使用 python 实现基于Hmm模型和Viterbi算法的中文分词及词性标注;使用 最大概率算法 进行优化。最终效果:人民日报语料:分词(F1:96.189%);词性标注(F1:97.934%)
完整代码和数据,参见本实验的 github地址:https://github.com/xuzf-git/WordSegment-and-PosTag
1、基于统计的分词方法(隐马尔可夫模型)
(1)算法设计
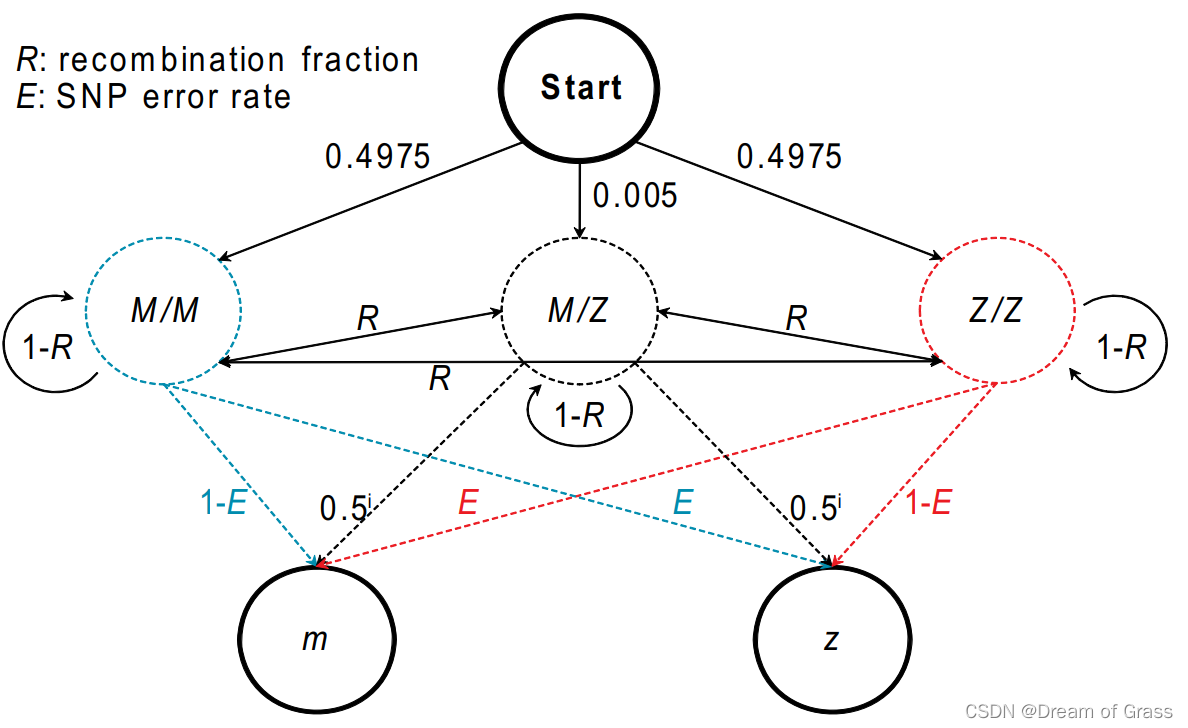
采用隐马尔科夫(Hmm)模型进行统计分词。使用BMES标注方法,将分词任务转换为字标注的问题,通过对每个字进行标注得到词语的划分。具体来说,BMES标注方法是用“B、M、E、S”四种标签对词语中不同位置的字符进行标注,B表示一个词的词首位置,M表示一个词的中间位置,E表示一个词的末尾位置,S表示一个单独的字。
字标注的问题可视为隐马尔可夫模型中的解码问题。句子的BMES标注序列作为隐藏状态序列,句子的字符序列作为可观测序列,通过以下两个步骤实现分词:
-
学习模型参数
对预料进行统计,获得隐藏状态的转移概率矩阵trans、发射概率矩阵emit 、初始状态矩阵start- 观测序列 O O O :句子的字符序列 [ w 0 , w 1 , … … w n ] [w_0,w_1,……w_n] [w0,w1,……wn]
- 隐藏序列 S S S:BMES标注序列 [ p 0 , p 1 , … … p n ] [p_0,p_1,……p_n] [p0,p1,……pn]
- 初始概率 π \pi π : s t a r t ( i ) = P ( p 0 = i ) = c o u n t ( p 0 = i ) / c o u n t ( s e n t e n c e ) i ∈ { B 、 M 、 E 、 D } start(i)=P_{(p_0=i)}=count(p_0=i)/count(sentence) \quad i\in\{B、M、E、D\} start(i)=P(p0=i)=count(p0=i)/count(sentence)i∈{B、M、E、D}
- 转移概率 t r a n s trans trans : t r a n s ( i , j ) = P ( j │ i ) = c o u n t ( p k = i , p k + 1 = j ) / c o u n t ( i ) i , j ∈ { B 、 M 、 E 、 D } trans(i,j)=P(j│i)=count(p_k=i ,p_{k+1}=j)/count(i) i,j \in\{B、M、E、D\} trans(i,j)=P(j│i)=count(pk=i,pk+1=j)/count(i)i,j∈{B、M、E、D}
- 发射概率 e m i t emit emit : e m i t ( i , w ) = P ( w │ i ) = c o u n t ( s t a t e ( w ) = i ) / c o u n t ( i ) i ∈ { B 、 M 、 E 、 D } emit(i,w)=P(w│i)=count(state(w)=i)/count(i) \quad i\in\{B、M、E、D\} emit(i,w)=P(w│i)=count(state(w)=i)/count(i)i∈{B、M、E、D},
-
使用 Viterbi 算法预测
Viterbi算法是用动态规划的方法求解最优的标注序列。每个标注序列视为从句首到句尾的一个路径,通过Viterbi算法获取概率最大的路径,在主要由以下几步实现:- 状态 d p [ i ] [ j ] dp[i][j] dp[i][j]:表示第 i i i个字符,标签为 j j j 的所有路径中的最大概率。
- 记录路径 p a t h [ i ] [ j ] path[i][j] path[i][j]:表示 d p [ i ] [ j ] dp[i][j] dp[i][j]为最大概率时,第 i − 1 i-1 i−1个字符的标签
- 状态初始化: d p [ 0 ] [ j ] = s t a r t ( j ) e m i t ( j , w 0 ) dp[0][j] =start(j) emit(j,w_0) dp[0][j]=start(j)emit(j,w0)
- 递推(状态转移方程): d p [ i ] [ j ] = m a x k ∈ { p o s } ( d p [ i − 1 ] [ k ] × t r a n s [ k , j ] ) × e m i t [ j , w i ] dp[i][j]= max_{k\in \{pos\}}(dp[i-1][k]×trans[k,j]) × emit[j,w_i] dp[i][j]=maxk∈{pos}(dp[i−1][k]×trans[k,j])×emit[j,wi]
- 记录路径: p a t h [ i ] [ j ] = a r g m a x k ∈ { p o s } ( d p [ i − 1 ] [ k ] × t r a n s [ k , j ] ) path[i][j]=argmax_{k∈\{pos\}}(dp[i-1][k]×trans[k,j]) path[i][j]=argmaxk∈{pos}(dp[i−1][k]×trans[k,j])
- 回溯最优路径: p i = p a t h [ i + 1 ] [ p ( i + 1 ) ] i = n − 1 , n − 2 , … … 1 , 0 p_i=path[i+1][p_(i+1) ] \quad i=n-1,n-2,……1,0 pi=path[i+1][p(i+1)]i=n−1,n−2,……1,0
- 输出最优路径: [ p 1 , p 2 … … p n ] [p_1,p_2……p_n] [p1,p2……pn]
(2)程序结构
import time
import json
import pandas as pdclass Hmm:def __init__(self):self.trans_p = {'S': {}, 'B': {}, 'M': {}, 'E': {}}self.emit_p = {'S': {}, 'B': {}, 'M': {}, 'E': {}}self.start_p = {'S': 0, 'B': 0, 'M': 0, 'E': 0}self.state_num = {'S': 0, 'B': 0, 'M': 0, 'E': 0}self.state_list = ['S', 'B', 'M', 'E']self.line_num = 0self.smooth = 1e-6@staticmethoddef __state(word):"""获取词语的BOS标签,标注采用 4-tag 标注方法,tag = {S,B,M,E},S表示单字为词,B表示词的首字,M表示词的中间字,E表示词的结尾字Args:word (string): 函数返回词语 word 的状态标签"""if len(word) == 1:state = ['S']else:state = list('B' + 'M' * (len(word) - 2) + 'E')return statedef train(self, filepath, save_model=False):"""训练hmm, 学习发射概率、转移概率等参数Args:save_model: 是否保存模型参数filepath (string): 训练预料的路径"""print("正在训练模型……")start_time = time.thread_time()with open(filepath, 'r', encoding='utf8') as f:for line in f.readlines():self.line_num += 1line = line.strip().split()# 获取观测(字符)序列char_seq = list(''.join(line))# 获取状态(BMES)序列state_seq = []for word in line:state_seq.extend(self.__state(word))# 判断是否等长assert len(char_seq) == len(state_seq)# 统计参数for i, s in enumerate(state_seq):self.state_num[s] = self.state_num.get(s, 0) + 1.0self.emit_p[s][char_seq[i]] = self.emit_p[s].get(char_seq[i], 0) + 1.0if i == 0:self.start_p[s] += 1.0else:last_s = state_seq[i - 1]self.trans_p[last_s][s] = self.trans_p[last_s].get(s, 0) + 1.0# 归一化:self.start_p = {k: (v + 1.0) / (self.line_num + 4)for k, v in self.start_p.items()}self.emit_p = {k: {w: num / self.state_num[k]for w, num in dic.items()}for k, dic in self.emit_p.items()}self.trans_p = {k1: {k2: num / self.state_num[k1]for k2, num in dic.items()}for k1, dic in self.trans_p.items()}end_time = time.thread_time()print("训练完成,耗时 {:.3f}s".format(end_time - start_time))# 保存参数if save_model:parameters = {'start_p': self.start_p,'trans_p': self.trans_p,'emit_p': self.emit_p}jsonstr = json.dumps(parameters, ensure_ascii=False, indent=4)param_filepath = "./data/HmmParam_Token.json"with open(param_filepath, 'w', encoding='utf8') as jsonfile:jsonfile.write(jsonstr)def viterbi(self, text):"""Viterbi 算法Args:text (string): 句子Returns:list: 最优标注序列"""text = list(text)dp = pd.DataFrame(index=self.state_list)# 初始化 dp 矩阵 (prop,last_state)dp[0] = [(self.start_p[s] * self.emit_p[s].get(text[0], self.smooth),'_start_') for s in self.state_list]# 动态规划地更新 dp 矩阵for i, ch in enumerate(text[1:]): # 遍历句子中的每个字符 chdp_ch = []for s in self.state_list: # 遍历当前字符的所有可能状态emit = self.emit_p[s].get(ch, self.smooth)# 遍历上一个字符的所有可能状态,寻找经过当前状态的最优路径(prob, last_state) = max([(dp.loc[ls, i][0] * self.trans_p[ls].get(s, self.smooth) *emit, ls) for ls in self.state_list])dp_ch.append((prob, last_state))dp[i + 1] = dp_ch# 回溯最优路径path = []end = list(dp[len(text) - 1])back_point = self.state_list[end.index(max(end))]path.append(back_point)for i in range(len(text) - 1, 0, -1):back_point = dp.loc[back_point, i][1]path.append(back_point)path.reverse()return pathdef cut(self, text):"""根据 viterbi 算法获得状态,根据状态切分句子Args:text (string): 待分词的句子Returns:list: 分词列表"""state = self.viterbi(text)cut_res = []begin = 0for i, ch in enumerate(text):if state[i] == 'B':begin = ielif state[i] == 'E':cut_res.append(text[begin:i + 1])elif state[i] == 'S':cut_res.append(text[i])return cut_res# if __name__ == "__main__":
# hmm = Hmm()
# hmm.train('./data/PeopleDaily_Token.txt', save_model=True)
# cutres = hmm.cut('中央电视台收获一批好剧本')
# print(cutres)
2、基于字典的分词方法(最短路分词模型)
(1) 算法设计
最短路分词模型的主要思想是将句子中的所有字符当作节点,根据字典找出句子中所有的词语,将词语两端的字符连接起来,构成从词首指向词尾的一条边。通过找出所有的候选词,构建出一个有向无环图(DAG)。找到从句首字符到句尾字符的最短路径,即可作为句子的分词结果。最短路径分词方法采用的规则使切分出来的词数最少,符合汉语自身的规律。
最短路分词算法,由以下几个步骤实现:
- 构造句子的切分图,如果句子 s e n t e n c e sentence sentence 的子串 w [ i : j ] w[i:j] w[i:j] 在词典中,则添加边 V ( i , j ) V(i,j) V(i,j),得到句子的有向无环图 DAG
- 采用Dijkstra 算法动态规划地求解最短路径, d p [ i ] dp[i] dp[i] 表示DAG中句首到第 i i i 个字符的路径长度
- 状态转移函数如下: d p [ i ] = m i n d p [ j − 1 ] + 1 dp[i] = min{dp[j-1] + 1} dp[i]=mindp[j−1]+1 ;其中: i i i 为当前边的起点, j j j 为当前边的终点。
- 回溯最优路径
(2)程序结构
import json
import math
import timeclass ShortTokenizer:def __init__(self, use_freq=True):self.word_freq = {}self.word_num = 0self.use_freq = use_freqdef train(self, filepath, trained=False):"""根据训练语料统计词频Args:filepath (string): 训练语料文件路径trained (bool): 模型是否已经训练"""if not trained:# 统计词频print("正在训练模型……")stime = time.thread_time()with open(filepath, 'r', encoding='utf8') as f:for line in f.readlines():line = line.strip().split()self.word_num += len(line)self.word_freq.update({i: self.word_freq.get(i, 0) + 1 for i in line})etime = time.thread_time()print("训练完成,耗时{}s".format(etime - stime))# 保存词频jsonstr = json.dumps(self.word_freq, ensure_ascii=False, indent=4)with open('./data/word_freq_npath.json', 'w',encoding='utf8') as f:f.write(jsonstr)else:# 读入词频with open(filepath, 'r', encoding='utf8') as f:jsonstr = ''.join(f.readlines())self.word_freq = json.loads(jsonstr)self.word_num = sum(self.word_freq.values())def __weight(self, word):"""计算word的词频 -log(P(w)) = log(num) - log(k_w)Args:word (string): 切分的词语,切分图上的一条边Returns:float: 词典中存在该词返回 -log(P),否则返回0"""freq = self.word_freq.get(word, 0)if freq and self.use_freq:return math.log(self.word_num) - math.log(freq)elif freq:return 1else:return 0def Token(self, sentence):"""结合统计信息的最短路分词函数(最大概率分词)Args:sentence (string): 待切分的句子Returns:list: 切分的词语,构成的 list"""length = len(sentence)# 构造句子的切分图graph = {}for i in range(length):graph[i] = []for j in range(i):freq = self.__weight(sentence[j:i + 1])if freq:graph[i].append((j, freq))# 动态规划求解最优路径 ( arg min[-log(P)] )# 初始化DP矩阵dp = [(i, self.__weight(sentence[i])) for i in range(length)]dp.insert(0, (-1, 0))# 状态转移函数:dp[i] = min{dp[j-1] + weight(sentence[j:i])}# i:为当前词的词尾;j: 为当前词的词头for i in range(2, len(dp)):index = dp[i][0]cost = dp[i][1] + dp[i - 1][1]for j, freq in graph[i - 1]:if freq + dp[j][1] < cost:cost = freq + dp[j][1]index = jdp[i] = (index, cost)# 回溯最优路径token_res = []break_p = lengthwhile break_p > 0:token_res.append(sentence[dp[break_p][0]:break_p])break_p = dp[break_p][0]token_res.reverse()return token_res# if __name__ == "__main__":
# Tokenizer = ShortTokenizer()
# # Tokenizer.train('./data/PeopleDaily_Token.txt')
# Tokenizer.train('./data/word_freq_npath.json', trained=True)
# Tokenizer.Token('迈向充满希望的新世纪')
# Tokenizer.Token('1997年,是中国发展历史上非常重要的很不平凡的一年。')
3、改进最短路分词模型(最大概率模型)
(1)算法设计
最短路分词方法构建有向无环图DAG的过程中,只要词语在字典中出现即可添加边,忽略了成词的概率。现在考虑成词的概率,通过极大似然估计,以词频表示成词概率,为DAG的每条边赋予权重,优化分词结果。通过 Dijkstra 算法求得的带权最短路径即为所有分词结果中概率最大的分词方法。该分词方法本质上是使用了1-gram文法的最大概率分词模型。
(2)程序结构
同最短路分词模型的实现程序,实例化模型时传入 use_freq = True 参数。
4、隐马尔可夫模型进行词性标注
(1)算法设计
词性标注是序列标注问题,可采用Hmm模型的解码问题的解决方法。将词性序列作为隐藏序列,将词语序列作为观测序列,同过Viterbi算法预测最优的词性序列。算法实现步骤同 1、基于统计的分词方法(隐马尔可夫模型)
(2)程序结构
import json
import math
import pandas as pdclass HmmPosTag:def __init__(self):self.trans_prop = {}self.emit_prop = {}self.start_prop = {}self.poslist = []self.trans_sum = {}self.emit_sum = {}def __upd_trans(self, curpos, nxtpos):"""更新转移概率矩阵Args:curpos (string): 当前词性nxtpos (string): 下一词性"""if curpos in self.trans_prop:if nxtpos in self.trans_prop[curpos]:self.trans_prop[curpos][nxtpos] += 1else:self.trans_prop[curpos][nxtpos] = 1else:self.trans_prop[curpos] = {nxtpos: 1}def __upd_emit(self, pos, word):"""更新发射概率矩阵Args:pos (string): 词性word (string): 词语"""if pos in self.emit_prop:if word in self.emit_prop[pos]:self.emit_prop[pos][word] += 1else:self.emit_prop[pos][word] = 1else:self.emit_prop[pos] = {word: 1}def __upd_start(self, pos):"""更新初始状态矩阵Args:pos (string): 初始词语的词性"""if pos in self.start_prop:self.start_prop[pos] += 1else:self.start_prop[pos] = 1def train(self, data_path):"""训练 hmm 模型、求得转移矩阵、发射矩阵、初始状态矩阵Args:data_path (string): 训练数据的路径"""f = open(data_path, 'r', encoding='utf-8')for line in f.readlines():line = line.strip().split()# 统计初始状态的概率self.__upd_start(line[0].split('/')[1])# 统计转移概率、发射概率for i in range(len(line) - 1):self.__upd_emit(line[i].split('/')[1], line[i].split('/')[0])self.__upd_trans(line[i].split('/')[1], line[i + 1].split('/')[1])i = len(line) - 1self.__upd_emit(line[i].split('/')[1], line[i].split('/')[0])f.close()# 记录所有的 posself.poslist = list(self.emit_prop.keys())self.poslist.sort()# 统计 trans、emit 矩阵中各个 pos 的归一化分母num_trans = [sum(self.trans_prop[key].values()) for key in self.trans_prop]self.trans_sum = dict(zip(self.trans_prop.keys(), num_trans))num_emit = [sum(self.emit_prop[key].values()) for key in self.emit_prop]self.emit_sum = dict(zip(self.emit_prop.keys(), num_emit))def predict(self, sentence):"""Viterbi 算法预测词性Args:sentence (string): 分词后的句子(空格隔开)Returns:list: 词性标注序列 """sentence = sentence.strip().split()posnum = len(self.poslist)dp = pd.DataFrame(index=self.poslist)path = pd.DataFrame(index=self.poslist)# 初始化 dp 矩阵(DP 矩阵: posnum * wordsnum 存储每个 word 每个 pos 的最大概率)start = []num_sentence = sum(self.start_prop.values()) + posnumfor pos in self.poslist:sta_pos = self.start_prop.get(pos, 1e-16) / num_sentencesta_pos *= (self.emit_prop[pos].get(sentence[0], 1e-16) /self.emit_sum[pos])sta_pos = math.log(sta_pos)start.append(sta_pos)dp[0] = start# 初始化 path 矩阵path[0] = ['_start_'] * posnum# 递推for t in range(1, len(sentence)): # 句子中第 t 个词prob_pos, path_point = [], []for i in self.poslist: # i 为当前词的 posmax_prob, last_point = float('-inf'), ''emit = math.log(self.emit_prop[i].get(sentence[t], 1e-16) / self.emit_sum[i])for j in self.poslist: # j 为上一次的 postmp = dp.loc[j, t - 1] + emittmp += math.log(self.trans_prop[j].get(i, 1e-16) / self.trans_sum[j])if tmp > max_prob:max_prob, last_point = tmp, jprob_pos.append(max_prob)path_point.append(last_point)dp[t], path[t] = prob_pos, path_point# 回溯prob_list = list(dp[len(sentence) - 1])cur_pos = self.poslist[prob_list.index(max(prob_list))]path_que = []path_que.append(cur_pos)for i in range(len(sentence) - 1, 0, -1):cur_pos = path[i].loc[cur_pos]path_que.append(cur_pos)# 返回结果postag = []for i in range(len(sentence)):postag.append(sentence[i] + '/' + path_que[-i - 1])return postagif __name__ == "__main__":# data_clean()hmm = HmmPosTag()hmm.train("./data/PeopleDaily_clean.txt")hmm.predict("在 这 一 年 中 , 中国 的 改革 开放 和 现代化 建设 继续 向前 迈进 再次 获得 好 的 收成 ")# 1. 语料库中有 26 个基本词类标记
# 形容词a、区别词b、连词c、副词d、叹词e、方位词f、语素g、前接成分h、成语i、
# 简称j、后接成分k、习惯用语l、数词m、名词n、拟声词o、介词p、量词q、代词r、
# 处所词s、时间词t、助词u、动词v、标点符号w、非语素字x、语气词y、状态词z、
#
#
# 2. 语料库中还有 74 个扩充标记:对于语素,具体区分为 Ag Bg Dg Mg Ng Rg Tg Vg Yg
#
#
# 3. 词性标注只标注基本词性,因此在数据清洗的过程中,将扩充标记归类到各个基本词类中,语素也归类到相应词类中
5、实验结果评估
采用1998年人民日报语料库进行评估,分别用以上算法实现分词、词性标注。评价指标包括精确率precision、召回率recall、F1分数、算法效率。
(1) 对分词模型进行评估
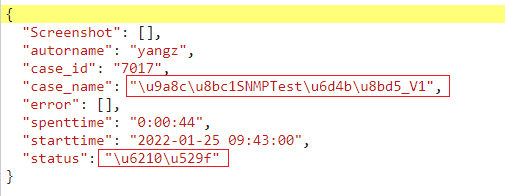
选取语料库中的6000行数据进行评估,运行结果如下图:

由评估结果可知,最大概率分词模型效果最优,相较于最短路径模型有3% 的提升;Hmm 模型运行效率远低于其他两个模型,且效果不佳。
(2) 对词性标注模型进行评估
选取语料库中的2000行数据进行评估,运行结果如下图:

运行结果第一项是对标准分词结果进行词性标注,运行结果第二项是对最大概率分词模型的预测结果进行分词(只有当词语被正确划分出并且词性标注争取时才会被标记为预测正确)
6、问题及解决方法
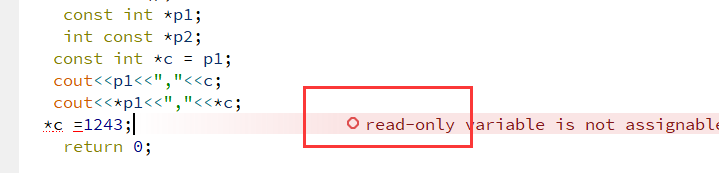
- 问题:Hmm 模型中,大部分词语的发射概率较低,随着句子长度的增加(约为120词),路径的概率变得很小,程序下溢。路径概率取对数,概率相乘转化为对数相加,避免路径概率下溢
- 对于 Hmm 模型中出现的未登录词(字)采用 Laplace 平滑处理。由于某些字、词出现很少,如果采用加一平滑会导致发射概率过大的问题,因此采用较小的 λ = 1e-6
- 预料库将人名的姓和名拆分成两个词,将组合的实体名也有拆分,在数据清洗时,我将这两类进行了合并。λ