序
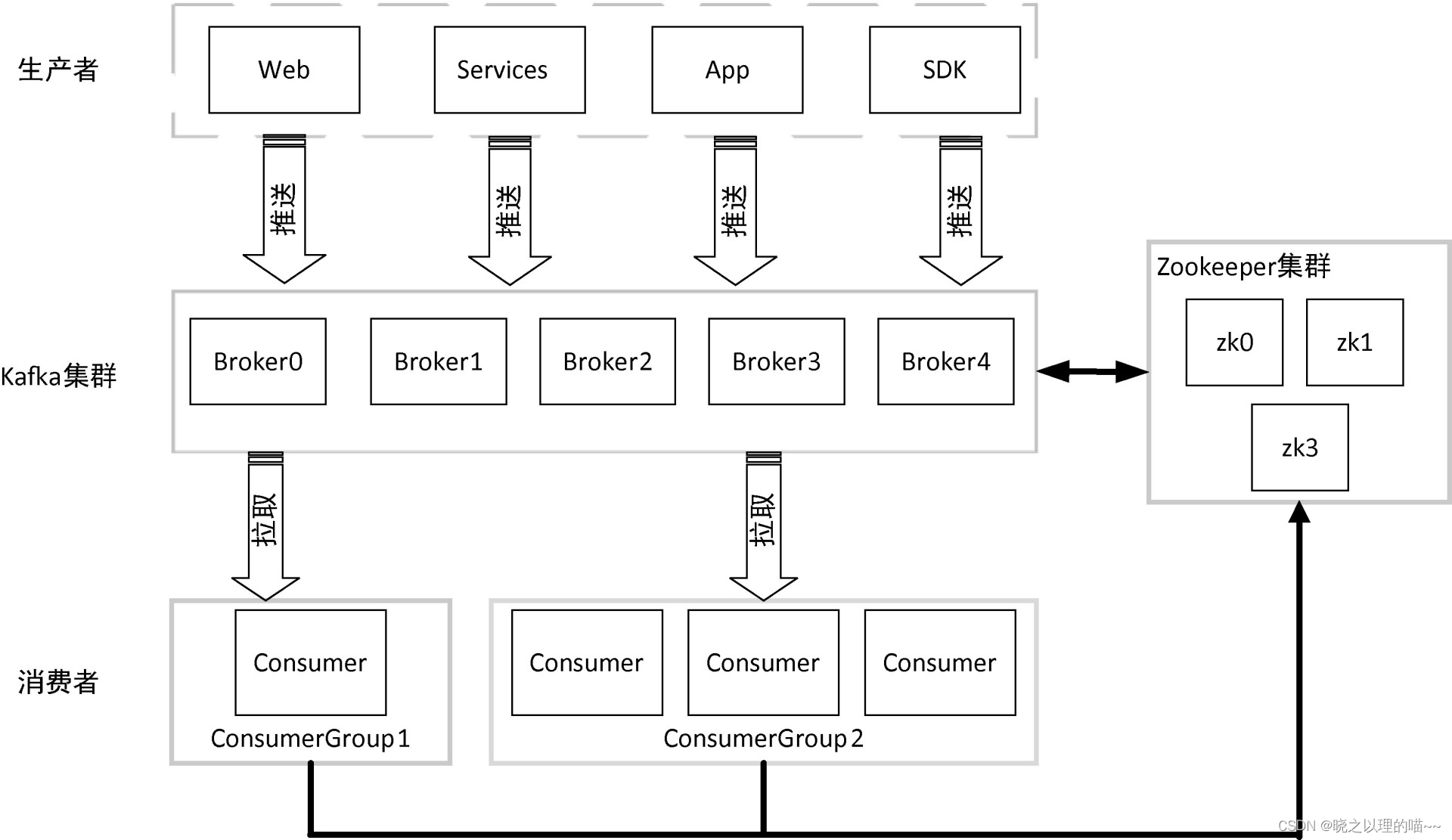
在学习一门新技术之前,我们需要先去了解一下这门技术的具体应用场景,使用它能够做什么,能够达到什么目的,学习kafka的初衷是用作消息队列;但是还可以使用Kafka Stream进行一些实时的流计算,多用于大数据处理;也可以做日志收集汇总、网站活动跟踪等任务。
消息队列
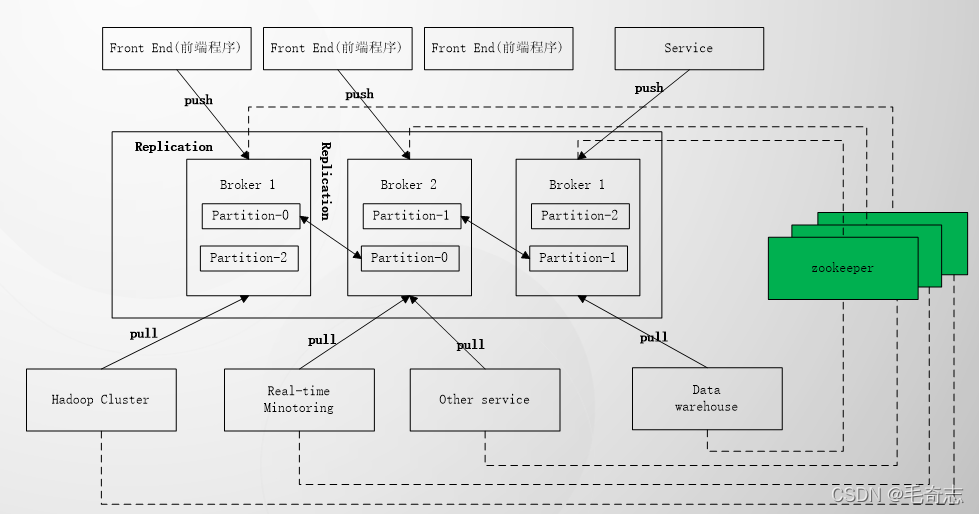
kafka可以很好的替代一些传统的消息系统,kafka具有更好的吞吐量,内置的分区使kafka具有更好的容错和伸缩性,这些特性使它可以替代传统的消息系统,成为大型消息处理应用的首选方案。
场景:异步、解耦、削峰填谷
- 生成订单:给不同的产品业务线分配同一个topic的不同partition,用户下单后根据订单类型发送到对应的partition
- 消息通知:用户登录后计算积分
-
消息生产者
public static void main(String[] args) throws Exception {Properties prop = new Properties();prop.put("bootstrap.servers", "127.0.0.1:9092");prop.put("acks", "all");prop.put("retries", "0");// 缓冲区大小prop.put("batch.size", "10");prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(prop);for (int i = 0; i < 101; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("my_topics", "value_" + i);// 阻塞到消息发送完成producer.send(record).get();}// 刷新缓冲区,发送到分区,并清空缓冲区// producer.flush();// 关闭生产者,会阻塞到缓冲区内的数据发送完producer.close();// producer.close(Duration.ofMillis(1000)); }生产者发送消息是先将消息放到缓冲区,当缓冲区存满之后会自动flush,或者手动调用flush()方法
-
消息消费者
public static void main(String[] args) {Properties properties = new Properties();properties.put("bootstrap.servers", "127.0.0.1:9092");properties.put("group.id", "cc_consumer");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);// 指定topicconsumer.subscribe(Arrays.asList("my_topics"));// 指定topic的partition// TopicPartition partition0 = new TopicPartition("my_topics", 10);// consumer.assign(Arrays.asList(partition0));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.toString());}}} finally {consumer.close(Duration.ofMillis(2000));} }
流计算
[todo]
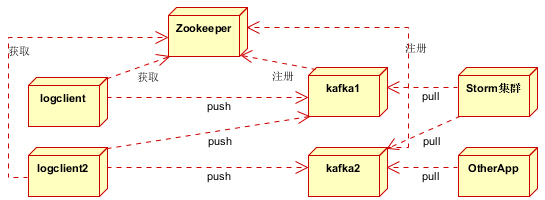
日志收集
应用程序的日志可以通过log4j收集日志信息,并将日志直接打到kafka中:客户端—>应用—>kafka
SpringBoot中默认使用的是logback,所以要在引入SpringBoot的jar包时排除掉logback的jar包
日志消息发送有同步和异步两种方式,由KafkaAppender中的
syncSend属性决定,默认为true(同步)> <Kafka name="KAFKA-LOGGER" topic="cc_log_test" syncSend="false"> >
- pom.xml
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-logging</artifactId></exclusion></exclusions>
</dependency>
<!-- springboot 1.3.x之前版本是log4j,之后版本都是log4j2 -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
- log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="off"><Properties></Properties><Appenders><Console name="STDOUT" target="SYSTEM_OUT"><PatternLayout pattern="%d %p %c{1.} %t %m%n"/></Console><!--kafka topic--><Kafka name="KAFKA-LOGGER" topic="my_topics"><!--JsonLayout:日志格式为json,方便在ES中处理--><JsonLayout/><!--kafka server的ip:port--><Property name="bootstrap.servers">127.0.0.1:9092</Property><Property name="retries">3</Property><Property name="linger.ms">1000</Property><Property name="buffer.memory">10485760</Property></Kafka><Async name="ASYNC-KAFKA-LOGGER"><AppenderRef ref="KAFKA-LOGGER"/><LinkedTransferQueue/></Async></Appenders><Loggers><!--日志级别大于info都会被记录到Kafka--><Logger name="cc.kevinlu.springbootkafka.controller.MessageController" level="info"additivity="false"><AppenderRef ref="KAFKA-LOGGER"/></Logger><!-- Root表示所有Logger用Root中的Appender打印日志 --><Root level="info"><AppenderRef ref="STDOUT"/></Root></Loggers>
</Configuration>
- code
@GetMapping("/log")
public String sendLog() {for (int i = 0; i < 10; i++) {log.info("kafka log i = " + i);}return "success";
}
- consumer视图

网站活动跟踪
-
前端Nodejs控制
Node接入kafka需要使用kafka-node库,下面是网上的例子
var kafka = require('kafka-node'),Producer = kafka.Producer,client = new kafka.KafkaClient({kafkaHost: 'localhost:9092'}); /*** 定义生产类* partitionerType 定义* 0:默认模式 只产生数据在第一个分区* 1:随机分配,在分区个数内,随机产生消息到各分区* 2:循环分配,在分区个数内,按顺序循环产生消息到各分区 */ var producerOption = {requireAcks: 1,ackTimeoutMs: 100,partitionerType: 0 //默认为第一个分区 }; var producer = new Producer(client,producerOption); /*** TOPIC的创建需要在命令行进行创建,以便指定分区个数以及备份个数* PS:kafka-node的创建topic不行,不能创建分区* 产生消息,如果不指定partition* 则根据 partitionerType 的值来指定发送数据到哪个分区* 我们创建的topic-test-one只有一个分区,所以只能产生数据到第1个分区(下标0),否则不会生产数据*/ function getPayloads(){return [{topic:"topic-test-one",messages:JSON.stringify({"name":"jack","age":"120"}),partition:0}]; }producer.on("ready",function(){setInterval(function(){producer.send(getPayloads(),function(err,data){if(!err){console.log("send message complete!data:"+JSON.stringify(data),new Date());}});},1000); });producer.on('error', function (err) {console.log("send message error!\r\n"+err);}) -
后端日志控制
后端也可以使用log4j的日志系统来完成,拦截所有需要监控的api请求,使用log4j输出日志到kafka队列中,和上述日志收集方法相同。若同一个应用中需要通过日志输出到kafka的多个topic中,可以使用log4j的Marker标记来区分,配置如下:
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="off"><Properties></Properties><Appenders><Console name="STDOUT" target="SYSTEM_OUT"><PatternLayout pattern="%d %p %c{1.} %t %m%n"/></Console><!-- 日志收集 --><Kafka name="KAFKA-LOGGER" topic="cc_log_test" syncSend="false"><JsonLayout/><Property name="bootstrap.servers">127.0.0.1:9092</Property><Property name="retries">3</Property><Property name="linger.ms">1000</Property><Property name="buffer.memory">10485760</Property><Filters><!-- 通过Marker过滤消息 --><MarkerFilter marker="Kafka" onMatch="ACCEPT" onMismatch="DENY"/></Filters></Kafka><!-- 轨迹跟踪 --><Kafka name="KAFKA-TRACK-LOGGER" topic="cc_test1" syncSend="false"><JsonLayout/><Property name="bootstrap.servers">127.0.0.1:9092</Property><Property name="retries">3</Property><Property name="linger.ms">1000</Property><Property name="buffer.memory">10485760</Property><Filters><!-- 通过Marker过滤消息 --><MarkerFilter marker="Track" onMatch="ACCEPT" onMismatch="DENY"/></Filters></Kafka><Async name="ASYNC-KAFKA-LOGGER"><AppenderRef ref="KAFKA-LOGGER"/><AppenderRef ref="KAFKA-TRACK-LOGGER"/><LinkedTransferQueue/></Async></Appenders><Loggers><Logger name="cc.kevinlu.springbootkafka.controller" level="info"additivity="false"><AppenderRef ref="KAFKA-LOGGER"/><AppenderRef ref="KAFKA-TRACK-LOGGER"/></Logger><Root level="info"><AppenderRef ref="STDOUT"/></Root></Loggers> </Configuration>private final static Marker KAFKA_MARKER = MarkerManager.getMarker("Kafka"); private final static Marker KAFKA_TRACK_MARKER = MarkerManager.getMarker("Track");@GetMapping("/log") public String sendLog() {// 轨迹跟踪log.info(KAFKA_TRACK_MARKER, "send async message!");for (int i = 0; i < 10; i++) {// 日志收集log.info(KAFKA_MARKER, "kafka log i = {}", i);}return "success"; } -
前端+后端组合
后端提供API供前端传递轨迹,后端接收到请求之后将消息同步到kafka中。