文章目录
- NLTK的分类器
- 有监督分类
- 1贝叶斯分类器:以性别鉴定为例
- 定义特征提取器与特征选择
- 过拟合:当特征过多
- 错误分析
- 步骤
- 注意:
- 例子:性别鉴定
- 例子:电影评论情感分析
- 2“决策树”分类器:以词性标注为例
- 例子:通过观察后缀进行词性标注
- 3序列分类器:以词性标注为例
- ①贪婪序列分类
- 例子:利用上下文的词性标注
- ②转型联合分类
- ③@为所有可能的序列打分
- 隐马尔可夫模型
- 最大熵马尔可夫模型
- 线性链条件随机场模型
- 有监督分类的其他例子
- 评估
- 准确度
- 混淆矩阵
- 三种分类器的总结
https://www.cnblogs.com/AsuraDong/p/7020304.html
https://blog.csdn.net/weixin_37887248/article/details/81633550
https://blog.csdn.net/weixin_37251044/article/details/90452178
NLTK的分类器
from nltk.classify.api import ClassifierI, MultiClassifierI
from nltk.classify.megam import config_megam, call_megam
from nltk.classify.weka import WekaClassifier, config_weka
from nltk.classify.naivebayes import NaiveBayesClassifier
from nltk.classify.positivenaivebayes import PositiveNaiveBayesClassifier
from nltk.classify.decisiontree import DecisionTreeClassifier
from nltk.classify.rte_classify import rte_classifier, rte_features, RTEFeatureExtractor
from nltk.classify.util import accuracy, apply_features, log_likelihood
from nltk.classify.scikitlearn import SklearnClassifier
from nltk.classify.maxent import (MaxentClassifier,BinaryMaxentFeatureEncoding,
TypedMaxentFeatureEncoding,ConditionalExponentialClassifier)
有监督分类
分类 是为给定的输入选择正确的类标签的任务。在基本的分类任务中,每个输入被认为是与所有其它输入隔离的,并且标签集是预先定义的。这里是分类任务的一些例子:
判断一封电子邮件是否是垃圾邮件。
从一个固定的主题领域列表中,如“体育”、“技术”和“政治”,决定新闻报道的主题是什么。
决定词bank给定的出现是用来指河的坡岸、一个金融机构、向一边倾斜的动作还是在金融机构里的存储行为。
一个分类称为有监督的 ,如果它的建立基于训练语料的每个输入包含正确标签。
有监督分类:
(a)在训练过程中,特征提取器用来将每一个输入值转换为特征集。这些特征集捕捉每个输入中应被用于对其分类的基本信息,我们将在下一节中讨论它。特征集与标签的配对被送入机器学习算法,生成模型。
(b)在预测过程中,相同的特征提取器被用来将未见过的输入转换为特征集。之后,这些特征集被送入模型产生预测标签。

基本的分类任务有许多有趣的变种。
- 在多类分类中,每个实例可以分配多个标签
- 在开放性分类中,标签集是事先没有定义的;
- 在序列分类中,一个输入列表作为一个整体分类。
1贝叶斯分类器:以性别鉴定为例
- nltk自带的朴素贝叶斯分类器 NaiveBayesClassifier 生成分类器。
- 可以用nltk.classify.accuracy (分类器,测试集) 测试准确度。
- 当训练大的语料库的时候,链表会占用很大内存。使用函数nltk.classify.apply_features ,返回一个行为像一个列表而不会在内存存储所有特征集的对象
定义特征提取器与特征选择
创建一个分类器的第一步是决定输入的什么样的特征是相关的,以及如何为那些特征编码。
大多数分类方法要求特征使用简单的类型进行编码,如布尔类型、数字和字符串。但要注意仅仅因为一个特征是简单类型,并不一定意味着该特征的值易于表达或计算,它可以用非常复杂的和有信息量的值作为特征。
- 使用函数nltk.classify.apply_features,返回一个行为像一个列表而不会在内存存储所有特征集的对象。
使用精心构建的基于对当前任务的透彻理解的特征,通常会显著提高收益。
过拟合:当特征过多
你要用于一个给定的学习算法的特征的数目是有限的——如果你提供太多的特征,那么该算法将高度依赖你的训练数据的特性,而一般化到新的例子的效果不会很好。这个问题被称为过拟合,当运作在小训练集上时尤其会有问题。
错误分析
一旦初始特征集被选定,完善特征集的一个非常有成效的方法是错误分析。首先,我们选择一个开发集,包含用于创建模型的语料数据。然后将这种开发集分为训练集和开发测试集。
- 开发集:
- 训练集:负责开发
- 开发测试集:负责错误分析
- 测试集:负责最终评估

步骤
1使用训练集训练一个模型
2使用开发测试集,我们可以生成一个分类器预测时的错误列表。
3然后检查个别错误案例,在那里该模型预测了错误的标签,尝试确定什么额外信息将使其能够作出正确的决定(或者现有的哪部分信息导致其做出错误的决定)。然后可以相应的调整特征集。
可以使用show_most_informative_features() 来找出哪些特征是分类器发现最有信息量的
4使用新的特征提取器重建分类器,往往可以看到测试数据集上的性能提高了。
注意:
- 这个错误分析过程可以不断重复,检查存在于由新改进的分类器产生的错误中的模式。每一次错误分析过程被重复,我们应该选择一个不同的开发测试/训练分割 ,以确保该分类器不会开始反映开发测试集的特质。
- 但是,一旦我们已经使用了开发测试集帮助我们开发模型,关于这个模型在新数据会表现多好,我们将不能再相信它会给我们一个准确地结果。因此,保持测试集分离、未使用过 ,直到我们的模型开发完毕是很重要的。在这一点上,我们可以使用测试集评估模型在新的输入值上执行的有多好。
例子:性别鉴定
在这个例子中,我们一开始只是寻找一个给定的名称的最后一个字母。我们看到,男性和女性的名字有一些鲜明的特点。以a,e和i结尾的很可能是女性,而以k,o,r,s和t结尾的很可能是男性。
例子:电影评论情感分析
我们选择电影评论语料库,将每个评论归类为正面或负面。
我们一开始构建一个整个语料库中前2000个最频繁词的列表,定义一个特征提取器,简单地检查这些词是否在一个给定的文档中。
2“决策树”分类器:以词性标注为例
这里的分类器是决策树分类器:DecisionTreeClassifier。
可以通过==classifier.pseudocode(depth = ?) == 这查询深度为depth的树,并且打印出来。
顺便表示,我再走下面的程序的时候,电脑炸了。建议在集群上运行。
例子:通过观察后缀进行词性标注
-我们建立了一个正则表达式标注器,通过查找词内部的组成,为词选择词性标记。然而,这个正则表达式标注器是手工制作的。我们可以训练一个分类器来算出哪个后缀最有信息量。
- 决策树模型的一个很好的性质是它们往往很容易解释,我们甚至可以指示NLTK将它们以伪代码形式输出
3序列分类器:以词性标注为例
上下文语境特征往往提供关于正确标记的强大线索——例如,标注词"fly",如果知道它前面的词是“a”将使我们能够确定它是一个名词,而不是一个动词。
不是只传递已标注的词,我们将传递整个(未标注的)句子,以及目标词的索引。
如果它没有获得前面这个词的词性标记,就无法得出下一个词的词性标记。
在一般情况下,简单的分类器总是将每一个输入与所有其他输入独立对待。
但是有很多情况,如词性标注,我们感兴趣的是解决彼此密切相关的分类问题。
为了捕捉相关的分类任务之间的依赖关系,我们可以使用联合分类器模型 ,收集有关输入,选择适当的标签。
在词性标注的例子中,各种不同的序列分类器模型可以被用来为一个给定的句子中的所有的词共同选择词性标签。
①贪婪序列分类
ConsecutivePosTagger()
一种序列分类器策略,称为连续分类或贪婪序列分类
- 第一个输入找到最有可能的类标签,
- 然后使用这个问题的答案帮助找到下一个输入的最佳的标签。
- 这个过程可以不断重复直到所有的输入都被贴上标签。
这是二元标注器 采用的方法,它一开始为句子的第一个词选择词性标记,然后为每个随后的词选择标记,基于词本身和前面词的预测的标记
例子:利用上下文的词性标注
首先,我们必须扩展我们的特征提取函数使其具有参数history,它提供一个我们到目前为止已经为句子预测的标记的列表。history中的每个标记对应sentence中的一个词。但是请注意,history将只包含我们已经归类的词的标记,
在训练中,我们使用已标注的标记为征提取器提供适当的历史信息,但标注新的句子时,我们基于标注器本身的输出产生历史信息。
②转型联合分类
贪婪序列分类的一个缺点是我们的决定一旦做出无法更改。例如,如果我们决定将一个词标注为名词,但后来发现的证据表明应该是一个动词,就没有办法回去修复我们的错误。这个问题的一个解决方案是采取转型策略。
工作原理是为输入的标签创建一个初始值,然后反复提炼那个值,尝试修复相关输入之间的不一致。
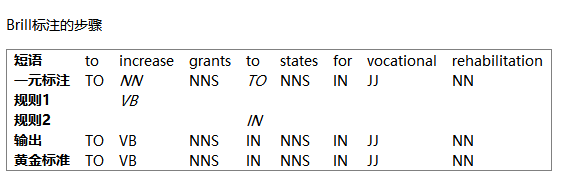
Brill标注器 是这种策略的一个很好的例子。
③@为所有可能的序列打分
隐马尔可夫模型
为词性标记所有可能的序列打分,选择总得分最高的序列。
隐马尔可夫模型类似于连续分类器,它不光看输入也看已预测标记的历史。然而,不是简单地找出一个给定的词的单个最好的标签,而是为标记产生一个概率分布。然后将这些概率结合起来计算标记序列的概率得分,最高概率的标记序列会被选中。
不幸的是,可能的标签序列的数量相当大。给定30 个标签的标记集,有大约600 万亿(3010)种方式来标记一个10个词的句子。为了避免单独考虑所有这些可能的序列,隐马尔可夫模型要求特征提取器只看最近的标记(或最近的n个标记,其中n是相当小的)。
由于这种限制,它可以使用动态规划,有效地找出最有可能的标记序列。特别是,对每个连续的词索引i,每个可能的当前及以前的标记都被计算得分。
最大熵马尔可夫模型
线性链条件随机场模型
采用这种同样基础的方法,标记序列打分用的是不同的算法
有监督分类的其他例子
- 句子分割
- 识别对话行为类型
- 识别文字蕴含
评估
准确度
评估最简单的度量就是准确度,即:accuracy()函数。除了这个,精确度、召回率和F-度量值也确实影响了准确度。
- 精确度:发现项目中多少是相关的。TP/(TP+FP),nltk.classify.accuracy()
- 召回率:表示相关项目发现了多少。TP(TP+FN)
- F-度量值:精确度和召回率的调和平均数。
其中,T:true;P:Positive;F:false;N:negative。组合即可。
例如TP:真阳性(正确识别为相关的),TN:真阴性(相关项目中错误识别为不想关的)
nltk.metrics.precision(refsets[‘pos’], testsets[‘pos’])
nltk.metrics.recall(refsets[‘pos’], testsets[‘pos’])
nltk.metrics.f_measure(refsets[‘pos’], testsets[‘pos’])
另一个准确度分数可能会产生误导的实例是在“搜索”任务中,如信息检索,我们试图找出与特定任务有关的文档。由于不相关的文档的数量远远多于相关文档的数量,一个将每一个文档都标记为无关的模型的准确度分数将非常接近100%。
混淆矩阵
nltk.ConfusionMatrix(gold, test)
当处理有3 个或更多的标签的分类任务时,基于模型错误类型细分模型的错误是有信息量的。一个混淆矩阵是一个表,其中每个cells [i,j]表示正确的标签i被预测为标签j的次数。
因此,对角线项目(即cells |ii|)表示正确预测的标签,非对角线项目表示错误。
三种分类器的总结
之前我们发现。同样的特征集,
- 朴素贝叶斯分类器就可以轻松跑完
- 但是决策树分类器不行。除了过拟合
的因素外,还是因为树结构强迫特征按照特定的顺序检查,即便他是重复的,而在回溯的过程中,又有重复运算,导致时间和空间的双重浪费。朴素贝叶斯分类器允许所有恩正“并行”起作用,从计算每个标签的先验概率开始。并且建立朴素贝叶斯的时候采用了平滑技术(在给定的贝叶斯模型上)。 - 最后的最大熵分类器,使用搜索技术找出一组能最大限度的提高分类器性能的参数。由于他会用迭代优化技术选择参数,花费时间很长 。