论文名称:Deep Gaussian Scale Mixture Prior for Spectral Compressive Imaging
论文下载:link
论文年份:CVPR 2021
论文被引:18(2022/04/17)
论文代码:https://github.com/TaoHuang95/DGSMP
Abstract
In coded aperture snapshot spectral imaging (CASSI) system, the real-world hyperspectral image (HSI) can be reconstructed from the captured compressive image in a snapshot. Model-based HSI reconstruction methods employed hand-crafted priors to solve the reconstruction problem, but most of which achieved limited success due to the poor representation capability of these hand-crafted priors. Deep learning based methods learning the mappings between the compressive images and the HSIs directly achieved much better results. Yet, it is nontrivial to design a powerful deep network heuristically for achieving satisfied results. In this paper, we propose a novel HSI reconstruction method based on the Maximum a Posterior (MAP) estimation framework using learned Gaussian Scale Mixture (GSM) prior. Different from existing GSM models using hand-crafted scale priors (e.g., the Jeffrey’s prior), we propose to learn the scale prior through a deep convolutional neural network (DCNN). Furthermore, we also propose to estimate the local means of the GSM models by the DCNN. All the parameters of the MAP estimation algorithm and the DCNN parameters are jointly optimized through end-to-end training. Extensive experimental results on both synthetic and real datasets demonstrate that the proposed method outperforms existing state-of-the-art methods.
在编码孔径快照光谱成像 (coded aperture snapshot spectral imaging ,CASSI) 系统中,可以从快照中捕获的压缩图像重建真实世界的高光谱图像 (hyperspectral image,HSI)。基于模型的 HSI 重建方法采用手工制作的先验来解决重建问题,但由于这些手工制作的先验的表示能力差,大多数方法取得的成功有限。基于深度学习的方法学习压缩图像和 HSI 之间的映射直接取得了更好的结果。然而,启发式地设计强大的深度网络以获得满意的结果并非易事。在本文中,我们提出了一种新的 HSI 重建方法,该方法基于使用学习的高斯尺度混合 (Gaussian Scale Mixture ,GSM) 先验的最大后验 (MAP) 估计框架。与使用手工制作的尺度先验(例如,Jeffrey 先验)的现有 GSM 模型不同,我们建议通过深度卷积神经网络(DCNN)来学习尺度先验。此外,我们还建议通过 DCNN 估计 GSM 模型的局部均值。 MAP估计算法的所有参数和DCNN参数通过端到端训练联合优化。在合成数据集和真实数据集上的大量实验结果表明,所提出的方法优于现有的最先进方法。
1. Introduction
【HSI的应用】:
与传统的 RGB 图像相比,高光谱图像 (HSI) 具有更多的光谱波段,可以更准确地描述成像场景中的物质特征。凭借其丰富的光谱信息,HSI 有利于许多计算机视觉任务,例如对象识别 [33]、检测 [40] 和跟踪 [34]。
【CASSI的优势】:
传统的单一一维或二维传感器的成像系统需要很长时间来扫描场景,无法捕捉到动态物体。最近,许多编码孔径快照光谱成像 (CASSI) 系统 [8, 22, 23, 35] 被提出来以视频速率捕获 3D HSI。
【CASSI的原理】:
CASSI 利用物理掩模和分散器来调制不同波长的信号,并将所有调制信号混合以生成单个 2D 压缩图像。然后采用重建算法从 2D 压缩图像重建 3D HSI。如图 1 所示,从真实 CASSI 系统 [22] 捕获的 2D 压缩图像(测量)中重建了 28 个光谱带。

【已有研究的解决方案】
因此,重建算法在 CASSI 中起着关键作用。为了解决这个不适定的逆问题(ill-posed inverse problem),以前的基于模型的方法采用手工制作的先验来规范(regularize)重建过程。
- 在 GAP-TV [43] 中,引入了总变异先验来解决 HSI 重建问题。
- 基于 HSI 对某些字典具有稀疏表示的假设,基于稀疏的方法 [14, 17, 35] 利用 ℓ1 稀疏性来正则化解决方案。
- 考虑到 HSI 的像素具有很强的长程依赖性,还提出了基于非局部的方法 [18,38,48]。
【已有研究的局限性】
- 然而,基于模型的方法必须手动调整参数,除了重建速度慢之外,还导致重建质量有限。
【针对局限性的解决方案】
- 受用于自然图像恢复的深度卷积神经网络 (DCNN) [16, 47] 的成功启发,还提出了基于深度学习的 HSI 重建方法 [3, 36, 37]。
- 在 [36] 中,将迭代 HSI 重建算法展开为 DCNN,其中使用两个子网络来利用空间光谱先验。
- 在 [37] 中,还引入了非局部自相似性先验以进一步改进结果。
- 除了受优化启发的方法外,还提出了直接学习 2D 测量和 3D HSI 之间的映射函数的基于 DCNN 的方法 [22、24、41]。
- λ-net [24] 通过两级 DCNN 从 2D 测量的输入和掩码(mask)重建 HSI。
- TSA-Net [22] 在主干 U-Net [31] 中集成了三个空间光谱自注意力模块,并取得了最先进的结果。
尽管已经实现了有希望的 HSI 重建性能,但启发式地设计强大的 DCNN 并非易事。
关于不适定的逆问题补充说明:
图像处理中不适定问题(ill posed problem)或称为反问题(inverse Problem)的研究从20世纪末成为国际上的热点问题,成为现代数学家、计算机视觉和图像处理学者广为关注的研究领域。
数学和物理上的反问题(即已知y求x)的研究由来已久,法国数学家阿达马早在19世纪就提出了不适定问题的概念:称一个数学物理定解问题的解存在、唯一并且稳定的,则称该问题是适定的(Well Posed)。如果不满足适定性概念中的上述三条判据中的一条或几条,称该问题是不适定的。
典型的图像处理不适定问题包括:图像去噪(Image De-nosing),图像恢复(Image Restorsion),图像放大(Image Zooming),图像修补(Image Inpainting),图像去马赛克(image Demosaicing),图像超分辨(Image super-resolution )等。
参考资料:
https://blog.sciencenet.cn/home.php?mod=space&uid=1108283&do=blog&id=736648
https://www.zhihu.com/question/63725426
考虑到上述问题,在本文中,我们提出了一种可解释的 HSI 重建方法,该方法具有先验学习的高斯尺度混合 (Gaussian Scale Mixture,GSM)。本文的贡献如下:
- 提出了学习的 GSM 模型来利用 HSI 的空间光谱相关性。与现有的具有手工制作比例先验的 GSM 模型(例如,Jeffrey 的先验)不同,我们建议通过 DCNN 学习比例先验。
- GSM 模型的局部平均值被估计为空间光谱相邻像素的加权平均值。空间光谱相似性权重也由 DCNN 估计。
- HSI 重建问题被表述为具有学习的 GSM 模型的最大后验 (Maximum a Posteriori,MAP) 估计问题。 MAP 估计器中的所有参数都以端到端的方式联合优化。
- 在合成数据集和真实数据集上的大量实验结果表明,所提出的方法优于现有最先进的 HSI 重建方法。
2. Related Work
在此,我们简要回顾了传统的基于模型的 HSI 重建方法、最近提出的基于深度学习的 HSI 重建方法和用于信号建模的 GSM 模型。
2.1. Conventional model-based HSI reconstruction methods
从 2D 压缩图像重建 3D HSI 是 CASSI 系统的核心,通常借助各种手工制作的先验。
- 在 [7] 中提出了梯度投影算法来解决稀疏 HSI 重建问题。
- 在 [17] 中,基于字典学习的稀疏正则化器已被用于 HSI 重建。
- 在 [1, 14, 43] 中,还采用了总变差 (TV) 正则化器来抑制噪声和伪影。
- 在 [18] 中,HSI 的非局部自相似性和低秩特性得到了利用,从而获得了优越的 HSI 重建性能。
这些基于模型的方法的主要缺点是耗时且需要手动选择参数。
2.2. Deep learning-based HSI reconstruction
由于强大的学习能力,将 HSI 重建视为非线性映射问题的深度神经网络取得了比基于模型的方法更好的结果。
- 在 [41] 中,HSI 的初始估计首先通过 [1] 的方法获得,并通过 DCNN 进一步细化。
- λ-net [24] 通过两阶段程序重建 HSI,其中 HSI 首先由具有自我注意的生成对抗网络 (GAN) 重建,然后是细化阶段以进一步改进。
- 在 [22] 中,提出了具有空间光谱自注意力模块的 DCNN 来利用空间光谱相关性,从而获得最先进的性能。
- 除了启发式地设计 DCNN,还提出了基于展开优化的 HSI 重建算法的 DCNN [21]。
- 在 [36] 中,具有去噪先验的 HSI 重建算法被展开为深度神经网络。由于空间光谱先验没有被充分利用,[36]的方法取得了有限的成功。
- 为了利用 HSI 的非局部自相似性(Maximum a Posteriori),非局部子网络也被集成到 [37] 中提出的深度网络中,从而进一步改进。另一项工作是将深度降噪器应用到优化算法中,从而形成即插即用框架 [49]。
2.3. GSM models for signal modeling
作为经典的概率模型,高斯尺度混合(GSM)模型已被用于各种图像恢复任务。
- 在 [27] 中,GSM 模型用于表征图像去噪的小波系数分布。
- 在 [5] 中,提出了 GSM 模型来对稀疏代码进行建模,用于同时进行稀疏编码并应用于图像恢复。
- 在 [26, 32] 中,GSM 模型也被用于对视频的移动对象进行建模以进行前景估计,从而实现了良好的性能。
在本文中,我们建议使用用于 HSI 重建的 GSM 模型来表征 HSI 的分布。与现有的具有手动选择尺度先验的 GSM 模型不同,我们建议学习具有 DCNN 的 GSM 模型的尺度先验和局部均值。通过端到端的训练,所有的参数都是共同学习的。
3. The CASSI Observation Model
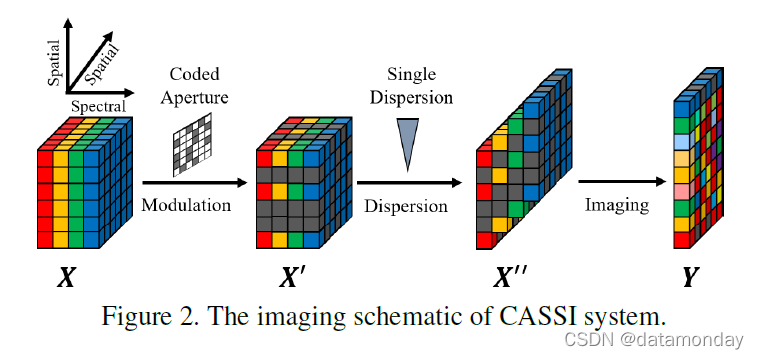
如图 2 所示,3D HSI 被 CASSI 系统编码为 2D 压缩图像。在 CASSI 系统中,3D 光谱数据立方体首先由编码孔径(coded aperture)(即物理掩模)进行空间调制。然后,下面的色散棱镜(dispersive prism)色散调制数据的每个波长。 2D 成像传感器捕获分散的数据并输出混合所有波长信息的 2D 测量值。

4. The Proposed Method
4.1. GSM models for CASSI

w 的解取决于所使用的 R(w)。对于某些先验,可以实现封闭形式的解决方案[26];对于其他人,可能会使用迭代算法。然而,他们每个人都有自己的优点和缺点。为了应对这一挑战,我们建议使用 DCNN 从 x ( t + 1 ) x^{(t+1)} x(t+1) 估计 w ( t + 1 ) w^{(t+1)} w(t+1),而不是使用手动设计的近端算子,这将在下一小节中描述。
4.2. Deep GSM for CASSI
通常,交替计算 x 和 w 需要多次迭代才能收敛,并且有必要强加 p(θ) 的手工先验。此外,所有算法参数和 3D 滤波器不能联合优化。为了解决这些问题,我们建议通过 DCNN 联合优化 x 和 w。出于网络设计的目的,我们通过一个统一的框架重新桥接 x 和 w 子问题
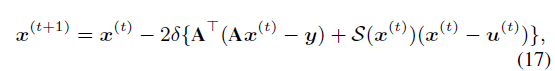
其中 S(·) 表示 DCNN 用于估计 w 的函数,即 (16) 的解。如图 3(a) 所示,我们构建了端到端网络,其中 T 个阶段对应于 T 次迭代,用于迭代优化 x 和 w。提出的网络由以下主要模块组成。
- 测量 y 被拆分为大小为 H × W × L 的 3D 数据立方体以初始化 x。
- 我们使用两个子网络来学习测量矩阵A 及其转置版本A⊤。
- 为了估计w,我们开发了U-Net 的轻量级变体和权重生成器来学习函数S(·)。
- 我们没有使用手动设计的方法来学习 3D 滤波器,而是使用相同的轻量级 U-Net 和 3D 滤波器生成器来生成空间变化滤波器。根据方程式(14),我们通过生成的 3D 滤波器过滤当前 x 以更新均值 u。
4.3. Network Architecture
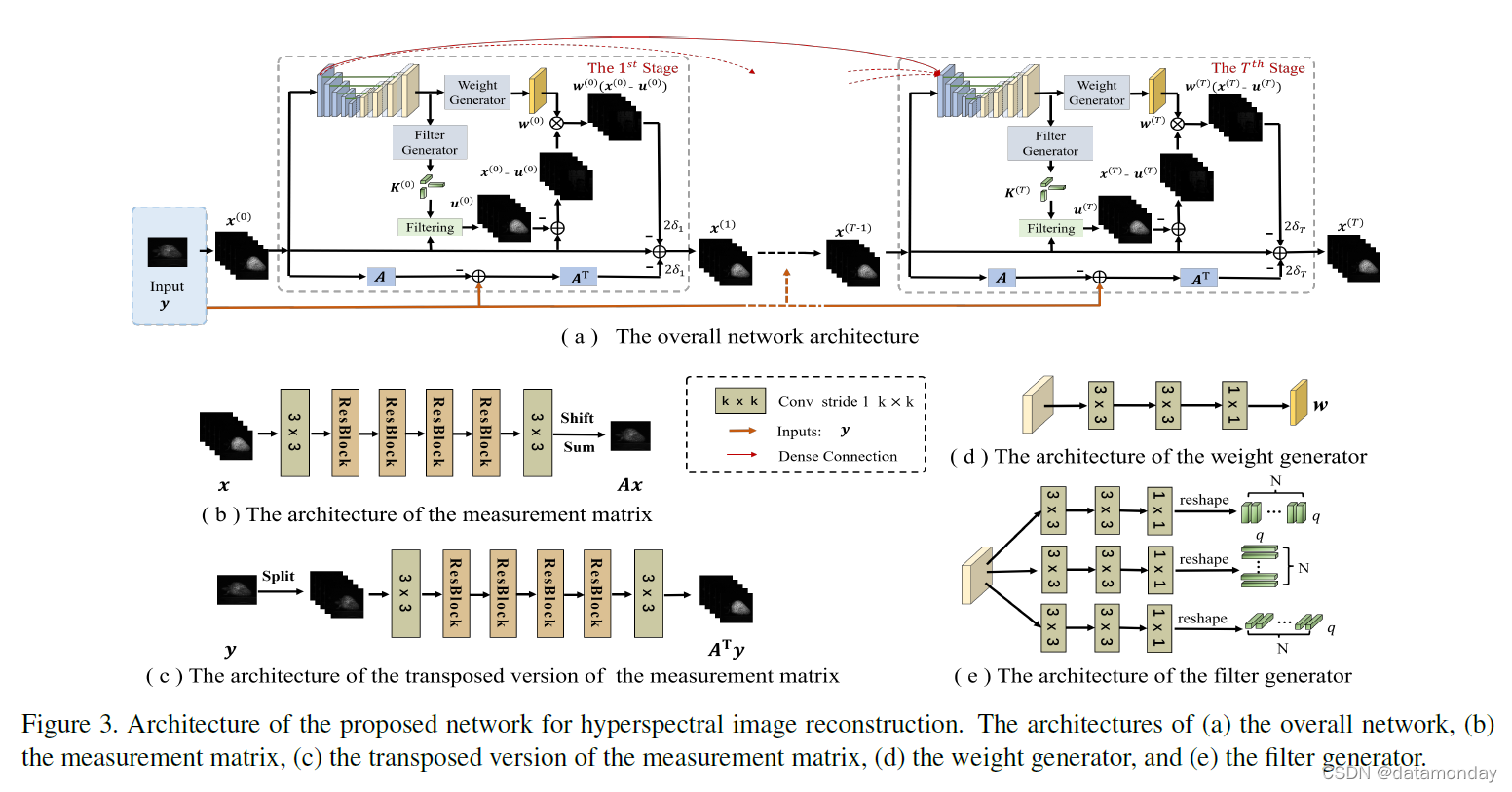
考虑到真实系统具有较大的掩码和测量空间大小(例如,[22] 的掩码和测量值分别为 660 × 660 和 660 × 714),使用显式构造的 A 和 A⊤ 进行网络训练需要大量 GPU内存和计算复杂度。为了解决这个问题,我们建议使用两个子网络来学习这两个操作。
用于学习测量矩阵 A 和 A⊤ 的模块。使用子网络学习 A 和 A⊤ 可以在小块(例如 64 × 64 或 96 × 96)上训练它们,这可以大大降低内存消耗和计算复杂度。此外,我们可以训练一个子网络来学习多个掩码,这样训练后的网络就可以在多个成像系统上很好地工作。测量矩阵 A 表示调制的混合算子,即移位和求和,可以通过两个 Conv 层和四个 ResBlocks 来实现,然后是移位和求和操作。如图 3(b) 所示,x 被输入子网络以生成调制特征图,这些特征图进一步沿光谱维度移动和求和,以生成测量值 y = Ax。每个 ResBlock [11] 由 2 个带有 ReLU 非线性函数的 Conv 层和一个跳跃连接组成。关于 A⊤,如图 3© 所示,我们首先在大小为 H × (W + L − 1) 的输入 y 上滑动一个 H × W 提取窗口,滑动步骤为一个像素,并将输入拆分为 L尺寸为 H × W 的通道图像。然后将分割的子图像送入两个 Conv 层和四个 ResBlock 以生成估计值 A⊤y。
用于估计正则化参数 w 的模块。如图 3 (a) 所示,我们提出了一个由五个编码块 (EB) 和四个解码块 (DB) 组成的轻量级 U-Net,以根据当前估计 x(t) 估计权重 w(t)。每个 EB 和 DB 包含两个具有 ReLU 非线性函数的 Conv 层。在每两个相邻的 EB 之间插入步长为 2 的平均池化层以对特征图进行下采样,并在每个 DB 之前采用缩放因子为 2 的双线性插值层以提高特征图的空间分辨率。我们注意到,在我们的问题中,平均池比最大池效果更好,并且双线性插值在 DB 中起着重要作用。所有 Conv 层都使用 3 × 3 Conv 过滤器。 5 个 EB 和 4 个 DB 的输出特征的通道数分别设置为 32、64、64、128、128、128、64、64 和 32。为了缓解梯度消失问题,第一个 EB 的特征图连接到后续阶段的 U-net 的第一个 EB。最后一个 DB 的特征图被输入到包含 2 个 3 × 3 Conv 层的权重生成器中,以生成权重 w,如图 3 (d) 所示。在第四阶段估计的两个 HSI 的一些权重图 w 在图 4 中可视化(通过归一化)。从图 4 中,我们可以看到 w 在空间上变化并且与图像边缘和纹理一致。在这个学习良好的 w 的帮助下,所提出的方法将关注边缘和纹理。

用于估计局部均值 u 的模块。我们根据等式估计 GSM 模型的均值。 (14)。为了估计空间变化的 3D 过滤器,我们添加了一个过滤器生成器,其输入由 U-net 生成的特征图,如图 3(a) 所示。估计空间自适应 3D 滤波器在适应局部 HSI 边缘和纹理结构方面具有优势。但是,直接生成这些 3D 滤镜会消耗大量的 GPU 内存,这是无法承受的。为了减少 GPU 内存消耗,我们建议将每个 3D 过滤器分解为三个 1D 过滤器,表示为
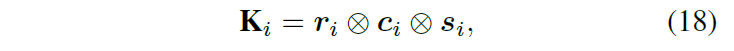
其中 K i ∈ R q × q × q K_i ∈ \mathbb{R}^{q×q×q} Ki∈Rq×q×q 表示 3D 滤波器, r i ∈ R q r_i ∈ \mathbb{R}^q ri∈Rq, c i ∈ R q c_i ∈ \mathbb{R}^q ci∈Rq 和 s i ∈ R q s_i ∈ \mathbb{R}^q si∈Rq 分别表示三个维度对应的三个 1D 滤波器,⊗ 表示张量积。这样,用 3D 滤波器 K i K_i Ki 过滤局部邻居 X i X_i Xi 就可以转化为用三个 1D 滤波器沿三个维度依次对局部邻居进行卷积。通过将每个 3D 滤波器分解为三个 1D 滤波器,我们可以将滤波器系数的数量从 N ⋅ q 3 N·q^3 N⋅q3 减少到 3 ⋅ N ⋅ q 3·N·q 3⋅N⋅q,从而显着降低 GPU 内存成本和计算复杂度。如图 3(e) 所示,滤波器生成器包含三个分支来分别学习一维滤波器。生成过滤器后,我们可以按照等式 (14) 计算 GSM 模型的均值。
4.4. Network training
我们通过端到端训练共同学习网络参数Θ。除了步长δ,每个阶段的所有网络参数都是共享的。通过最小化以下损失函数来优化所有参数
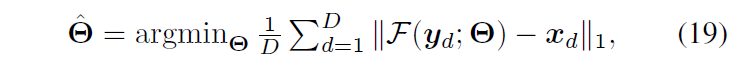
其中 D 表示训练样本的总数,F(yd; Θ) 表示给定第 d 个测量值 yd 和网络参数 Θ 的建议网络的输出,xd 是真实的 HSI。利用设置 β1 = 0.9、β2 = 0.999 和 ε = 10−8 的 ADAM 优化器 [13] 来训练所提出的网络。我们将学习率设置为 10-4。卷积层的参数由 Xavier 初始化 [10] 进行初始化。我们在 PyTorch 中实现了所提出的方法,并使用单个 Nvidia Titan XP GPU 训练网络。在损失函数中没有使用ℓ2范数,这里我们使用已被证明在保留图像边缘和纹理方面更好的ℓ1范数。
5. Simulation Results
5.1. Experimental Setup
为了验证所提出的 CASSI HSI 重建方法的有效性,我们对两个公共 HSI 数据集 CA VE [42] 和 KAIST [3] 进行了模拟。 CA VE 数据集由 32 个空间大小为 512 × 512 的 HSI 组成,具有 31 个光谱带。 KAIST 数据集有 30 个空间大小为 2704 × 3376 的 HSI,也有 31 个光谱带。与 TSA-Net [22] 类似,我们使用大小为 256 × 256 的真实掩码进行模拟。按照 TSANet [22] 中的程序,CA VE 数据集用于网络训练,并从 KAIST 数据集中提取 10 个空间大小为 256 × 256 的场景进行测试。为了与真实系统的波长一致[22],我们通过光谱插值来统一训练和测试数据的波长。因此,修改后的训练和测试数据有 28 个光谱波段,范围从 450nm 到 650nm。
在训练期间,为了模拟测量,我们首先从训练数据集中随机提取 96 × 96 × 28 个补丁作为训练标签(ground truth HSI),并从真实掩码中随机提取 96 × 96 个补丁以生成调制数据。然后调制数据以两个像素的间隔在空间上移动。将移位数据的光谱维度相加以生成大小为 96 × 150 的 2D 测量值作为网络输入。我们使用随机翻转和旋转进行数据论证。峰值信噪比 (PSNR) 和结构相似性指数 (SSIM) [39] 都用于评估 HSI 重建方法的性能。
5.2. Comparison with State-of-the-Art Methods
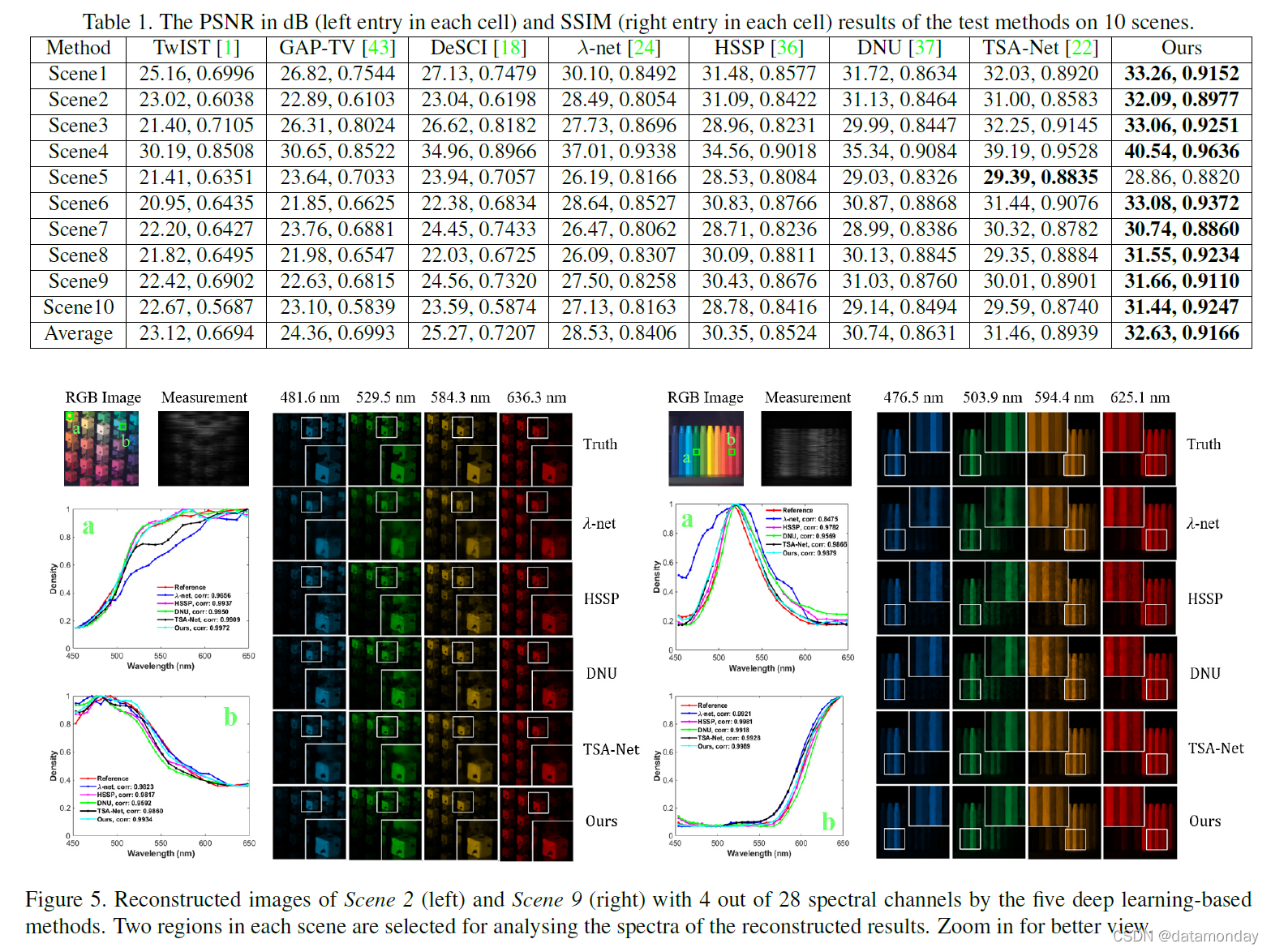
我们将提出的 HSI 重建方法与几种最先进的方法进行比较,包括三种基于模型的方法(即 TwIST [1]、GAP-TV [43] 和 DeSCI [18])和四种基于深度学习的方法(即,λnet [24]、HSSP [36]、DNU [37] 和 TSA-Net [22])。由于源代码不可用,我们自己重新实现了HSSP和DNU。对于其他竞争方法,我们使用其作者发布的源代码。为了公平比较,所有深度学习方法都在相同的训练数据集上重新训练。表 1 显示了这些测试方法在 10 个场景上的重建结果,我们可以看到基于深度学习的方法优于基于模型的方法。所提出的方法在很大程度上优于其他基于深度学习的方法。具体来说,我们的方法在平均 PSNR 和平均 SSIM 方面优于第二好的方法 TSA-Net 1.17dB 和 0.0227。与两种深度展开方法 HSSP 和 DNU 相比,所提出的方法对 HSSP [36] 和 DNU [37] 的改进平均分别为 2.28 dB 和 1.89 dB。 HSSP 和 DNU 方法还试图通过两个子网络来学习 HSI 的空间光谱相关性,而不强调图像边缘和纹理。相比之下,我们建议通过以学习的局部均值和方差为特征的空间自适应 GSM 模型来学习 HSI 的空间光谱先验。学习到的 GSM 模型在适应各种 HSI 边缘和纹理方面具有优势。图 5 绘制了通过五种基于深度学习的方法重建的 HSI 的选定帧和光谱曲线。我们可以看到,与其他方法相比,该方法重建的 HSI 具有更多的边缘细节和更少的不良视觉伪影。 10 个场景的 RGB 图像和更多的视觉对比结果显示在补充材料 (SM) 中。
5.3. Multiple Mask Results
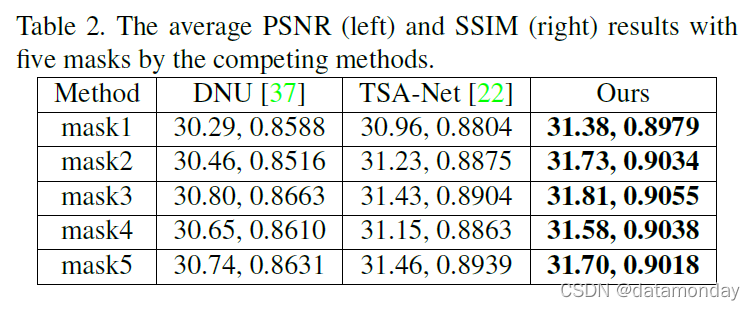
如前所述,由于 A 和 A⊤ 的学习,我们提出的网络对掩码具有鲁棒性。为了验证这一点,我们对通过应用 5 种不同掩码进行模拟的复合训练和测试数据集进行了实验。在实际捕获的掩码的四个角和中心提取了 5 个大小为 256×256 的掩码 [22]。我们只通过所提出的网络在复合训练数据集上训练了一个模型来处理多个掩码,而我们通过 DNU [37] 和 TSA-Net [22] 方法在生成的数据集上训练了与每个掩码相关的五个不同模型分别对应的掩码。表 2 显示了这些测试方法在 10 个场景上的平均 PSNR 和 SSIM 结果。我们可以看到,所提出的方法(仅在复合训练数据集上训练一次)仍然优于其他两种专门针对每个掩模训练的竞争方法,验证了学习测量矩阵 A 和 A⊤ 的优势。
5.4. Ablation Study
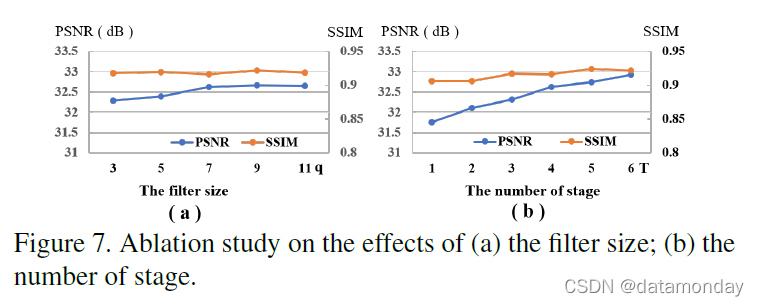
我们进行了多项消融研究,以验证所提出网络的不同模块的影响,包括滤波器大小的选择、阶段数和密集连接的使用。
图 7 (a) 显示了不同滤波器大小的结果,我们可以看到更大的滤波器大小可以提高 HSI 重建质量。在 q = 7 之后改进趋于平缓,因此我们在实现中设置 q = 7。不同阶段数的结果如图7 (b) 所示,从中我们观察到增加阶段数T会导致更好的性能。我们在实现中设置 T = 4,以在重建性能和计算复杂度之间取得良好的平衡。我们还对没有和有密集连接的提议网络进行了比较。比较表明,使用密集连接可以将 PSNR 从 30.52dB 提高到 32.63dB,将 SSIM 从 0.8802 提高到 0.9166。
6. Real Data Results
我们现在将所提出的方法应用于真实的 SDCASSI 系统 [22],该系统捕获 28 个波长范围从 450nm 到 650nm 的真实场景,并且在列维度上具有 54 像素色散。因此,真实系统捕获的测量值的空间大小为 660 × 714。与 TSA-Net [22] 类似,我们在 CAVE 数据集和 KAIST 数据集的所有场景上重新训练了所提出的方法。为了模拟真实测量,我们在训练期间注入了 11 位散粒噪声。我们将提出的方法与 TwIST [1]、GAP-TV [43]、DeSCI [18] 和 TSA-Net [22] 进行比较。竞争方法的视觉比较结果如图8所示。可以观察到,所提出的方法可以恢复更多的纹理细节并抑制更多的噪声。图 1 和图 6 显示了通过所提出的方法重建的具有 28 个光谱通道的两个真实场景(场景 3 和场景 4)的图像。 SM 中显示了更多的视觉结果。


7. Conclusions
我们提出了一种用于编码孔径快照光谱成像的可解释高光谱图像重建方法。与现有研究不同,我们的网络受到先验高斯尺度混合的启发。具体来说,所需的高光谱图像由 GSM 模型表征,然后将重建问题制定为 MAP 估计问题。我们建议通过 DCNN 学习 GSM 的尺度先验,而不是使用手动设计的先验。此外,在自回归模型的推动下,GSM 模型的均值已被估计为空间光谱相邻像素的加权平均值,并且这些滤波器系数由 DCNN 估计,旨在学习 HSI 的足够空间光谱相关性。在合成数据集和真实数据集上的大量实验结果表明,所提出的方法优于现有的状态算法。
我们提出的网络不仅限于光谱压缩成像,如 CASSI 和类似系统 [46、20],它还可以用于视频快照压缩成像系统 [28、30、29、45]。我们的工作为快照压缩成像的实际应用铺平了道路 [19, 44]。