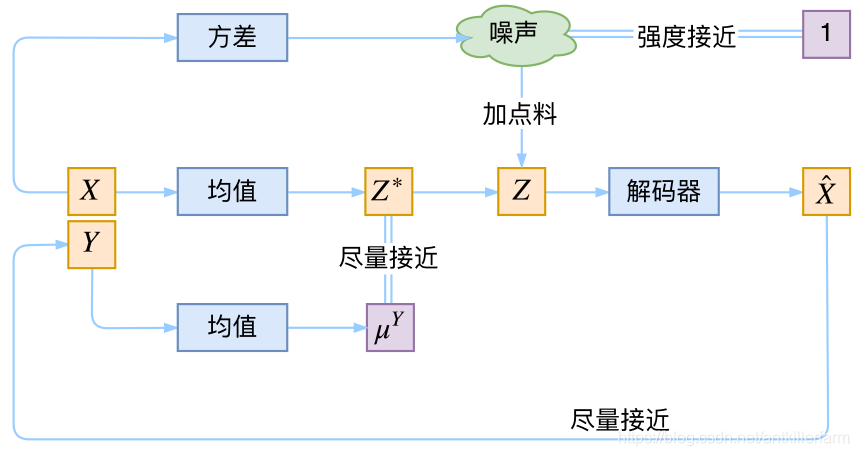
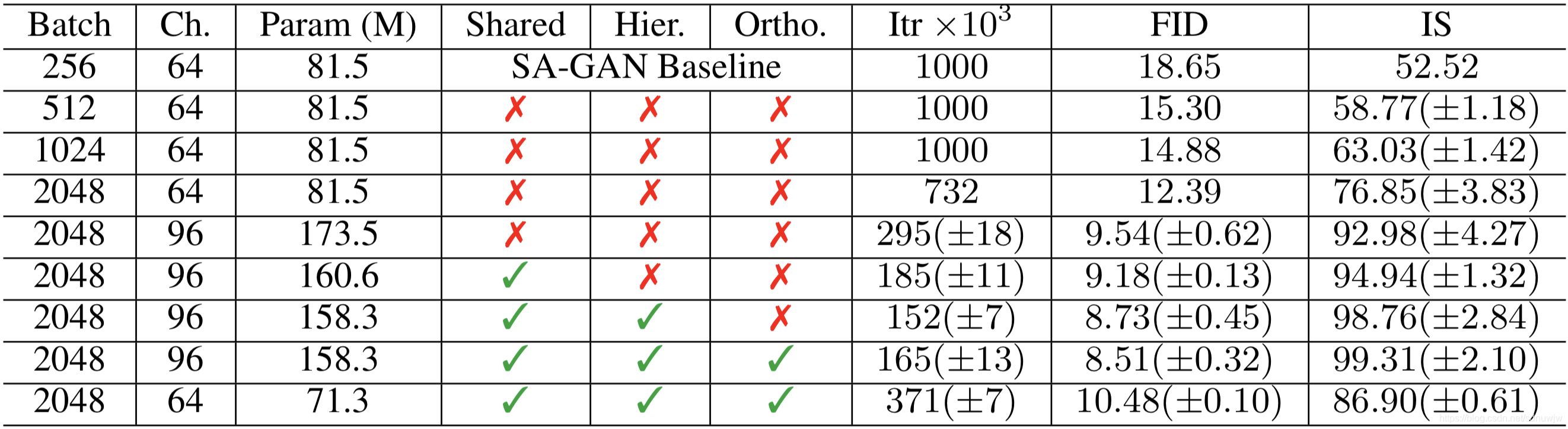
在前面的讨论中,我们希望X经过编码后,Z的分布都具有零均值和单位方差,这个“希望”是通过加入了KL loss来实现的。如果现在多了类别信息Y,我们可以希望同一个类的样本都有一个专属的均值 μ Y \mu^Y μY(方差不变,还是单位方差),这个 μ Y \mu^Y μY让模型自己训练出来。这样的话,有多少个类就有多少个正态分布,而在生成的时候,我们就可以通过控制均值来控制生成图像的类别。事实上,这样可能也是在VAE的基础上加入最少的代码来实现CVAE的方案了,因为这个“新希望”也只需通过修改KL loss实现:
L μ , σ 2 = 1 2 ∑ i = 1 d [ ( μ ( i ) − μ ( i ) Y ) 2 + σ ( i ) 2 − log σ ( i ) 2 − 1 ] \mathcal{L}_{\mu,\sigma^2}=\frac{1}{2} \sum_{i=1}^d\Big[\big(\mu_{(i)}-\mu^Y_{(i)}\big)^2 + \sigma_{(i)}^2 - \log \sigma_{(i)}^2 - 1\Big] Lμ,σ2=21i=1∑d[(μ(i)−μ(i)Y)2+σ(i)2−logσ(i)2−1]
参考:
https://mp.weixin.qq.com/s/1EvILWkBHKu2RV_xBuU8VQ
条件变分自编码器(CVAE)
https://mp.weixin.qq.com/s/hi0cVv4danL8IXT2BGxXbw
条件变分自动编码器CVAE:基本原理简介和keras实现
VAE的发展
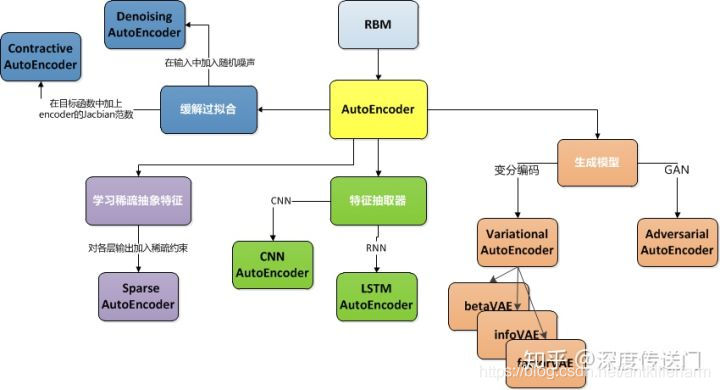
https://zhuanlan.zhihu.com/p/68903857
一文看懂AutoEncoder模型演进图谱
VAE vs GAN
VAE是直接计算生成图片和原始图片的均方误差而不是像GAN那样去对抗来学习,这就使得生成的图片会有点模糊。但是VAE的收敛性要优于GAN。因此又有GAN hybrids:一方面可以提高VAE的采样质量和改善表示学习,另一方面也可以提高GAN的稳定性和丰富度。
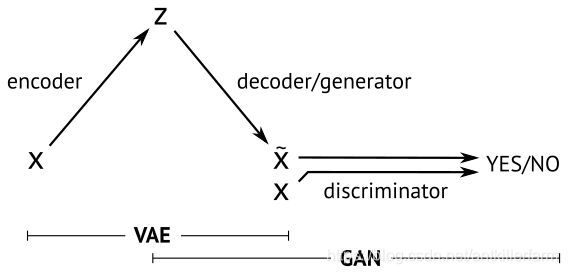
上图给出了VAE和GAN的联系和区别。
无论是VAE还是GAN,我们在接触一个新模型的时候都需要注意以下几点:
1.网络结构和训练流程。
2.Loss。
3.随机性的引入方法。
其中,第3点是生成模型特有的,必须加倍重视。
参考:
https://mp.weixin.qq.com/s/d_P-4uQx0kC2w6J69OZIAw
Deepmind研究科学家最新演讲:VAEs and GANs
https://mp.weixin.qq.com/s/9N_3JkNEPdXQgFn0S7MqnA
走进深度生成模型:变分自动编码器(VAE)和生成对抗网络(GAN)
AAE
论文:
《Adversarial Autoencoders》
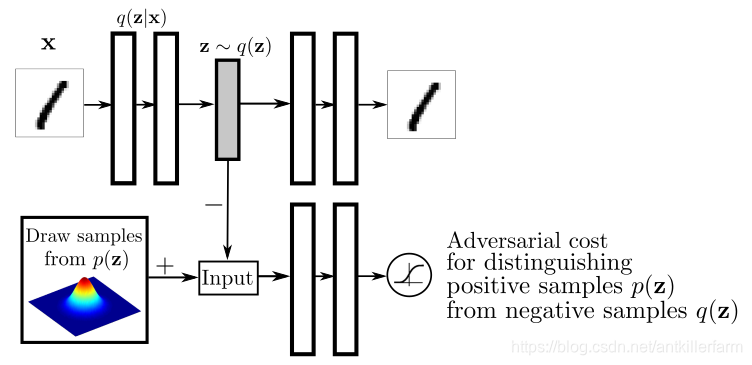
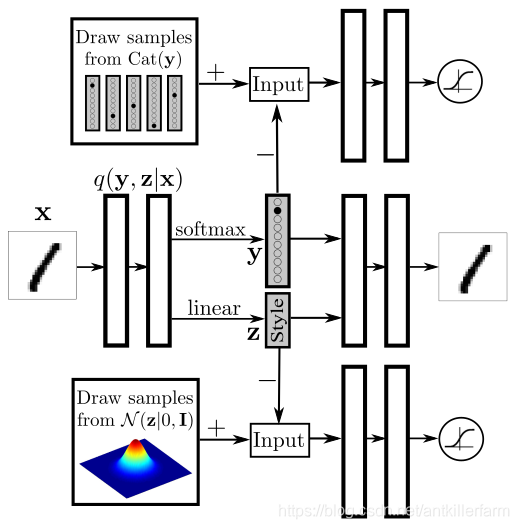
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sDkgkR8P-1593395747976)(/images/img3/AAE_3.png)]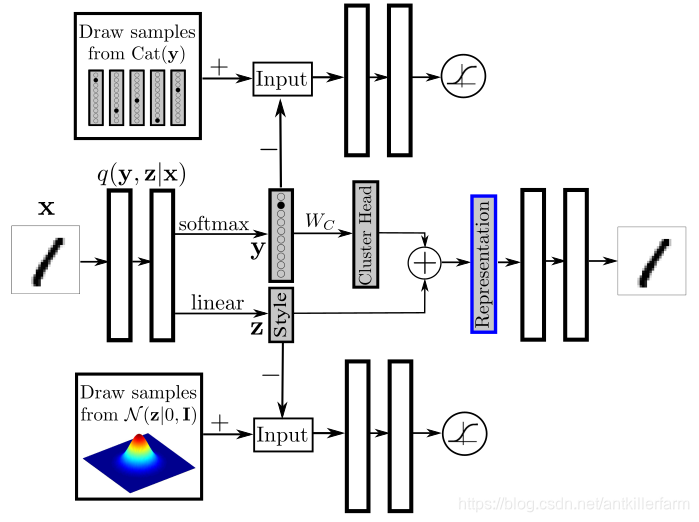
参考:
http://kissg.me/2017/12/17/papernotes03/
AAE, ALI, BiGAN
VAE-GAN
论文:
《Autoencoding beyond pixels using a learned similarity metric》
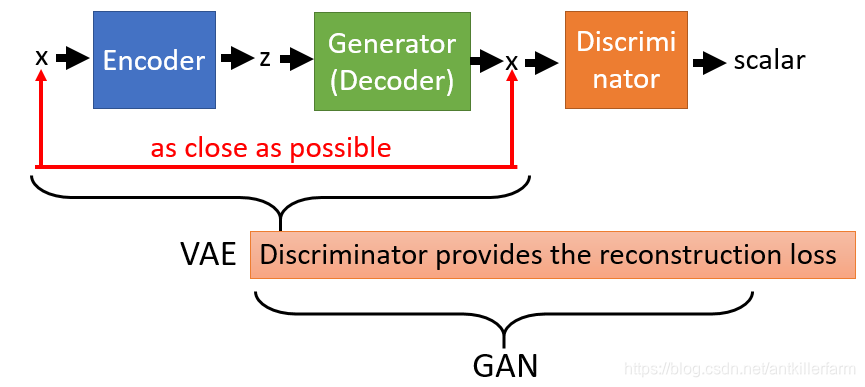
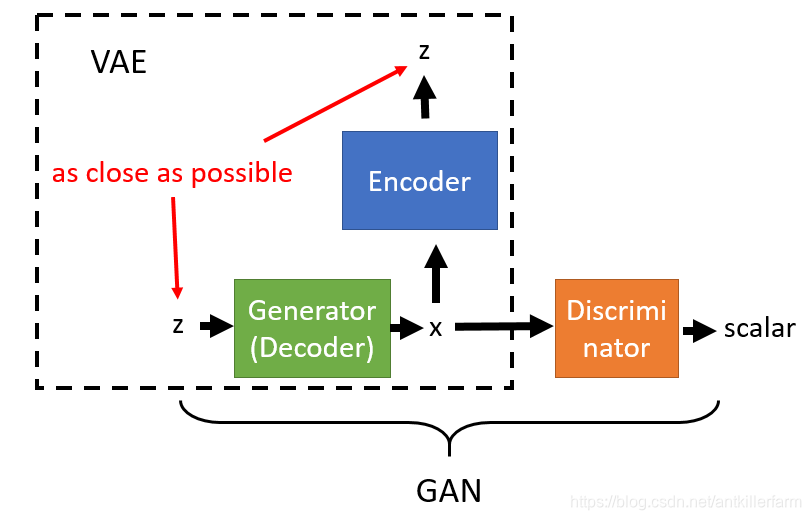
而关于VAEGAN,有趣的一点是,我们不仅可以用GANs来提升VAE,也可以用VAE来提升GANs。如果是被用作后者的话,“GANVAE”其实就等效为CycleGAN的一部分。
参考:
https://mp.weixin.qq.com/s/fzadP8NwPTxuhEB0O4GU8g
漫谈生成模型,从AE到CVAE-GAN