前言
Seata AT 模式是一种非侵入式的分布式事务解决方案,Seata 在内部做了对数据库操作的代理层,我们使用 Seata AT 模式时,实际上用的是 Seata 自带的数据源代理 DataSourceProxy,Seata 在这层代理中加入了很多逻辑,比如插入回滚 undo_log 日志,检查全局锁等。
为什么要检查全局锁呢,这是由于 Seata AT 模式的事务隔离是建立在支事务的本地隔离级别基础之上的,在数据库本地隔离级别读已提交或以上的前提下,Seata 设计了由事务协调器维护的全局写排他锁,来保证事务间的写隔离,同时,将全局事务默认定义在读未提交的隔离级别上。
Seata 事务隔离级别解读
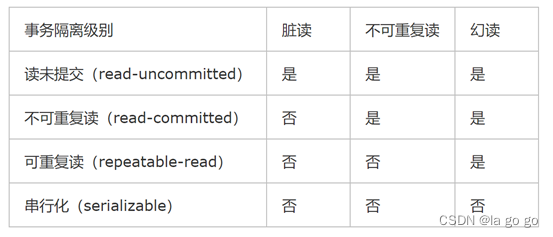
在讲 Seata 事务隔离级之前,我们先来回顾一下数据库事务的隔离级别,目前数据库事务的隔离级别一共有 4 种,由低到高分别为:
- Read uncommitted:读未提交
- Read committed:读已提交
- Repeatable read:可重复读
- Serializable:序列化
数据库一般默认的隔离级别为读已提交,比如 Oracle,也有一些数据的默认隔离级别为可重复读,比如 Mysql,一般而言,数据库的读已提交能够满足业务绝大部分场景了。
我们知道 Seata 的事务是一个全局事务,它包含了若干个分支本地事务,在全局事务执行过程中(全局事务还没执行完),某个本地事务提交了,如果 Seata 没有采取任务措施,则会导致已提交的本地事务被读取,造成脏读,如果数据在全局事务提交前已提交的本地事务被修改,则会造成脏写。
由此可以看出,传统意义的脏读是读到了未提交的数据,Seata 脏读是读到了全局事务下未提交的数据,全局事务可能包含多个本地事务,某个本地事务提交了不代表全局事务提交了。
在绝大部分应用在读已提交的隔离级别下工作是没有问题的,而实际上,这当中又有绝大多数的应用场景,实际上工作在读未提交的隔离级别下同样没有问题。
在极端场景下,应用如果需要达到全局的读已提交,Seata 也提供了全局锁机制实现全局事务读已提交。但是默认情况下,Seata 的全局事务是工作在读未提交隔离级别的,保证绝大多数场景的高效性。
全局锁实现
AT 模式下,会使用 Seata 内部数据源代理 DataSourceProxy,全局锁的实现就是隐藏在这个代理中。我们分别在执行、提交的过程都做了什么。
1、执行过程
执行过程在 StatementProxy 类,在执行过程中,如果执行 SQL 是 select for update,则会使用 SelectForUpdateExecutor 类,如果执行方法中带有 @GlobalTransactional or @GlobalLock注解,则会检查是否有全局锁,如果当前存在全局锁,则会回滚本地事务,通过 while 循环不断地重新竞争获取本地锁和全局锁。
io.seata.rm.datasource.exec.SelectForUpdateExecutor#doExecute
public T doExecute(Object... args) throws Throwable {Connection conn = statementProxy.getConnection();// ... ...try {// ... ...while (true) {try {// ... ...if (RootContext.inGlobalTransaction() || RootContext.requireGlobalLock()) {// Do the same thing under either @GlobalTransactional or @GlobalLock, // that only check the global lock here.statementProxy.getConnectionProxy().checkLock(lockKeys);} else {throw new RuntimeException("Unknown situation!");}break;} catch (LockConflictException lce) {if (sp != null) {conn.rollback(sp);} else {conn.rollback();}// trigger retrylockRetryController.sleep(lce);}}} finally {// ...}
2、提交过程
提交过程在 ConnectionProxy#doCommit方法中。
1)如果执行方法中带有@GlobalTransactional注解,则会在注册分支时候获取全局锁:
- 请求 TC 注册分支
io.seata.rm.datasource.ConnectionProxy#register
private void register() throws TransactionException {if (!context.hasUndoLog() || !context.hasLockKey()) {return;}Long branchId = DefaultResourceManager.get().branchRegister(BranchType.AT, getDataSourceProxy().getResourceId(),null, context.getXid(), null, context.buildLockKeys());context.setBranchId(branchId);
}
- TC 注册分支的时候,获取全局锁
io.seata.server.transaction.at.ATCore#branchSessionLock
protected void branchSessionLock(GlobalSession globalSession, BranchSession branchSession) throws TransactionException {if (!branchSession.lock()) {throw new BranchTransactionException(LockKeyConflict, String.format("Global lock acquire failed xid = %s branchId = %s", globalSession.getXid(),branchSession.getBranchId()));}
}
2)如果执行方法中带有@GlobalLock注解,在提交前会查询全局锁是否存在,如果存在则抛异常:
io.seata.rm.datasource.ConnectionProxy#processLocalCommitWithGlobalLocks
private void processLocalCommitWithGlobalLocks() throws SQLException {checkLock(context.buildLockKeys());try {targetConnection.commit();} catch (Throwable ex) {throw new SQLException(ex);}context.reset();
}
GlobalLock 注解说明
从执行过程和提交过程可以看出,既然开启全局事务 @GlobalTransactional注解可以在事务提交前,查询全局锁是否存在,那为什么 Seata 还要设计多处一个 @GlobalLock注解呢?
因为并不是所有的数据库操作都需要开启全局事务,而开启全局事务是一个比较重的操作,需要向 TC 发起开启全局事务等 RPC 过程,而@GlobalLock注解只会在执行过程中查询全局锁是否存在,不会去开启全局事务,因此在不需要全局事务,而又需要检查全局锁避免脏读脏写时,使用@GlobalLock注解是一个更加轻量的操作。
如何防止脏写
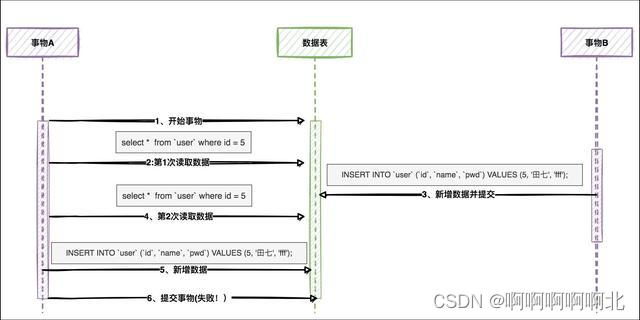
先来看一下使用 Seata AT 模式是怎么产生脏写的:

注:分支事务执行过程省略其它过程。
业务一开启全局事务,其中包含分支事务A(修改 A)和分支事务 B(修改 B),业务二修改 A,其中业务一执行分支事务 A 先获取本地锁,业务二则等待业务一执行完分支事务 A 之后,获得本地锁修改 A 并入库,业务一在执行分支事务时发生异常了,由于分支事务 A 的数据被业务二修改,导致业务一的全局事务无法回滚。
如何防止脏写?
1、业务二执行时加 @GlobalTransactional注解:

注:分支事务执行过程省略其它过程。
业务二在执行全局事务过程中,分支事务 A 提交前注册分支事务获取全局锁时,发现业务业务一全局锁还没执行完,因此业务二提交不了,抛异常回滚,所以不会发生脏写。
2、业务二执行时加 @GlobalLock注解:

注:分支事务执行过程省略其它过程。
与 @GlobalTransactional注解效果类似,只不过不需要开启全局事务,只在本地事务提交前,检查全局锁是否存在。
2、业务二执行时加 @GlobalLock 注解 + select for update语句:

如果加了select for update语句,则会在 update 前检查全局锁是否存在,只有当全局锁释放之后,业务二才能开始执行 updateA 操作。
如果单单是 transactional,那么就有可能会出现脏写,根本原因是没有 Globallock 注解时,不会检查全局锁,这可能会导致另外一个全局事务回滚时,发现某个分支事务被脏写了。所以加 select for update 也有个好处,就是可以重试。
如何防止脏读
Seata AT 模式的脏读是指在全局事务未提交前,被其它业务读到已提交的分支事务的数据,本质上是Seata默认的全局事务是读未提交。
那么怎么避免脏读现象呢?
业务二查询 A 时加 @GlobalLock 注解 + select for update语句:

加select for update语句会在执行 SQL 前检查全局锁是否存在,只有当全局锁完成之后,才能继续执行 SQL,这样就防止了脏读。

![[Database] 脏读、幻读这些都是什么?事务隔离级别又是什么?MySQL数据库的事务隔离级别都有哪些?](https://img-blog.csdnimg.cn/0b42b3bc46874658a5c93fe5e8c41c09.png)