A星算法代码python3实现
- 前言
- 一、A*? A星
- 1.一个搜索算法
- 2.结果展示
- 二、使用环境
- 1.python 3.x
- 2.一些解释说明
- 一些话
前言
产生本文的缘由
学校计科课程要求的小作业, 在csdn上看了好多, 记录一下自己的学习
以下是本篇文章正文内容
一、A*? A星
1.一个搜索算法
和深度搜索, 广度搜索类似, 能更快的找一条从起点到终点的路径.
我参考的算法文章来自 https://blog.csdn.net/hitwhylz/article/details/23089415
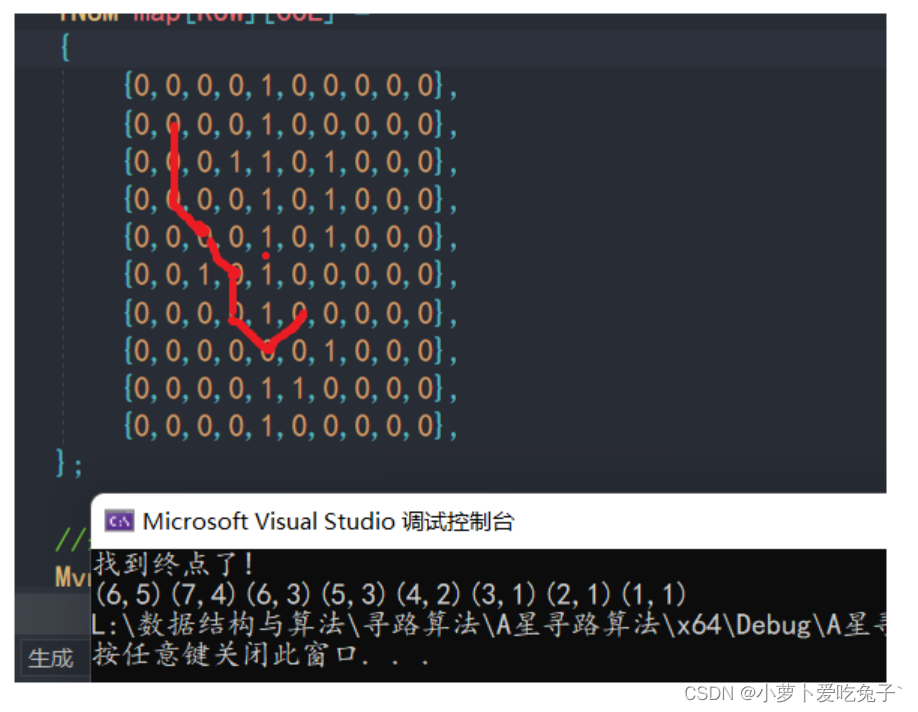
2.结果展示
圆圈表示地图坐标, 方块表示墙壁 , ※表示路径
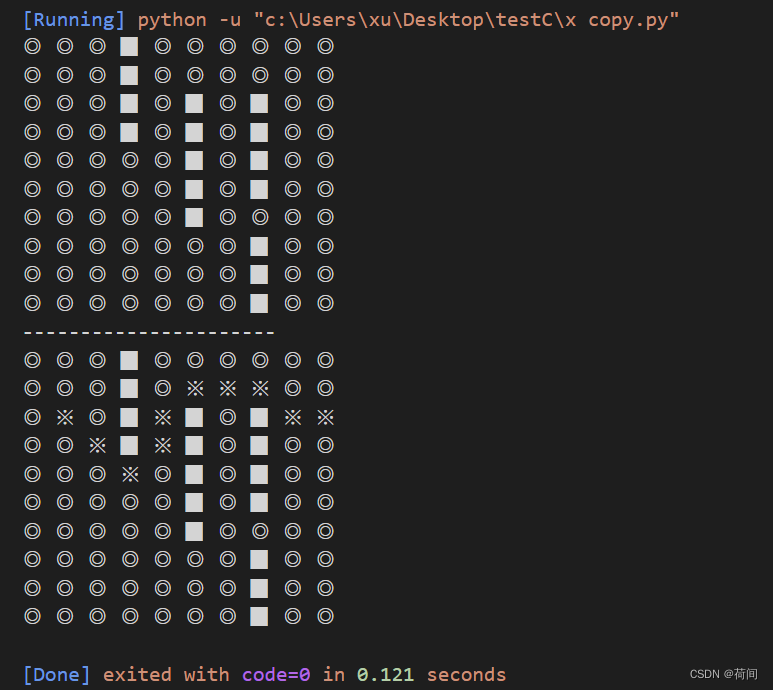
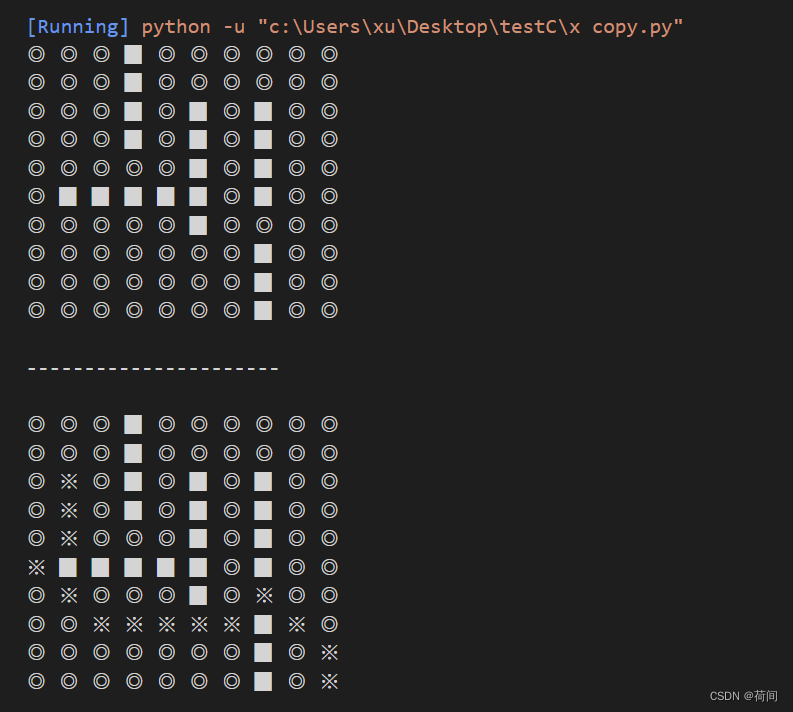
二、使用环境
1.python 3.x
代码如下(示例):大家可以直接复制到一个.py文件里面直接运行即可
class Array2D:"""说明:1.构造方法需要两个参数,即二维数组的宽和高2.成员变量w和h是二维数组的宽和高3.使用:‘对象[x][y]’可以直接取到相应的值4.数组的默认值都是0"""def __init__(self, h, w):self.w = wself.h = hself.data = []self.data = [[0 for y in range(w)] for x in range(h)]def showArray2D(self):for x in range(self.h):for y in range(self.w):if self.data[x][y] == 0:print("◎", end=' ')elif self.data[x][y] == 1:print("▉",end=' ')else:print("※",end=' ')print("")def __getitem__(self, item):return self.data[item]class Point:"""表示一个点"""def __init__(self, x, y):self.x = xself.y = ydef __eq__(self, other):if self.x == other.x and self.y == other.y:return Truereturn Falsedef __str__(self):return "x:"+str(self.x)+",y:"+str(self.y)class AStar:"""AStar算法的Python3.x实现"""class Node: # 描述AStar算法中的节点数据def __init__(self, point, endPoint, g=0):self.point = point # 自己的坐标self.father = None # 父节点self.g = g # g值,g值在用到的时候会重新算self.h = (abs(endPoint.x - point.x) +abs(endPoint.y - point.y)) * 10 # 计算h值def __init__(self, map2d, startPoint, endPoint, passTag=0):"""构造AStar算法的启动条件:param map2d: Array2D类型的寻路数组:param startPoint: Point或二元组类型的寻路起点:param endPoint: Point或二元组类型的寻路终点:param passTag: int类型的可行走标记(若地图数据!=passTag即为障碍)"""# 开启表self.openList = []# 关闭表self.closeList = []# 寻路地图self.map2d = map2d# 起点终点if isinstance(startPoint, Point) and isinstance(endPoint, Point):self.startPoint = startPointself.endPoint = endPointelse:self.startPoint = Point(*startPoint)self.endPoint = Point(*endPoint)# 可行走标记self.passTag = passTag# def getMinNode(self):# """# 获得openlist中F值最小的节点# :return: Node# """# currentNode = self.openList[0]# for node in self.openList:# if node.g + node.h < currentNode.g + currentNode.h:# currentNode = node# return currentNodedef pointInCloseList(self, point):for node in self.closeList:if node.point == point:return Truereturn Falsedef pointInOpenList(self, point):for node in self.openList:if node.point == point:return nodereturn Nonedef endPointInCloseList(self):for node in self.openList:if node.point == self.endPoint:return nodereturn Nonedef searchNear(self, minF, offsetX, offsetY):"""搜索节点周围的点:param minF:F值最小的节点:param offsetX:坐标偏移量:param offsetY::return:"""# 越界检测if minF.point.x + offsetX < 0 or minF.point.x + offsetX > self.map2d.w - 1 or minF.point.y + offsetY < 0 or minF.point.y + offsetY > self.map2d.h - 1:return# 如果是障碍,就忽略if self.map2d[minF.point.x + offsetX][minF.point.y + offsetY] != self.passTag:return# 如果在关闭表中,就忽略currentPoint = Point(minF.point.x + offsetX, minF.point.y + offsetY)if self.pointInCloseList(currentPoint):return# 设置单位花费if offsetX == 0 or offsetY == 0:step = 10else:step = 14# 如果不在openList中,就把它加入openlist ,并且使得openlist的首元素为f值最小的currentNode = self.pointInOpenList(currentPoint)if not currentNode:currentNode = AStar.Node(currentPoint, self.endPoint, g=minF.g + step)currentNode.father = minFfor item in self.openList:if item.g+item.h > currentNode.g+currentNode.h:self.openList.insert(self.openList.index(item), currentNode)breakif self.openList.count(currentNode) == 0:self.openList.append(currentNode)# self.openList.append(currentNode)return# 如果在openList中,判断minF到当前点的G是否更小if minF.g + step < currentNode.g: # 如果更小,就重新计算g值,并且改变fathercurrentNode.g = minF.g + stepcurrentNode.father = minFdef start(self):"""开始寻路:return: None或Point列表(路径)"""# 判断寻路终点是否是障碍if self.map2d[self.endPoint.x][self.endPoint.y] != self.passTag:return None# 1.将起点放入开启列表startNode = AStar.Node(self.startPoint, self.endPoint)self.openList.append(startNode)# 2.主循环逻辑while True:# 找到F值最小的点minF = self.openList[0]# 把这个点加入closeList中,并且在openList中删除它self.closeList.append(minF)self.openList.remove(minF)# 判断这个节点的周边8个节点self.searchNear(minF, 0, -1)self.searchNear(minF, 0, 1)self.searchNear(minF, -1, 0)self.searchNear(minF, 1, 0)self.searchNear(minF, -1, -1)self.searchNear(minF, 1, 1)self.searchNear(minF, -1, 1)self.searchNear(minF, 1, -1)# 判断是否终止point = self.endPointInCloseList()if point: # 如果终点在关闭表中,就返回结果# print("关闭表中")cPoint = pointpathList = []while True:if cPoint.father:pathList.append(cPoint.point)cPoint = cPoint.fatherelse:pathList.append(self.startPoint)# print(pathList)# print(list(reversed(pathList)))# print(pathList.reverse())return list(reversed(pathList))if len(self.openList) == 0:return Noneif __name__ == '__main__':# 创建一个10*10的地图map2d = Array2D(10 , 10)# 设置障碍map2d[0][3] = 1map2d[1][3] = 1map2d[2][3] = 1map2d[3][3] = 1map2d[2][5] = 1map2d[3][5] = 1map2d[4][5] = 1map2d[5][5] = 1map2d[6][5] = 1map2d[2][7] = 1map2d[3][7] = 1map2d[4][7] = 1map2d[5][7] = 1map2d[7][7] = 1map2d[8][7] = 1map2d[9][7] = 1map2d[5][1] = 1map2d[5][2] = 1map2d[5][3] = 1map2d[5][4] = 1# 显示地图当前样子map2d.showArray2D()# 创建AStar对象,并设置起点为0,0终点为9,0aStar = AStar(map2d, Point(2,1), Point(0,9))# 开始寻路pathList = aStar.start()# 遍历路径点,在map2d上以'8'显示for point in pathList:map2d[point.x][point.y] = 8# print(point)print()print("----------------------")print()# 再次显示地图map2d.showArray2D()2.一些解释说明
代码部分并非个人独立完成, 主体结构来自于下面的文章https://blog.csdn.net/qq_37682024/article/details/106592311
关键在于个人对其代码的修改部分, 有四个部分
一是算法实现部分, 他的代码其实没有完整实现那篇参考的算法文章,
具体在于self.openlist变量的改动, 在searchNear函数中 ,其实应该也不需要这样改,只是在算法参考文章中, 最好选择F值最小的那个要求 , 我希望能降一点时间复杂度, 直接获取self.openlist[0], 即最小F值元素. 同时删掉了getMinNode函数
以及对于当前位置周边的8个位置的探索 ,而不是仅仅局限于上下左右四个位置, 以至于无法形成斜边的路径, 也许作者是想使得路径不能有斜边吧, 可是这样那数字14的出现没有多大意义啊.
另外就是,对于算法参考的那篇文章, 墙角部分,大家可以自己去实现一下哦
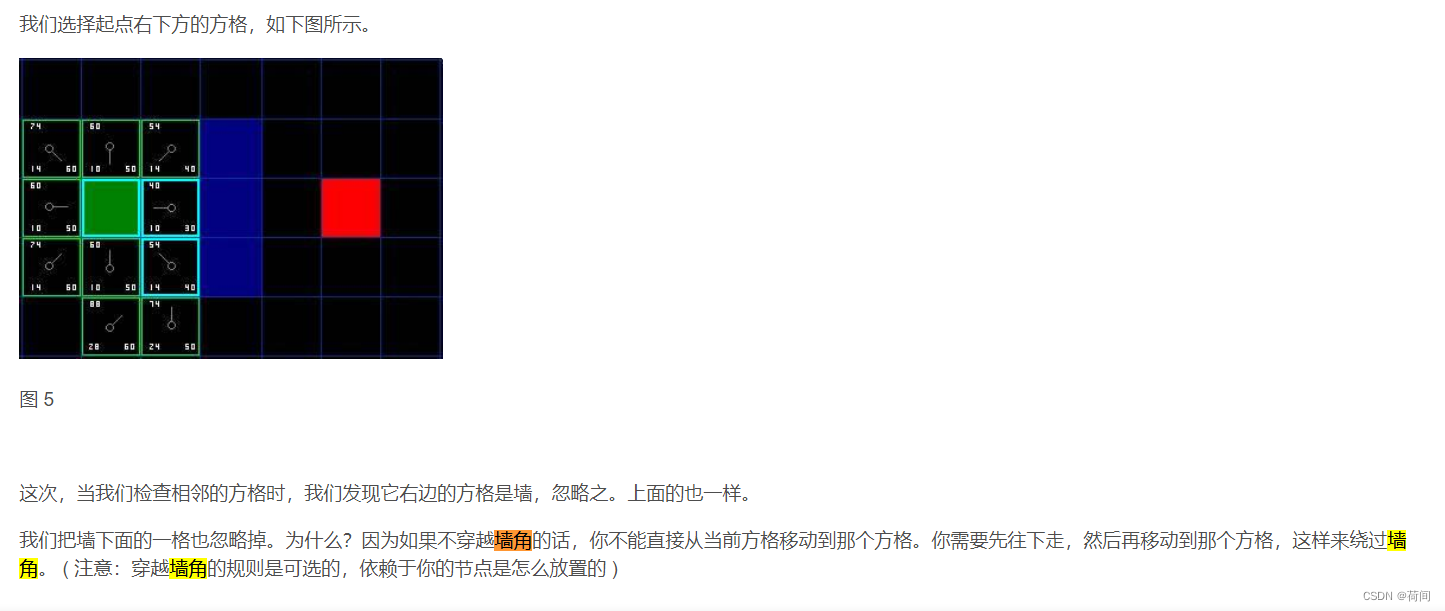
二是对于显示的符号的改动,更加直观
三是对于行列的描述部分, 修改后 w为列 , h为行, 本来想直接修改变量名的,但是其实也无伤大雅吧.
四是对于打印的链, 我增加了打印的起点
下面是对应修改的算法代码部分
# 如果不在openList中,就把它加入openlist ,并且使得openlist的首元素为f值最小的currentNode = self.pointInOpenList(currentPoint)if not currentNode:currentNode = AStar.Node(currentPoint, self.endPoint, g=minF.g + step)currentNode.father = minFfor item in self.openList:if item.g+item.h > currentNode.g+currentNode.h:self.openList.insert(self.openList.index(item), currentNode)breakif self.openList.count(currentNode) == 0:self.openList.append(currentNode)return
# 判断这个节点的周边8个节点self.searchNear(minF, 0, -1)self.searchNear(minF, 0, 1)self.searchNear(minF, -1, 0)self.searchNear(minF, 1, 0)self.searchNear(minF, -1, -1)self.searchNear(minF, 1, 1)self.searchNear(minF, -1, 1)self.searchNear(minF, 1, -1)
一些话
很感谢csdn的一些大佬们, 希望大家能创作更多的文章
真没想到下面的链接才是真正的作者, 我真的是服了, 真的是指针的指针了
似乎不找最小F值的元素, 仅仅只是把self.openlist全部遍历(类似广度搜索),也可以找到一条路径, 但是不是短路径就请读者去探索吧
感谢原作者,谢谢啦
狡猾的皮球
https://blog.csdn.net/qq_39687901/article/details/80753433











![[Database] 脏读、幻读这些都是什么?事务隔离级别又是什么?MySQL数据库的事务隔离级别都有哪些?](https://img-blog.csdnimg.cn/0b42b3bc46874658a5c93fe5e8c41c09.png)