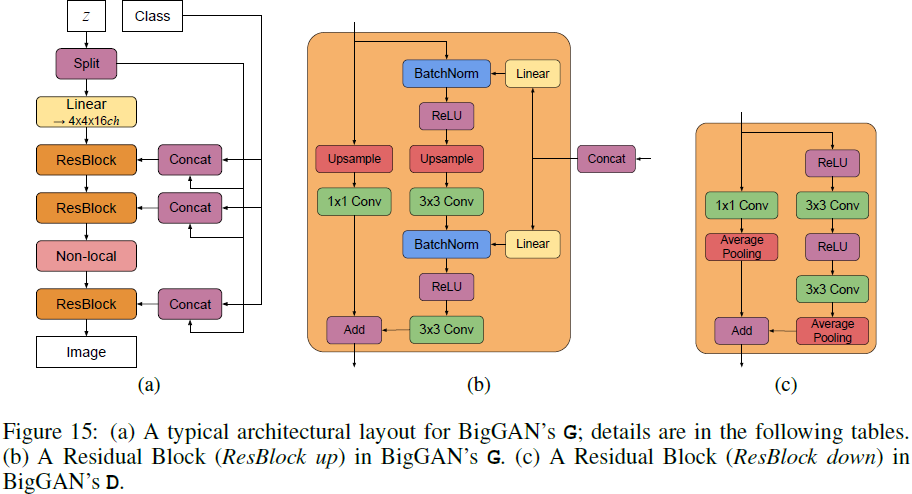
模板匹配是指在当前图像A内寻找与图像B最相似的部分,一般将图像A称为输入图像,将图像B称为模板图像。模板匹配的操作方法是将模板图像B在图像A上滑动,遍历所有像素以完成匹配。
OpenCV学习笔记(十一)
- 1. 模板匹配基础
- 2. 多模板匹配
- 2.1 获取匹配位置的集合
- 2.2 循环
- 2.3 在循环中使用函数zip()
- 2.4 调整坐标
- 2.5 标记匹配图像的位置
- 2.6 多模板匹配案例
1. 模板匹配基础
result = cv2.matchTemplate(image, templ, method[, mask ] )
- image 为原始图像,必须是8 位或者32 位的浮点型图像。
- templ 为模板图像。它的尺寸必须小于或等于原始图像,并且与原始图像具有同样的类型。
- method 为匹配方法。该参数通过TemplateMatchModes 实现,有6种可能的值,如表所示。

- mask 为模板图像掩模。它必须和模板图像templ 具有相同的类型和大小。通常情况下该值使用默认值即可。当前,该参数仅支持TM_SQDIFF 和TM_CCORR_NORMED 两个值。
- result 是由每个位置的比较结果组合所构成的一个结果
集,类型是单通道32 位浮点型。如果输入图像(原始图像)尺寸是W * H,模板的尺寸是w * h,则返回值的大小为(W-w+1)*(H-h+1)。
如下图所示,结果result 的大小满足(W-w+1)*(H-h+1),在下图中就是(10-2+1)×(10-2+1),即9×9。也就是说,模板图像要在输入图像内总计比较9×9 = 81 次,这些比较结果将构成一个9×9 大小的二维数组。
这里需要注意的是,函数cv2.matchTemplate()通过参数method来决定使用不同的查找方法。对于不同的查找方法,返回值result 具有不同的含义。例如:
- method 的值为cv2.TM_SQDIFF 和cv2.TM_SQDIFF_NORMED 时,result 值为0 表示匹配度最好,值越大,表示匹配度越差。
- method 的值为cv2.TM_CCORR、cv2.TM_CCORR_NORMED、cv2.TM_CCOEFF 和cv2.TM_CCOEFF_NORMED 时,result 的值越小表示匹配度越差,值越大表示匹配度越好。
查找最值(极值)与最值所在的位置,可以使用cv2.minMaxLoc()函数实现。该函数语法格式如下:
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc( src [, mask] )
- src 为单通道数组。
- minVal 为返回的最小值,如果没有最小值,则可以是NULL(空值)。
- maxVal 为返回的最大值,如果没有最小值,则可以是NULL。
- minLoc 为最大值的位置,如果没有最大值,则可以是NULL。
- maxLoc 为最大值的位置,如果没有最大值,则可以是NULL。
- mask 为用来选取掩模的子集,可选项。
综上所述,函数cv2.matchTemplate()返回值中的最值位置就是模板匹配的位置,可以理解为模板匹配的评分,最值越大/越小(取决于method),说明这个模板跟原图匹配的越好。当然,选用表中的不同参数值,匹配位置可能位于最大值所在的位置也可能位于最小值所在的位置。通过函数cv2.minMaxLoc()来查找函数cv2.matchTemplate()返回值中的最值位置,就可以找到最佳模板匹配的位置。
例如,当method 的值为cv2.TM_SQDIFF 和cv2.TM_SQDIFF_NORMED 时,0 表示最佳匹配,值越大,则表示匹配效果越差。因此,在使用这两种方法时,要寻找最小值所在的位置作为最佳匹配。如下语句能够找到cv2.matchTemplate()函数返回值中最小值的位置:
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(matchTemplate 函数的返回值)
topLeft = minLoc # 查找最小值所在的位置
以 topLeft 点为模板匹配位置的左上角坐标,结合模板图像的宽度w 和高度h 可以确定匹配位置的右下角坐标,代码如下所示:
bottomRight = (topLeft[0] + w, topLeft[1] + h) #w 和h 是模板图像的宽度和高度
通过上述方式,我们确定了模板匹配的矩形对角坐标位置,接下来可以借助函数cv2.rectangle()将该位置用白色标记出来。函数cv2.rectangle 的语法格式为:
Img = cv.rectangle( img, pt1, pt2, color[, thickness])
- img 表示要标记的目标图像。
- pt1 是矩形的顶点。
- pt2 是pt1 的对角顶点。
- color 是要绘制矩形的颜色或灰度级(灰度图像)。
- thickness 是矩形边线的宽度。
因此,使用的标记语句为:
cv2.rectangle(img,topLeft, bottomRight, 255, 2)
#使用函数cv2.matchTemplate()进行模板匹配。要求参数method 的值设置为cv2.TM_SQDIFF,显示函数的返回结果及匹配结果。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('lena512g.bmp',0)
template = cv2.imread('temp.bmp',0)
th, tw = template.shape[::]
rv = cv2.matchTemplate(img,template,cv2.TM_SQDIFF)
minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(rv)
topLeft = minLoc
bottomRight = (topLeft[0] + tw, topLeft[1] + th)
cv2.rectangle(img,topLeft, bottomRight, 255, 2)
plt.subplot(121),plt.imshow(rv,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.show()
模板和原图如下:

运行上述代码,得到如图所示结果:

这里需要注意,在计算模板图像的宽度时,使用的语句为:
th, tw = template.shape[::]
返回值中的th 是模板图像的高度,tw 是模板图像的宽度。在OpenCV 官网的示例中,使用的语句形式为:
tw, th = template.shape[::-1]
该语句返回的也是模板图像的宽度和高度,只不过语句template.shape[::-1]将宽度和高度的顺序进行了调换。
2. 多模板匹配
在前面的例子中,我们在输入图像lena 中搜索其眼部子图,该子图在整个输入图像内仅出现了一次。但是,有些情况下,要搜索的模板图像很可能在输入图像内出现了多次,这时就需要找出多个匹配结果。而函数cv2.minMaxLoc()仅仅能够找出最值,无法给出所有匹配区域的位置信息。所以,要想匹配多个结果,使用函数cv2.minMaxLoc()是无法实现的,需要利用阈值进行处理。
下面分步骤介绍如何获取多模板匹配的结果。
2.1 获取匹配位置的集合
函数 where()能够获取模板匹配位置的集合。对于不同的输入,其返回的值是不同的。
- 当输入(参数)是一维数组时,返回值是一维索引,只有一组索引数组。
- 当输入是二维数组时,返回的是匹配值的位置索引,因此会有两组索引数组表示返回值的位置。
loc = np.where( res >= threshold)
- res 是函数cv2.matchTemplate()进行模板匹配后的返回值。
- threshold 是预设的阈值。
- loc 是满足“res >= threshold”的像素点的索引集合。二维数组返回值loc中为两个元素,分别表示匹配值的行索引和列索引。
#一维数组
import numpy as np
a=np.array([3,6,8,1,2,88])
b=np.where(a>5)
print(b)该段代码返回的结果为:
(array([1, 2, 5], dtype=int64),)
#二维数组
import numpy as np
am=np.array([[3,6,8,77,66],[1,2,88,3,98],[11,2,67,5,2]])
b=np.where(am>5)
print(b)该段代码返回的结果为:
(array([0, 0, 0, 0, 1, 1, 2, 2], dtype=int64),
array([1, 2, 3, 4, 2, 4, 0, 2], dtype=int64))
2.2 循环
在获取匹配值的索引集合后,可以采用如下语句遍历所有匹配的位置,对这些位置做标记:
for i in 匹配位置集合:标记匹配位置。
2.3 在循环中使用函数zip()
函数 zip()用可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
#例如
import numpy as np
am=np.array([[3,6,8,77,66],[1,2,88,3,98],[11,2,67,5,2]])
print(am)
b=np.where(am>5)
for i in zip(*b):print(i)上述代码的输出结果为:
[[ 3 6 8 77 66]
[ 1 2 88 3 98]
[11 2 67 5 2]]
(0, 1)
(0, 2)
(0, 3)
(0, 4)
(1, 2)
(1, 4)
(2, 0)
(2, 2)
2.4 调整坐标
函 数 numpy.where() 可以获取满足条件的模板匹配位置集合, 然后可以使用函数cv2.rectangle()在上述匹配位置绘制矩形来标注匹配位置。
使用函数numpy.where()在函数cv2.matchTemplate()的输出值中查找指定值,得到的形式为“(行号,列号)”的位置索引。但是,函数cv2.rectangle()中用于指定顶点的参数所使用的是形
式为“(列号,行号)”的位置索引。所以,在使用函数cv2.rectangle()绘制矩形前,要先将函数numpy.where()得到的位置索引做“行列互换”。可以使用如下语句实现loc 内行列位置的互换:
loc[::-1]
#如下语句将loc 内的两个元素交换位置:
import numpy as np
loc = ([1,2,3,4],[11,12,13,14])
print(loc)
print(loc[::-1])其中,语句print(loc)所对应的输出为:
([1, 2, 3, 4], [11, 12, 13, 14])
语句 print(loc[::-1])所对应的输出为:
([11, 12, 13, 14], [1, 2, 3, 4])
2.5 标记匹配图像的位置
函数 cv2.rectangle()可以标记匹配图像的具体位置,分别指定要标记的原始图像、对角顶点、颜色、矩形边线宽度即可。
关于矩形的对角顶点:
- 其中的一个对角顶点A可以通过for 循环语句从确定的满足条件的“匹配位置集合”内获取。
- 另外一个对角顶点,可以通过顶点A的位置与模板的宽(w)和高(h)进行运算得到。
因此,标记各个匹配位置的语句为:
for i in 匹配位置集合:cv2.rectangle(输入图像,i, (i[0] + w, i[1] + h), 255, 2)
2.6 多模板匹配案例
#使用模板匹配方式,标记在输入图像内与模板图像匹配的多个子图像。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('lena4.bmp',0)
template = cv2.imread('lena4Temp.bmp',0)
w, h = template.shape[::-1]
res = cv2.matchTemplate(img,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.9
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):cv2.rectangle(img, pt, (pt[0] + w, pt[1] + h), 255, 1)
plt.imshow(img,cmap = 'gray')
plt.xticks([]), plt.yticks([])
模板及原始图像如下所示:

运行上述代码,得到如图所示结果:

大家可能已经注意到了,本来在函数cv2.rectangle()中设置的边界宽度为1,但实际上标记出来的宽度远远大于1。这是因为在当前的区域内,存在多个大于当前指定阈值(0.9)的情况,所以将它们都做了标记。这样,多个宽度为1 的矩形就合在了一起,显得边界比较粗。读者可以尝试修改阈值,调整宽度,观察不同的演示效果。