Viterbi算法
- 目标
- 过程
- 词典分词
- 统计分词
- 词性标注
- 附录
- 附录二
- 附录三
- 源码地址
目标
- 实现基于词典的分词方法和统计分词方法
- 对分词结果进行词性标注
- 对分词及词性标注结果进行评价,包括4个指标:正确率、召回率、F1值和效率
过程
词典分词
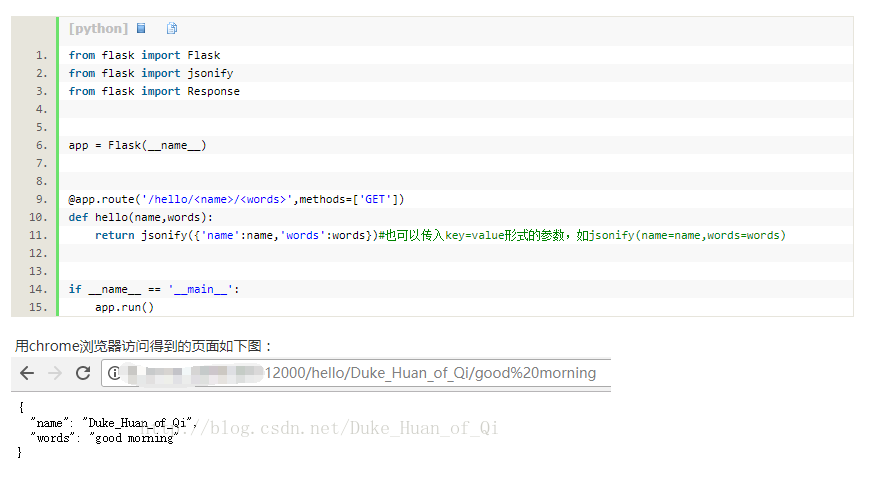
基于词典的分词方法中,我们使用了四种分词方法,即完全切分式,正向最长匹配,逆向最长匹配,双向最长匹配。此处代码见附录1。
这里的词典我选择使用了北京大学统计好的词典作为词典参考来进行实验。



我们随意输入几个句子并输出结果,根据结果来看,各个方法分词的效果还算不错。接下来我们使用人民日报的分好的语料库进行一个全篇的预测。

首先我们使用前向切分的方法,可以看到P,R,F1三个值,以及用时26.92s。

接下来使用后向切分的分法,正确率微微提升,同时用时27.51s。

最后使用双向切分的方法,正确率几乎不变,用时52s,几乎翻倍的时间。
P R F1 Time
前向 0.8413 0.8864 0.8864 26.91
后向 0.8482 0.8934 0.8934 27.51
双向 0.8489 0.8939 0.8708 52.73
可见,基于词典的分词方式,不论哪种方法,正确率基本稳定在这个范围上。效果还算可以。
统计分词
基于语料的统计分词,使用二元语法模型来构建词库,然后将句子生成词网,在使用viterbi算法来计算最优解,在这当中使用+1法来处理前后之间概率。代码放在附录2
首先我们处理原始文件,将人民日报语料库的带空格的文件处理成csv的表格形式方便我们进行分词的整理。



这里是二元语法模型的核心代码:

这里是生成句子词网的核心代码:

这里是+1平滑处理的核心代码:

这里是viterbi算法的核心代码:

测试集和训练集均为人民日报语料库,接下来是最终训练出来的效果。
展示了P,R,F1的值
可以看到还是达到了一个近乎99%的正确率,同时训练+预测共耗时307。
P = 0.9905
R = 0.9843
F1 = 0.9873

词性标注
对分词的结果进行词性标注。使用了统计的方法。此处代码同附录2.
我们先对人民日报带词性标注的txt文件进行一个转换,转换成便于我操作的csv文件。



下面是我们词性标注的训练核心代码,统计所有词性和他们的个数,获得相应的词性转移矩阵,在统计每个词语的词性概率。

这里是推测词性的核心代码:

下面是对分词结果的正确性评估,这里我使用了书中使用的方法,仅计算一个Accuracy作为正确率评估标准,同时我只对之前分词正确的结果结果进行词性评估,这样可以避免其它的错误。

通过检测结果来看,词性标注的正确率大概在95%左右,同时共计耗时315s。还算一个相对不错的效果。

附录
import csv
import timestart_time = time.time()# 读入字典
def load_dictionary():word_list = set()csvFile = open("test.csv", "r")reader = csv.reader(csvFile)for item in reader:word_list.add(item[0])return word_list# 完全切分式中文分词
# 如果在词典中则认为是一个词
def fully_segment(text, dic):word_list = []for i in range(len(text)):for j in range(i + 1, len(text) + 1):word = text[i:j]if word in dic:word_list.append(word)return word_list# 正向最长匹配
# 从当前扫描位置的单字所有可能的结尾,我们找最长的
def forward_segment(text, dic):word_list = []i = 0while i < len(text):longest_word = text[i]for j in range(i + 1, len(text) + 1):word = text[i:j]if word in dic:if len(word) > len(longest_word):longest_word = wordword_list.append(longest_word)i += len(longest_word)return word_list# 逆向最长匹配
def back_segment(text, dic):word_list = []i = len(text) - 1while i >= 0:longest_word = text[i]for j in range(0, i):word = text[j:i + 1]if word in dic:if len(word) > len(longest_word):longest_word = wordword_list.append(longest_word)i -= len(longest_word)word_list.reverse()return word_list# 统计单字成词的个数
def count_single_char(word_list: list):return sum(1 for word in word_list if len(word) == 1)# 双向最长匹配,实际上是做了个融合
def bidirectional_segment(text, dic):f = forward_segment(text, dic)b = back_segment(text, dic)# 词数更少更优先if len(f) < len(b):return felif len(f) > len(b):return belse:# 单字更少更优先if count_single_char(f) < count_single_char(b):return felse: # 都相等时我们更倾向于逆向匹配的return bdic = load_dictionary()
print(len(dic))
print("完全切分:", fully_segment("就读于北京大学", dic))
print("前向切分:", forward_segment("就读于北京大学", dic))
print("前向切分:", forward_segment("研究生物起源", dic))
print("后向切分:", back_segment("研究生物起源", dic))
print("双向切分:", bidirectional_segment("研究生物起源", dic))test_file = open("renmin.csv", "r")
reader = csv.reader(test_file)
test_sents = []
ans_sents = []
for item in reader:test_sent = ""ans_sent = []for word in item:test_sent += word.strip()ans_sent.append(word)test_sents.append(test_sent)ans_sents.append(ans_sent)# 将分词出来的结果转换为集合中元素
def zhuan_huan(text: list):ans = []i = 1for word in text:ans.append([i, i + len(word) - 1])i += len(word)return anstest_sents_num = len(test_sents)
print(test_sents_num)
P = 0
R = 0
for i in range(test_sents_num):xun_lian = bidirectional_segment(test_sents[i], dic)xun_lian_list = zhuan_huan(xun_lian)ans_list = zhuan_huan(ans_sents[i])xun_lian_set = set()for tmp in xun_lian_list:xun_lian_set.add(tuple(tmp))ans_list_set = set()for tmp in ans_list:ans_list_set.add(tuple(tmp))TP = ans_list_set & xun_lian_setp = len(TP) / len(xun_lian_list)r = len(TP) / len(ans_list)P += pR += rif i % 100 == 0:print(i / test_sents_num)# 求一个平均值
P = P / test_sents_num
R = R / test_sents_num
F_1 = 2 * P * R / (P + R)
print("P,R,F1", P, R, F_1)
end_time = time.time()
print(end_time - start_time)
附录二
import csv
import timestart_time = time.time()
fenci_file = open("renmin.csv", "r")
fenci_reader = csv.reader(fenci_file)
fenci_sents = []
for item in fenci_reader:sent = []for i in item:sent.append(i.strip())fenci_sents.append(sent)sum_zero = 0
for sent in fenci_sents:if len(sent) == 0:sum_zero += 1print(sent)
print(sum_zero)# 一元语法模型
def sgram(sents: list):dic = {}dic['#始始#'] = 0dic['#末末#'] = 0for sent in sents:for item in sent:if item in dic:dic[item] = dic[item] + 1else:dic[item] = 1dic['#始始#'] += 1dic['#末末#'] += 1return dicsi_gram = sgram(fenci_sents)# print(si_gram)# 二元语法模型
def bgram(sents: list):dic = {}dic["#始始#"] = dict()for sent in sents:for i in range(0, len(sent) - 1):if sent[i] not in dic:dic[sent[i]] = dict()dic[sent[i]][sent[i + 1]] = 1else:if sent[i + 1] in dic[sent[i]]:dic[sent[i]][sent[i + 1]] += 1else:dic[sent[i]][sent[i + 1]] = 1if sent[0] not in dic["#始始#"]:dic["#始始#"][sent[0]] = 1else:dic["#始始#"][sent[0]] += 1if sent[len(sent) - 1] not in dic:dic[sent[len(sent) - 1]] = dict()dic[sent[len(sent) - 1]]["#末末#"] = 1elif "#末末#" not in dic[sent[len(sent) - 1]]:dic[sent[len(sent) - 1]]["#末末#"] = 1else:dic[sent[len(sent) - 1]]["#末末#"] += 1return dicbi_gram = bgram(fenci_sents)# print(bi_gram)# 查看一元词频
def select_si_gram(gram: dict, word):return gram[word]def selecr_bi_gram(gram: dict, word_one, word_two):return gram[word_one][word_two]cixing_file = open("renmincixing.csv", "r")
cixing_reader = csv.reader(cixing_file)
cixing_sents = []
for item in cixing_reader:sent = []for i in item:sent.append(i.strip())cixing_sents.append(sent)# print(sents)part = dict()
# 统计所有词性个数
for sent in cixing_sents:for word in sent:word_part = word.split('/')[-1].split(']')[0].split('!')[0]if word_part in part:part[word_part] += 1else:part[word_part] = 1part_len = len(part)
print(part, "一共多少类:", part_len)
print("总频次", sum(part.values()))# 或得转移矩阵
trans = dict()
for sent in cixing_sents:for i in range(len(sent) - 1):one = sent[i].split('/')[-1].split(']')[0].split('!')[0]two = sent[i + 1].split('/')[-1].split(']')[0].split('!')[0]if one in trans:if two in trans[one]:trans[one][two] += 1else:trans[one][two] = 1else:trans[one] = dict()trans[one][two] = 1
print(trans)# 每个词的词性概率
percent = dict()
for sent in cixing_sents:for word in sent:word_word = word.split('/')[0].split('{')[0].strip('[')word_part = word.split('/')[-1].split(']')[0].split('!')[0]if word_word in percent:if word_part in percent[word_word]:percent[word_word][word_part] += 1else:percent[word_word][word_part] = 1else:percent[word_word] = dict()percent[word_word][word_part] = 1# print(percent)def fen_ci(text):# 生成一元语法词网def generate_wordnet(gram, text):net = [[] for _ in range(len(text) + 2)]for i in range(len(text)):for j in range(i + 1, len(text) + 1):word = text[i:j]if word in gram:net[i + 1].append(word)i = 1while i < len(net) - 1:if len(net[i]) == 0: # 空白行j = i + 1for j in range(i + 1, len(net) - 1):# 寻找第一个非空行jif len(net[j]):break# 填补i,j之间的空白行net[i].append(text[i - 1:j - 1])i = jelse:i += len(net[i][-1])return net# 测试一个句子si_net = generate_wordnet(si_gram, text)# print(si_net)def calculate_gram_sum(gram: dict):num = 0for g in gram.keys():num += sum(gram[g].values())return num# 计算word_one后出现word_two的概率,带上+1平滑处理def calculate_weight(gram: dict, word_one, word_two, gram_sum):if word_one in gram:word_one_all = gram[word_one].values()if word_two in gram[word_one]:return (gram[word_one][word_two] + 1) / (sum(word_one_all) + gram_sum)else:return 1 / (sum(word_one_all) + gram_sum)else:return 1 / gram_sumbi_gram_sum = calculate_gram_sum(bi_gram)# print(bi_gram_sum)def viterbi(wordnet):dis = [dict() for _ in range(len(wordnet))]node = [dict() for _ in range(len(wordnet))]word_line = [dict() for _ in range(len(wordnet))]wordnet[len(wordnet) - 1].append("#末末#")# 更新第一行for word in wordnet[1]:dis[1][word] = calculate_weight(bi_gram, "#始始#", word, bi_gram_sum)node[1][word] = 0word_line[1][word] = "#始始#"# 遍历每一行wordnetfor i in range(1, len(wordnet) - 1):# 遍历每一行中单词for word in wordnet[i]:# 更新加上这个单词的距离之后那个位置的所有单词的距离for to in wordnet[i + len(word)]:if word in dis[i]:if to in dis[i + len(word)]:# 要的是最大的概率if dis[i + len(word)][to] < dis[i][word] * calculate_weight(bi_gram, word, to, bi_gram_sum):dis[i + len(word)][to] = dis[i][word] * calculate_weight(bi_gram, word, to, bi_gram_sum)node[i + len(word)][to] = iword_line[i + len(word)][to] = wordelse:dis[i + len(word)][to] = dis[i][word] * calculate_weight(bi_gram, word, to, bi_gram_sum)node[i + len(word)][to] = iword_line[i + len(word)][to] = word# 回溯path = []f = node[len(node) - 1]["#末末#"]fword = word_line[len(word_line) - 1]["#末末#"]path.append(fword)while f:tmpword = fwordfword = word_line[f][tmpword]f = node[f][tmpword]path.append(fword)path = path[:-1]path.reverse()return dis, node, word_line, path(dis, _, _, path) = viterbi(si_net)# print(dis)# print(path)return pathdef ci_xing(text):text_percent = []# 这里我们假设是所有单词都已经人民日报语料库了for word in text:word_percent = percent[word]text_percent.append(word_percent)# print(text_percent)# 下面我们来使用Viterbi算法计算出最佳的组成dis = [dict() for _ in range(len(text))]node = [dict() for _ in range(len(text))]for first in text_percent[0].keys():dis[0][first] = 1for i in range(len(text) - 1):word_one = text[i]word_two = text[i + 1]word_one_percent_dict = text_percent[i]word_two_percent_dict = text_percent[i + 1]word_one_percent_key = list(word_one_percent_dict.keys())word_one_percent_value = list(word_one_percent_dict.values())word_two_percent_key = list(word_two_percent_dict.keys())word_two_percent_value = list(word_two_percent_dict.values())for word_two_per in word_two_percent_key:tmp_dis = []for word_one_per in word_one_percent_key:if word_two_per in trans[word_one_per]:tmp_num = dis[i][word_one_per] * ((trans[word_one_per][word_two_per] + 1) / (part[word_one_per] + part_len)) * (text_percent[i + 1][word_two_per] / part[word_two_per])tmp_dis.append(tmp_num)else:tmp_num = dis[i][word_one_per] * (1 / (part[word_one_per] + part_len)) * (text_percent[i + 1][word_two_per] / part[word_two_per])tmp_dis.append(tmp_num)max_tmp_dis = max(tmp_dis)max_tmp_dis_loc = tmp_dis.index(max_tmp_dis)dis[i + 1][word_two_per] = max_tmp_disnode[i + 1][word_two_per] = word_one_percent_key[max_tmp_dis_loc]# print(dis, node)# 根据node来倒找答案path = []f_value = list(dis[len(dis) - 1].values())f_key = list(dis[len(dis) - 1].keys())f = f_key[f_value.index(max(f_value))]path.append(f)for i in range(len(dis) - 1, 0, -1):f = node[i][f]path.append(f)path.reverse()return path# 对所有训练集进行测试
test_file = open("renmincixing.csv", "r")
reader = csv.reader(test_file)
test_sents = []
ans_sents = []
fenci_sents = []
for item in reader:test_sent = ""ans_sent = []fenci_sent = []for word in item:word_word = word.split('/')[0].split('{')[0].strip('[')word_part = word.split('/')[-1].split(']')[0].split('!')[0]if word_word == '。' and word_word == '!' and word_word == '?':test_sent += word_word.strip()ans_sent.append(word_word)fenci_sent.append(word_part)breakelse:test_sent += word_word.strip()ans_sent.append(word_word)fenci_sent.append(word_part)test_sents.append(test_sent)ans_sents.append(ans_sent)fenci_sents.append(fenci_sent)# 将分词出来的结果转换为集合中元素
def zhuan_huan(text: list):ans = []i = 1for word in text:ans.append([i, i + len(word) - 1])i += len(word)return anstest_sents_num = len(test_sents)
print(test_sents_num)
P = 0
R = 0
A = 0
A_num = 0
for i in range(test_sents_num):xun_lian = fen_ci(test_sents[i])xun_lian_list = zhuan_huan(xun_lian)ans_list = zhuan_huan(ans_sents[i])xun_lian_set = set()for tmp in xun_lian_list:xun_lian_set.add(tuple(tmp))ans_list_set = set()for tmp in ans_list:ans_list_set.add(tuple(tmp))TP = ans_list_set & xun_lian_setp = len(TP) / len(xun_lian_list)r = len(TP) / len(ans_list)# 我们只对分词正确的结果进行词性正确性评估if ans_list_set == xun_lian_set:A_num += 1# 预测来的ci_xing_list = ci_xing(ans_sents[i])# 正确答案ci_xing_ans = fenci_sents[i]a = 0for j in range(len(ci_xing_list)):if ci_xing_list[j] == ci_xing_ans[j]:a += 1a = a / len(ci_xing_list)A += aP += pR += rif i % 100 == 0:print(i / test_sents_num)# 求一个平均值
P = P / test_sents_num
R = R / test_sents_num
F_1 = 2 * P * R / (P + R)
print("P,R,F1", P, R, F_1)
A = A / A_num
print("A", A)
end_time = time.time()
print(end_time - start_time)
附录三
import csvmat = []with open("renmin.txt", "r") as f: # 打开文件for line in f:mat.append([l for l in line.split()])print(mat)with open('renmin.csv', 'w', newline='') as csvfile:writer = csv.writer(csvfile)for row in mat:if len(row) != 0:writer.writerow(row)
import csvmat = []with open("renmincixing.txt", "r") as f: # 打开文件for line in f:line = line[22:]print(line)mat.append([l for l in line.split()])print(mat)with open('renmincixing.csv', 'w', newline='') as csvfile:writer = csv.writer(csvfile)for row in mat:if len(row) != 0:writer.writerow(row)源码地址
GitHub