前言
简单来讲,卷积是一种函数和函数产生一个新函数的数学运算,该数学运算的自变量是两个函数f, g(连续或离散都可以,,定义域之外的部分记函数值填充为0),输出为一个函数h,满足
,或者说,就是对每个自变量t, 的h(t)值,都是g与对应f的函数值的加权和。
1. 一维离散卷积数学表达


2. 二维离散卷积定义

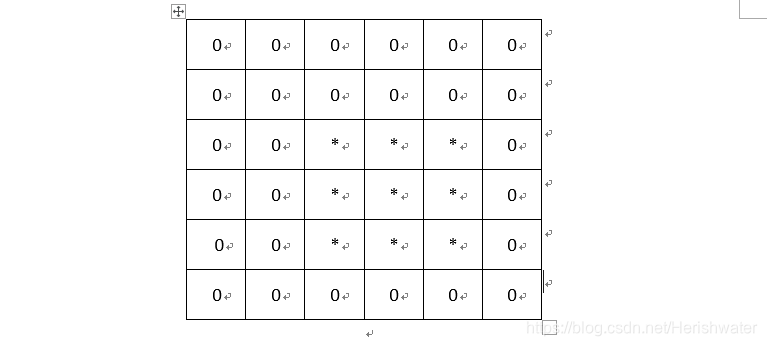
3. 图像卷积
卷积核套合在图像上,对应位置相乘求和赋值给中心像素,滑动卷积核(从左到右,从上到下),依次得到新的特征图上的值。

上图展示的是 stride=1 的情形,既每次移动一个像素的位置。并且,上图未进行padding,所以卷积之后的特征图会在四周各缩减(kernel_size-1)/2个像素。同时也可以在边缘填充0,使得卷积之后的特征图大小不变。
4. 深度学习中的卷积

5. 卷积计算的加速
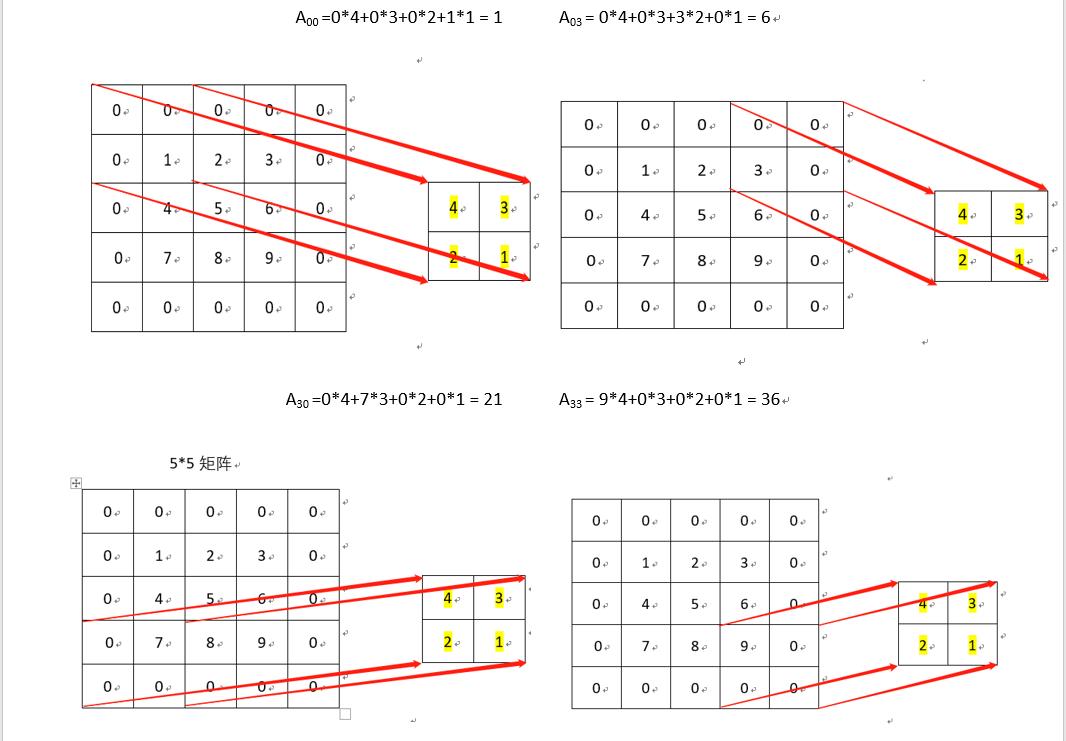
5.1 原理示意图

卷积计算是将输入图像矩阵和卷积核矩阵变换为两个大的矩阵(im2col),然后进行矩阵相乘(GEMM)(利用GPU进行矩阵相乘的高效性)。
5.2 im2col in tensorflow
具体到tensorflow中,im2col操作可以用tf.extract_image_patches代替:
tf.image.extract_image_patches(images,ksizes=None,strides=None,rates=None,padding=None,name=None,sizes=None
)
# images:必须是shape为[batch, in_rows, in_cols, depth]的tensor;
# ksize:长度大于等于4的list,滑动窗的大小
# strides:每块patch区域之间中心点之间的距离,必须是: [1, stride_rows, stride_cols, 1].#具体点说就是用来计算每次选取patch的初始点位置
# rates: 在每次提取的patch中,对应dim像素点位置之间的差距,必须是[1, rate_rows, rate_cols, 1];「或者理解为 提取出来的每个框里面的像素不是都选择的 根据rate的不同 隔几个选一个 默认是1也就是的都选择 若为2 那么就是隔一个来选择」
# padding:有两个取值,“VALID”或者“SAME”,“VALID”表示所取的patch区域必须完全包含在原始图像中."SAME"表示可以取超出原始图像的部分,这一部分进行0填充。
# for example
import tensorflow as tf
import numpy as npimage = np.arange(5 * 5).reshape(5, 5)
# [[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19],
# [20, 21, 22, 23, 24]]image = image.reshape(1, 5, 5, 1)
# image:(batch_size, img_row, img_col, input_filters)
images = tf.convert_to_tensor(image.astype(np.float32))image_patches = tf.extract_image_patches(images,[1, 3, 3, 1],[1, 1, 1, 1],[1, 1, 1, 1],padding='SAME')
# image_patches: (batch_size, img_row, img_col, kernel_row * kernel_col * input_filters)with tf.Session() as sess:print(sess.run(image_patches))
# [[[[ 0. 0. 0. 0. 0. 1. 0. 5. 6.]
# [ 0. 0. 0. 0. 1. 2. 5. 6. 7.]
# [ 0. 0. 0. 1. 2. 3. 6. 7. 8.]
# [ 0. 0. 0. 2. 3. 4. 7. 8. 9.]
# [ 0. 0. 0. 3. 4. 0. 8. 9. 0.]]
#
# [[ 0. 0. 1. 0. 5. 6. 0. 10. 11.]
# [ 0. 1. 2. 5. 6. 7. 10. 11. 12.]
# [ 1. 2. 3. 6. 7. 8. 11. 12. 13.]
# [ 2. 3. 4. 7. 8. 9. 12. 13. 14.]
# [ 3. 4. 0. 8. 9. 0. 13. 14. 0.]]
#
# [[ 0. 5. 6. 0. 10. 11. 0. 15. 16.]
# [ 5. 6. 7. 10. 11. 12. 15. 16. 17.]
# [ 6. 7. 8. 11. 12. 13. 16. 17. 18.]
# [ 7. 8. 9. 12. 13. 14. 17. 18. 19.]
# [ 8. 9. 0. 13. 14. 0. 18. 19. 0.]]
#
# [[ 0. 10. 11. 0. 15. 16. 0. 20. 21.]
# [10. 11. 12. 15. 16. 17. 20. 21. 22.]
# [11. 12. 13. 16. 17. 18. 21. 22. 23.]
# [12. 13. 14. 17. 18. 19. 22. 23. 24.]
# [13. 14. 0. 18. 19. 0. 23. 24. 0.]]
#
# [[ 0. 15. 16. 0. 20. 21. 0. 0. 0.]
# [15. 16. 17. 20. 21. 22. 0. 0. 0.]
# [16. 17. 18. 21. 22. 23. 0. 0. 0.]
# [17. 18. 19. 22. 23. 24. 0. 0. 0.]
# [18. 19. 0. 23. 24. 0. 0. 0. 0.]]]]
5.3 对比自己写的卷积和tf原有的卷积
import tensorflow as tf
import numpy as np# 生成图像
image = np.arange(5 * 5 * 3).reshape(1, 5, 5, 3)
# image:(batch_size, img_row, img_col, input_filters)
images = tf.convert_to_tensor(image.astype(np.float32))image_patches = tf.extract_image_patches(images,[1, 3, 3, 1],[1, 1, 1, 1], [1, 1, 1, 1],padding='SAME')image_patches = tf.reshape(image_patches, [-1, 27])# 生成卷积核
kernel = np.arange(3 * 3 * 3 * 64).reshape(3, 3, 3, 64)
# kernel:(kernel_row, kernel_col, input_filters,output_filters)
kernel = tf.convert_to_tensor(kernel.astype(np.float32))
kernel_filter = tf.reshape(kernel, [27, 64])# 自定义的卷积
actual = tf.matmul(image_patches, kernel_filter)
actual = tf.reshape(actual, [-1, 5, 5, 64])
# filtered_image:(batch_size, img_row, img_col, output_filters)# tf定义的卷积
expected = tf.nn.conv2d(images, kernel, strides=[1, 1, 1, 1], padding='SAME')with tf.Session() as sess:print(sess.run(actual))print(sess.run(expected))print(sess.run(tf.reduce_sum(expected - actual)))# 0.0
6. local_connected conv
6.1 原理示意图
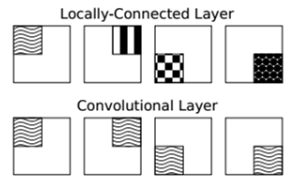
- 正常卷积是参数共享的,也就是说,对于同一张图片的不同块,应用相同的卷积核;
- 而局部连接卷积对于同一张图像的不同块应用不同的卷积核,其是非参数共享的。
6.2 自己写local_conv2d
import tensorflow as tf
import keras.backend as Kdef local_conv2d(inputs, kernel, kernel_size, strides, output_shape, data_format=None):# input: (batch_size, input_row, input_col, input_filter)# kernel: (output_row * output_col, kernel_row * kernel_col * input_filter, output_filters)# kernel_size: (kernel_row, kernel_col)# strides: (stride_row, stride_col)# output_shape: (output_row, output_col)# data_format=None: 'channels_first' or 'channels_last'data_format = normalize_data_format(data_format)stride_row, stride_col = stridesoutput_row, output_col = output_shapekernel_shape = int_shape(kernel)_, dim, filters = kernel_shapekernel_row, kernel_col = kernel_size[0], kernel_size[1]# result: (batch_size, output_row * output_col, kernel_row * kernel_col * input_filter)image_patches = tf.extract_image_patches(inputs,[1, kernel_row, kernel_col, 1],[1, stride_row, stride_col, 1],[1, 1, 1, 1],padding='VALID')image_patches = tf.reshape(image_patches, [-1, output_row * output_col, dim])image_patches = tf.transpose(image_patches, [1, 0, 2])output = K.batch_dot(image_patches, kernel)output = reshape(output,(output_row, output_col, -1, filters))if data_format == 'channels_first':output = tf.transpose(output, (2, 3, 0, 1))else:output = tf.transpose(output, (2, 0, 1, 3))return output