文章目录
- NLTK库简介
- NLTK库重要模块及功能
- 安装NLTK库
- NLTK中的语料库
- 英文文本语料库
- 标注文本语料库
- 其他语言的语料库
- 文本语料库常见结构
- NLTK 中定义的基本语料库函数
- 加载自己的语料库
NLTK库简介
Natural Language Toolkit(简称NLTK库),自然语言处理工具包,是一个当下流行的,用于自然语言处理的Python 库。
NLTK 包含大量的软件、数据和文档,所有这些都可以从http://nltk.org/ 免费下载。
NLTK 创建于2001 年,最初是宾州大学计算机与信息科学系计算语言学课程的一部分。从那以后,在数十名贡献者的帮助下不断发展壮大。如今,它已被几十所大学的课程所采纳,并作为许多研究项目的基础。
NLTK库重要模块及功能

安装NLTK库
pip install nltk
通过运行以下代码来安装NLTK扩展包
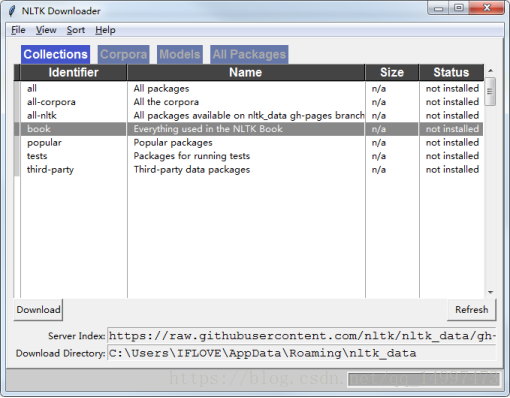
import nltknltk.download()
NLTK中的语料库
在自然语言处理的实际项目中,通常要使用大量的语言数据或者语料库。
一个文本语料库是一大段文本。
nltk.corpus包提供了许多语料库。
英文文本语料库
- gutenberg 一个有若干万部的小说语料库,多是古典作品
- webtext 网络和聊天文本
- nps_chat 有上万条聊天消息语料库,即时聊天消息为主
- brown 第一个百万词级的英语语料库,按文体进行分类
- reuters 路透社语料库,上万篇新闻方档,约有1百万字,分90个主题,并分为训练集和测试集两组
- inaugural 演讲语料库,几十个文本,都是总统演说
标注文本语料库
许多文本语料库都包含语言学标注,有词性标注、命名实体、句法结构、语义角色等

其他语言的语料库
udhr,是超过300种语言的世界人权宣言
更多语料库,可以用==nltk.download()==在下载管理器中查看corpus。
文本语料库常见结构
- 最简单的一种语料库是一些孤立的没有什么特别的组织的文本集合;
- 一些语料库按如文体(布朗语料库)等分类组织结构;
- 一些分类会重叠,如主题类别(路透社语料库);
- 另外一些语料库可以表示随时间变化语言用法的改变(就职演说语料库)。
NLTK 中定义的基本语料库函数
fileids() #语料库中的文件
fileids([categories]) #这些分类对应的语料库中的文件
categories() #语料库中的分类
categories([fileids]) #这些文件对应的语料库中的分类
raw() #语料库的原始内容
raw(fileids=[f1,f2,f3]) #指定文件的原始内容
raw(categories=[c1,c2]) #指定分类的原始内容
words() #整个语料库中的词汇
words(fileids=[f1,f2,f3]) #指定文件中的词汇
words(categories=[c1,c2]) #指定分类中的词汇
sents() #整个语料库中的句子
sents(fileids=[f1,f2,f3]) #指定文件中的句子
sents(categories=[c1,c2]) #指定分类中的句子
abspath(fileid) #指定文件在磁盘上的位置
encoding(fileid) #文件的编码(如果知道的话)
open(fileid) #打开指定语料库文件的文件流
root #本地安装的语料库根目录的路径
readme() #语料库的README 文件的内容
举个例子
import nltk
from nltk.corpus import reutersreuters.fileids()#查看文件
reuters.categories()#查看分类
reuters.fileids(['barley', 'corn'])#查看属于两个分类的文件
加载自己的语料库
如果你有自己收集的文本文件,可以在NLTK 中的PlaintextCorpusReader帮助下加载它们。
变量corpus_root [1]的值设置为文件储存目录。
第二个参数file_pattern[2]可以是一个如[‘a.txt’, ‘test/b.txt’]这样的fileids列表,或者一个正则表达式
如’[abc]/.*.txt’。
from nltk.corpus import BracketParseCorpusReader
corpus_root = r"C:\corpora\penntreebank\parsed\mrg\wsj"# [1]
file_pattern ='.*'ptb = BracketParseCorpusReader(corpus_root,file_pattern)#[2]
ptb.fileids()