什么是 NLTK
NLTK,全称Natural Language Toolkit,自然语言处理工具包,是NLP研究领域常用的一个Python库,由宾夕法尼亚大学的Steven Bird和Edward Loper在Python的基础上开发的一个模块,至今已有超过十万行的代码。这是一个开源项目,包含数据集、Python模块、教程等;
如何安装
详情可以参见我的另一篇博客NLP的开发环境搭建,通过这篇博客,你将学会Python环境的安装以及NLTK模块的下载;
常见模块及用途

NLTK能干啥?
- 搜索文本
- 单词搜索:
- 相似词搜索;
- 相似关键词识别;
- 词汇分布图;
- 生成文本;
- 计数词汇


#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018-9-28 22:21
# @Author : Manu
# @Site :
# @File : python_base.py
# @Software: PyCharmfrom __future__ import division
import nltk
import matplotlib
from nltk.book import *
from nltk.util import bigrams# 单词搜索
print('单词搜索')
text1.concordance('boy')
text2.concordance('friends')# 相似词搜索
print('相似词搜索')
text3.similar('time')#共同上下文搜索
print('共同上下文搜索')
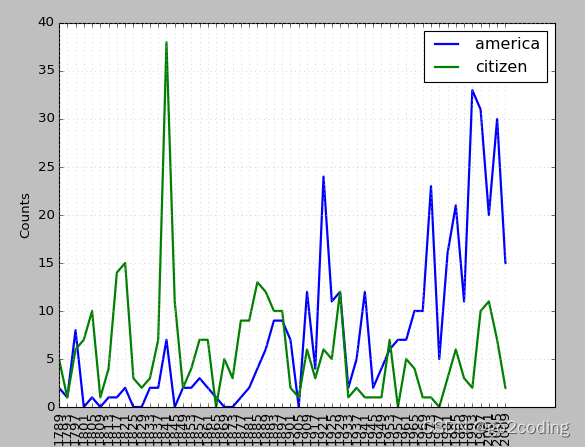
text2.common_contexts(['monstrous','very'])# 词汇分布表
print('词汇分布表')
text4.dispersion_plot(['citizens', 'American', 'freedom', 'duties'])# 词汇计数
print('词汇计数')
print(len(text5))
sorted(set(text5))
print(len(set(text5)))# 重复词密度
print('重复词密度')
print(len(text8) / len(set(text8)))# 关键词密度
print('关键词密度')
print(text9.count('girl'))
print(text9.count('girl') * 100 / len(text9))# 频率分布
fdist = FreqDist(text1)vocabulary = fdist.keys()
for i in vocabulary:print(i)# 高频前20
fdist.plot(20, cumulative = True)# 低频词
print('低频词:')
print(fdist.hapaxes())# 词语搭配
print('词语搭配')
words = list(bigrams(['louder', 'words', 'speak']))
print(words)
NLTK设计目标
- 简易性;
- 一致性;
- 可扩展性;
- 模块化;
NLTK中的语料库
- 古腾堡语料库:
gutenberg; - 网络聊天语料库:
webtext、nps_chat; - 布朗语料库:
brown; - 路透社语料库:
reuters; - 就职演说语料库:
inaugural; - 其他语料库;
文本语料库结构
- isolated: 独立型;
- categorized:分类型;
- overlapping:重叠型;
- temporal:暂时型;
基本语料库函数

条件频率分布

总结
以上就是自然语言处理NLP中NLTK模块的相关知识介绍了,希望通过本文能解决你对NLTK的相关疑惑,欢迎评论互相交流!!!