文章目录
- 如何确定一个词的词性
- 1形态学线索
- 2句法线索
- 3语义线索
- NLTK标注器
- 标注语料库
- 查看标注
- 未简化标记集
- 词性搜索
- @字典
- 定义字典
- 反转字典
- 字典方法
- 自动标注
- 默认标注器(不好)
- 标注效果评估
- 正则表达式标注器
- 查询标注器
- 回退
- N-gram标注
- 一元标注器
- N-gram标注器
- 缺点
- 组合标注器
- 标注生词
- 一个基于上下文标注生词的方法:
- @准确性的极限
- Brill标注器
- 思想
- Brill标注的步骤
- 代码
如何确定一个词的词性
1形态学线索
一个词的内部结构可能为这个词分类提供有用的线索。举例来说:-ness是一个后缀,与形容词结合产生一个名词,如happy → happiness, ill → illness。如果我们遇到的一个以-ness结尾的词,很可能是一个名词。
英语动词也可以是形态复杂的。例如,一个动词的现在分词以-ing结尾,表示正在进行的还没有结束的行动(如falling, eating)。-ing后缀也出现在从动词派生的名词中,如the falling of the leaves(这被称为动名词)。
2句法线索
另一个信息来源是一个词可能出现的典型的上下文语境。
例如,假设我们已经确定了名词类。那么我们可以说,英语形容词的句法标准是它可以立即出现在一个名词前,或紧跟在词be或very后。
3语义线索
一个词的意思对其词汇范畴是一个有用的线索。例如,名词的众所周知的一个名词定义是根据语义的:“一个人、地方或事物的名称”。在现代语言学,词类的语义标准受到怀疑,主要是因为它们很难规范化。
然而,语义标准巩固了我们对许多词类的直觉,使我们能够在不熟悉的语言中很好的猜测词的分类。
例如,如果我们都知道荷兰语词verjaardag的意思与英语词birthday相同,那么我们可以猜测verjaardag在荷兰语中是一个名词。
然而,一些修补是必要的:虽然我们可能翻译zij is vandaag jarig为it’s her birthday today,词jarig在荷兰语中实际上是形容词,与英语并不完全相同。
NLTK标注器
nltk.pos_tag
import nltk
text = nltk.word_tokenize("and now for something completely different")
nltk.pos_tag(text)
#[('and', 'CC'), ('now', 'RB'), ('for', 'IN'), ('something', 'NN'), ('completely', 'RB'), ('different', 'JJ')]你可能想知道要引进这种额外的信息的理由是什么。很多这些类别源于对文本中单词分布的粗略分析。考虑下面的分析,涉及woman(名词),bought(动词),over(介词)和the(限定词)。text.similar()方法接收一个单词w,找出所有上下文w1w w2,然后找出所有出现在相同上下文中的词w’,即w1w’w2。可以观察到,搜索woman找到名词;搜索bought找到的大部分是动词;搜索over一般会找到介词;搜索the找到几个限定词。
一个标注器能够正确识别一个句子的上下文中的这些词的标记。
标注器还可以为我们对未知词的认识建模,例如我们可以根据词根scrobble猜测scrobbling可能是一个动词,并有可能发生在he was scrobbling这样的上下文中。
标注语料库
查看标注
只要语料库包含已标注的文本,NLTK的语料库接口都将有一个tagged_words() 方法
nltk.corpus.treebank.tagged_words(tagset='universal')
#[('Pierre', 'NOUN'), ('Vinken', 'NOUN'), (',', '.'), ...]
一个简化的标记集
ADJ 形容词 new, good, high, special, big, local
ADV 副词 really, already, still, early, now
CNJ 连词 and, or, but, if, while, although
DET 限定词 the, a, some, most, every, no
EX 存在量词 there, there's
FW 外来词 dolce, ersatz, esprit, quo, maitre
MOD 情态动词 will, can, would, may, must, should
N 名词 year, home, costs, time, education
NP 专有名词 Alison, Africa, April, Washington
NUM 数词 twenty-four, fourth, 1991, 14:24
PRO 代词 he, their, her, its, my, I, us
P 介词 on, of, at, with, by, into, under
TO 词 to to
UH 感叹词 ah, bang, ha, whee, hmpf, oops
V 动词 is, has, get, do, make, see, run
VD 过去式 said, took, told, made, asked
VG 现在分词 making, going, playing, working
VN 过去分词 given, taken, begun, sung
WH Wh 限定词 who, which, when, what, where, howNLTK中还有其他几种语言的已标注语料库,包括中文,印地语,葡萄牙语,西班牙语,荷兰语和加泰罗尼亚语。
未简化标记集
查看布朗语料库的词性标注,发现优许多NN的变种;有$表示所有格名词,S表示复数名词(因为复数名词通常以s结尾),以及P表示专有名词。此外,大多数的标记都有后缀修饰符:-NC表示引用,-HL表示标题中的词,-TL表示标题(布朗标记的特征)。
NN [('year', 137), ('time', 97), ('state', 88), ('week', 85), ('man', 72)]
NN$ [("year's", 13), ("world's", 8), ("state's", 7), ("nation's", 6), ("company's", 6)]
NN$-HL [("Golf's", 1), ("Navy's", 1)]
NN$-TL [("President's", 11), ("Army's", 3), ("Gallery's", 3), ("University's", 3), ("League's", 3)]
NN-HL [('sp.', 2), ('problem', 2), ('Question', 2), ('business', 2), ('Salary', 2)]
NN-NC [('eva', 1), ('aya', 1), ('ova', 1)]
NN-TL [('President', 88), ('House', 68), ('State', 59), ('University', 42), ('City', 41)]
NN-TL-HL [('Fort', 2), ('Dr.', 1), ('Oak', 1), ('Street', 1), ('Basin', 1)]
NNS [('years', 101), ('members', 69), ('people', 52), ('sales', 51), ('men', 46)]
NNS$ [("children's", 7), ("women's", 5), ("janitors'", 3), ("men's", 3), ("taxpayers'", 2)]
NNS$-HL [("Dealers'", 1), ("Idols'", 1)]
NNS$-TL [("Women's", 4), ("States'", 3), ("Giants'", 2), ("Bros.'", 1), ("Writers'", 1)]
NNS-HL [('comments', 1), ('Offenses', 1), ('Sacrifices', 1), ('funds', 1), ('Results', 1)]
NNS-TL [('States', 38), ('Nations', 11), ('Masters', 10), ('Rules', 9), ('Communists', 9)]
NNS-TL-HL [('Nations', 1)]
词性搜索
使用一个图形化的词性索引工具nltk.app.concordance()
用它来寻找任一单词和词性标记的组合如N N N N, hit/VD, hit/VN或者the ADJ man。
@字典
定义字典
我们可以使用键-值对格式创建字典,有两种方式做这个,我们通常会使用第一个
pos = {'colorless': 'ADJ', 'ideas': 'N', 'sleep': 'V', 'furiously': 'ADV'}
pos = dict(colorless='ADJ', ideas='N', sleep='V', furiously='ADV')
反转字典
通过值查找键
pos.update({'cats': 'N', 'scratch': 'V', 'peacefully': 'ADV', 'old': 'ADJ'})
pos2 = defaultdict(list)
for key, value in pos.items():pos2[value].append(key)pos2['ADV']
#['peacefully', 'furiously']
字典方法
常用的方法与字典相关习惯用法的总结。
示例 描述
d = {} 创建一个空的字典,并将分配给d
d[key] = value 分配一个值给一个给定的字典键
d.keys() 字典的键的列表
list(d) 字典的键的列表
sorted(d) 字典的键,排好序
key in d 测试一个特定的键是否在字典中
for key in d 遍历字典的键
d.values() 字典中的值的列表
dict([(k1,v1), (k2,v2), ...]) 从一个键-值对列表创建一个字典
d1.update(d2) 添加d2中所有项目到d1
defaultdict(int) 一个默认值为0的字典
自动标注
默认标注器(不好)
最简单的标注器是为每个词符分配同样的标记。
为了得到最好的效果,我们用最有可能的标记标注每个词。
nltk.DefaultTagger()
tags = [tag for (word, tag) in brown.tagged_words(categories='news')]
nltk.FreqDist(tags).max()
#'NN'
raw = 'I do not like green eggs and ham, I do not like them Sam I am!'tokens = word_tokenize(raw)
default_tagger = nltk.DefaultTagger('NN')
default_tagger.tag(tokens)
标注效果评估
.evaluate()
default_tagger.evaluate(brown_tagged_sents)
0.13089484257215028
不出所料,这种方法的表现相当不好。在一个典型的语料库中,它只标注正确了八分之一的标识符
由于我们通常很难获得专业和公正的人的判断,所以使用黄金标准测试数据来代替。这是一个已经手动标注并作为自动系统评估标准而被接受的语料库。当标注器对给定词猜测的标记与黄金标准标记相同,标注器被视为是正确的。
正则表达式标注器
nltk.RegexpTagger()
patterns = [(r'.*ing$', 'VBG'), # gerunds(r'.*ed$', 'VBD'), # simple past(r'.*es$', 'VBZ'), # 3rd singular present(r'.*ould$', 'MD'), # modals
(r'.*\'s$', 'NN$'), # possessive nouns(r'.*s$', 'NNS'), # plural nouns(r'^-?[0-9]+(.[0-9]+)?$', 'CD'), # cardinal numbers(r'.*', 'NN') # nouns (default)
]
regexp_tagger = nltk.RegexpTagger(patterns)
regexp_tagger.tag(brown_sents[3])
#[('``', 'NN'), ('Only', 'NN'), ('a', 'NN'), ('relative', 'NN'), ('handful', 'NN'),
('of', 'NN'), ('such', 'NN'), ('reports', 'NNS'), ('was', 'NNS'), ('received', 'VBD'),
("''", 'NN'), (',', 'NN'), ('the', 'NN'), ('jury', 'NN'), ('said', 'NN'), (',', 'NN'),
('``', 'NN'), ('considering', 'VBG'), ('the', 'NN'), ('widespread', 'NN'), ...]regexp_tagger.evaluate(brown_tagged_sents)
#0.20326391789486245
查询标注器
nltk.UnigramTagger()
找出100个最频繁的词,存储它们最有可能的标记。
然后我们可以使用这个信息作为“查找标注器”(NLTK UnigramTagger)的模型
>>> fd = nltk.FreqDist(brown.words(categories='news'))
>>> cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories='news'))
>>> most_freq_words = fd.most_common(100)
>>> likely_tags = dict((word, cfd[word].max()) for (word, _) in most_freq_words)
>>> baseline_tagger = nltk.UnigramTagger(model=likely_tags)
>>> baseline_tagger.evaluate(brown_tagged_sents)
0.45578495136941344
如果词不在100个最频繁的词之中,会被分配一个None标签
在这些情况下,我们想分配默认标记NN。
回退
换句话说,我们要先使用查找表,如果它不能指定一个标记就使用默认标注器,这个过程叫做回退
N-gram标注
一元标注器
一元标注器基于一个简单的统计算法:对每个标识符分配这个独特的标识符最有可能的标记。
一元标注器的行为和查找标注器很相似。
nltk.UnigramTagger()
>>> from nltk.corpus import brown
>>> brown_tagged_sents = brown.tagged_sents(categories='news')
>>> brown_sents = brown.sents(categories='news')
>>> unigram_tagger = nltk.UnigramTagger(brown_tagged_sents)
>>> unigram_tagger.tag(brown_sents[2007])
[('Various', 'JJ'), ('of', 'IN'), ('the', 'AT'), ('apartments', 'NNS'),
('are', 'BER'), ('of', 'IN'), ('the', 'AT'), ('terrace', 'NN'), ('type', 'NN'),
(',', ','), ('being', 'BEG'), ('on', 'IN'), ('the', 'AT'), ('ground', 'NN'),
('floor', 'NN'), ('so', 'QL'), ('that', 'CS'), ('entrance', 'NN'), ('is', 'BEZ'),
('direct', 'JJ'), ('.', '.')]
>>> unigram_tagger.evaluate(brown_tagged_sents)
0.9349006503968017
我们训练一个UnigramTagger,通过在我们初始化标注器时指定已标注的句子数据作为参数。训练过程中涉及检查每个词的标记,将所有词的最可能的标记存储在一个字典里面,这个字典存储在标注器内部。
N-gram标注器
N元标注器,就是检索index= n 的 word,并且检索n-N<=index<=n-1 的 tag。即通过前面词的tag标签,进一步确定当前词汇的tag。类似于nltk.UnigramTagger(),
自带的二元标注器为:nltk.BigramTagger() 用法一致。
缺点
- 请注意,二元标注器能够标注训练中它看到过的句子中的所有词,但对一个没见过的句子表现很差。只要遇到一个新词,就无法给它分配标记。
当n越大,上下文的特异性就会增加,我们要标注的数据中包含训练数据中不存在的上下文的几率也增大。这被称为数据稀疏问题 ,在NLP中是相当普遍的。因此,我们的研究结果的精度和覆盖范围之间需要有一个权衡(这与信息检索中的精度/召回权衡有关)。
-N-gram标注器不应考虑跨越句子边界的上下文。因此,NLTK的标注器被设计用于句子列表,其中一个句子是一个词列表。在一个句子的开始,tn-1和前面的标记被设置为None。
组合标注器
例如,我们可以按如下方式组合二元标注器、一元注器和一个默认标注器,如下:
1尝试使用二元标注器标注标识符。
2如果二元标注器无法找到一个标记,尝试一元标注器。
3如果一元标注器也无法找到一个标记,使用默认标注器。
大多数NLTK标注器允许指定一个回退标注器。回退标注器自身可能也有一个回退标注器
backoff
>>> t0 = nltk.DefaultTagger('NN')
>>> t1 = nltk.UnigramTagger(train_sents, backoff=t0)
>>> t2 = nltk.BigramTagger(train_sents, backoff=t1)
>>> t2.evaluate(test_sents)
0.844513...
- 请注意,我们在标注器初始化时指定回退标注器,从而使训练能利用回退标注器。于是,在一个特定的上下文中,如果二元标注器将分配与它的一元回退标注器一样的标记,那么二元标注器丢弃训练的实例。这样保持尽可能小的二元标注器模型。我们可以进一步指定一个标注器需要看到一个上下文的多个实例才能保留它,例如nltk.BigramTagger(sents, cutoff=2, backoff=t1)将会丢弃那些只看到一次或两次的上下文。
标注生词
标注生词的方法是回退到一个正则表达式标注器或一个默认标注器,则无法利用上下文。
一个基于上下文标注生词的方法:
是限制一个标注器的词汇表为最频繁的n 个词,替代每个其他的词为一个特殊的词UNK。训练时,一个一元标注器可能会学到UNK通常是一个名词。然而,n-gram标注器会检测它的一些其他标记中的上下文。例如,如果前面的词是to(标注为TO),那么UNK可能会被标注为一个动词。
@准确性的极限
另一个方法查看标注错误是混淆矩阵。
它用图表表示期望的标记(黄金标准)与实际由标注器产生的标记
>>> test_tags = [tag for sent in brown.sents(categories='editorial')
... for (word, tag) in t2.tag(sent)]
>>> gold_tags = [tag for (word, tag) in brown.tagged_words(categories='editorial')]
>>> print(nltk.ConfusionMatrix(gold_tags, test_tags))
Brill标注器
nltk.tag.brill.demo()
import nltk
from nltk.tag import brill
brill.nltkdemo18plus()
brill.nltkdemo18()
思想
Brill标注的的过程通常是与绘画类比来解释的。假设我们要画一棵树,包括大树枝、树枝、小枝、叶子和一个统一的天蓝色背景的所有细节。不是先画树然后尝试在空白处画蓝色,而是简单的将整个画布画成蓝色,然后通过在蓝色背景上上色“修正”树的部分。以同样的方式,我们可能会画一个统一的褐色的树干再回过头来用更精细的刷子画进一步的细节。
Brill标注使用了同样的想法:以大笔画开始,然后修复细节,一点点的细致的改变。
Brill标注的步骤
让我们看看下面的例子:
(1) The President said he will ask Congress to increase grants to states for vocational rehabilitation
我们将研究两个规则的运作:
(a)当前面的词是TO时,替换NN为VB;
(b)当下一个标记是NNS时,替换TO为IN。
首先使用一元标注器标注,然后运用规则修正错误。
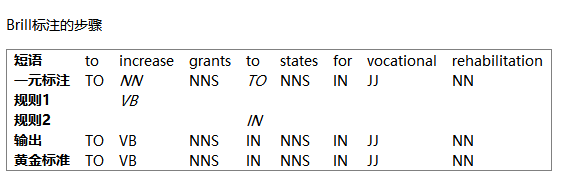
在此表中,我们看到两个规则。所有这些规则由以下形式的模板产生:“在上下文C中替换T1为T2”。典型的上下文是之前或之后的词的内容或标记,或者当前词的两到三个词范围内出现的一个特定标记。
在其训练阶段,标注器猜测T1、T2和C的值,创造出数以千计的候选规则。
每一条规则都根据其净收益打分:它修正的不正确标记的数目减去它错误修改的正确标记的数目。
- Brill标注器的另一个有趣的特性:规则是语言学可解释的。
代码
>>> nltk.tag.brill.demo()
Training Brill tagger on 80 sentences...
Finding initial useful rules...Found 6555 useful rules.B |S F r O | Score = Fixed - Brokenc i o t | R Fixed = num tags changed incorrect -> correcto x k h | u Broken = num tags changed correct -> incorrectr e e e | l Other = num tags changed incorrect -> incorrecte d n r | e
------------------+-------------------------------------------------------12 13 1 4 | NN -> VB if the tag of the preceding word is 'TO'8 9 1 23 | NN -> VBD if the tag of the following word is 'DT'8 8 0 9 | NN -> VBD if the tag of the preceding word is 'NNS'6 9 3 16 | NN -> NNP if the tag of words i-2...i-1 is '-NONE-'5 8 3 6 | NN -> NNP if the tag of the following word is 'NNP'5 6 1 0 | NN -> NNP if the text of words i-2...i-1 is 'like'5 5 0 3 | NN -> VBN if the text of the following word is '*-1'...
>>> print(open("errors.out").read())left context | word/test->gold | right context
--------------------------+------------------------+--------------------------| Then/NN->RB | ,/, in/IN the/DT guests/N
, in/IN the/DT guests/NNS | '/VBD->POS | honor/NN ,/, the/DT speed
'/POS honor/NN ,/, the/DT | speedway/JJ->NN | hauled/VBD out/RP four/CD
NN ,/, the/DT speedway/NN | hauled/NN->VBD | out/RP four/CD drivers/NN
DT speedway/NN hauled/VBD | out/NNP->RP | four/CD drivers/NNS ,/, c
dway/NN hauled/VBD out/RP | four/NNP->CD | drivers/NNS ,/, crews/NNS
hauled/VBD out/RP four/CD | drivers/NNP->NNS | ,/, crews/NNS and/CC even
P four/CD drivers/NNS ,/, | crews/NN->NNS | and/CC even/RB the/DT off
NNS and/CC even/RB the/DT | official/NNP->JJ | Indianapolis/NNP 500/CD a| After/VBD->IN | the/DT race/NN ,/, Fortun
ter/IN the/DT race/NN ,/, | Fortune/IN->NNP | 500/CD executives/NNS dro
s/NNS drooled/VBD like/IN | schoolboys/NNP->NNS | over/IN the/DT cars/NNS a
olboys/NNS over/IN the/DT | cars/NN->NNS | and/CC drivers/NNS ./.
Brill标注器演示:标注器有一个X -> Y if the preceding word is Z形式的模板集合;这些模板中的变量是创建“规则”的特定词和标记的实例;规则的得分是它纠正的错误例子的数目减去正确的情况下它误报的数目;除了训练标注器,演示还显示了剩余的错误。