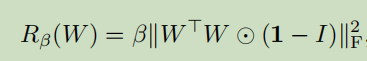作为学力不足、码力有余的深度学习业余玩家,笔者在工作中忙里偷闲,借助AI Studio的免费GPU继续自己对于生成对抗网络落地应用的相关研究。尽管深度学习已在工业生成中广泛应用,但作为研究重头的视觉效果极佳的GAN的图像生成,却在应用中遇到了瓶颈。适逢AI Studio组织GAN相关的复现课程,笔者投入其中获取到了BigGAN模型结构的搭建方法,在膜拜于BigGAN强大的视觉表现效果时,开始踏上将国外独立研究者预训练的动漫BigGAN转换到PaddlePaddle中进行更深入探索的道路。因为PaddlePaddle的动态图更便于在模型各个推理位置进行调试和修改。
当然,使用预训练模型对于平民玩家也是不得已而为之,效果这么好的模型,要训练出来也不是一件轻松的事,所以我们只好在已经训练好的模型上玩耍了。本次实验使用的BigGAN模型与常规的BigGAN并无大的不同,但是研究者通过添加各种训练的trick让模型能生成绝妙的动漫图片,引发了笔者对BigGAN落地的可能性的思考,于是便有了这一篇文章的写就。
本项目更多的实验过程和结果可以到以下项目玩耍查看:
https://aistudio.baidu.com/aistudio/projectdetail/1141070
BigGAN的简介
GAN模型因为生成效果极佳,从而自2014年以来该领域技术发展非常快。但是直到BigGAN出来前,实现从ImageNet之类的复杂数据集中生成高分辨率、多样化的图像一直是一个难以实现的目标。于是,研究员们在土豪Nvidia的大量资源供给下,以超多GPU、超大批次的方式训练GAN模型,研究出GAN训练不稳定的原因 。最终研究员们将正交正则化和“截断技巧”两种解决方案应用其中,并宣告完整版本BigGAN的诞生。不过在笔者看来,“大规模”对实验取得成功做的贡献要大得多。
BigGAN的接棒者
1. 同一团队的后续杰作
在BigGAN之后,出现了BigBiGAN,是研究团队先前的研究BiGAN同BigGAN的结合。BigBiGAN,相较于BigGAN,增加了Bi(双向),让鉴别器判断编码器产生的潜向量以及随机潜向量生成的图像是否都为真。不过这项研究并未引起如BigGAN一般的轰动,而BigGAN的加强版BigGANDeep通过将残差层内含的卷积层增加,反而更能引起研究者兴趣些。
2. 可对比的其它科研相关成果
如果将BigGAN看作是“按类生成”模型中的的霸主,那StyleGAN及其二代StyleGAN2便可谓是风格的混合与解耦相关的生成模型中的强者,最近爆火的人像迪士尼卡通化的原理便是基于此。不过相较于BigGAN,这两个模型在空间变换相当复杂的多图像中表现贫弱。或许,将StyleGAN的style潜向量解耦层嵌入BigGAN可以得到兼具二者优点的模型。
BigGAN的原理
简单思路
BigGAN的模型基线是Self Attention GAN,其本质不是算法的提升而是算力的提升,模型本身原理与Self Attention GAN是差不多的。研究者通过以下手段来逐渐实现BigGAN的绝佳效果:
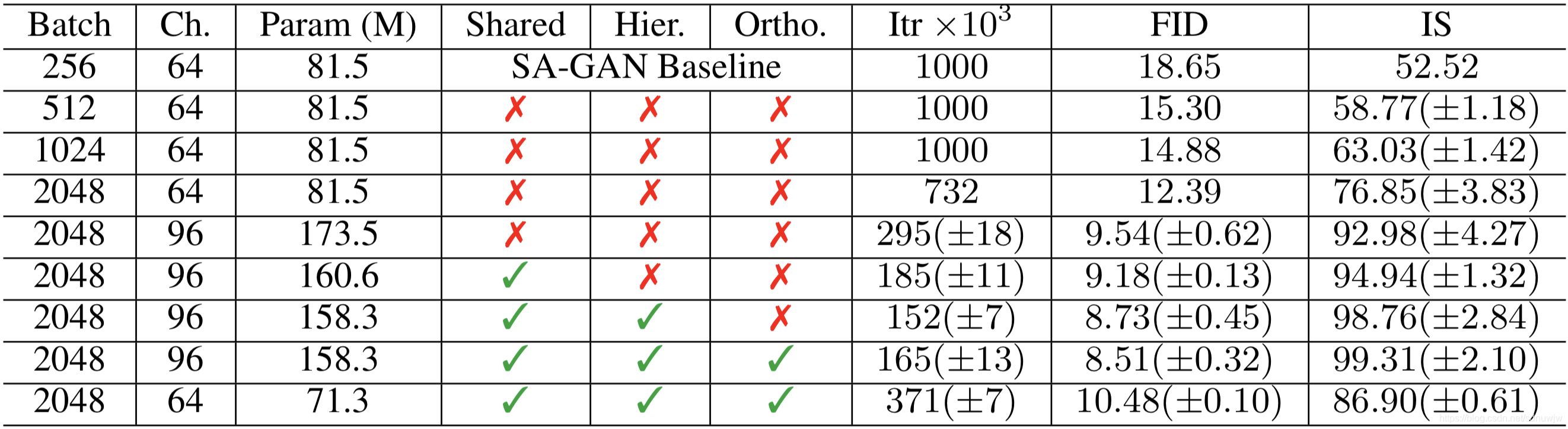
1. 首先增加基线模型(Self Attention GAN)的batch_size,做出这一更改后,研究者立即就在训练过程中发现更好的生成结果。只是简单地将批量大小增加8倍,竟能使现有技术的Inception Score提高了46%。研究者推测这是因为每个批次覆盖了更多的模式,能为两个网络提供更好的梯度。这种缩放虽然能够在更少的迭代中取得更好的效果,但不可忽略的副作用是使得训练变得不稳定而容易完全崩溃。
2. 将每层中的宽度(通道数)增加50%,即大约两倍于两个模型中的参数数量。这一改变使得Inception Score进一步提高21%。研究者推断这是由于模型的容量需要随着数据集的复杂性而增加。不过,加倍深度似乎不会对使用ImageNet作为数据集的模型产生相同的影响,反而会降低性能。
放缩
当batch_size增大到原来8倍的时候,生成性能上的Inception Score提高了 46%。原论文中推测这可能是每个batch覆盖更多模式(即更多图像变化的可能)的结果,为生成和判别两个网络提供更好的梯度。增大batch_size还会带来在更少的时间训练出更好性能的模型,但增大batch_size同时会使得模型在训练上稳定性下降。
除了以上方法,它们的卷积网络用的通道数是还是原有方法的2-4倍,对复杂数据增加了模型的容量,增加宽度,乃至后面提出的BigGAN-Deep 增加了深度,通过残差+瓶颈网络,进一步提高了效果,更快的收敛。不过副作用是训练不稳定,容易崩。与此同时在网络中,使用了一层自注意力,每层都是用SN谱归一化,这同原来的Self Attention GAN并无太大区别。
分层潜在空间
模型的输入,也就是潜向量z(通过正态分布采样获得),研究者们不仅在底层输入潜向量z的一部分,还在中间的每个残差块都输入z的不同部分。
以生成128x128的 图片为例,每个残差块对应一个z块,初始的全连接输入也需要一个。总共需要6个,若整个z的维度是120, 也就是每一部分输入的部分z的维度是20。
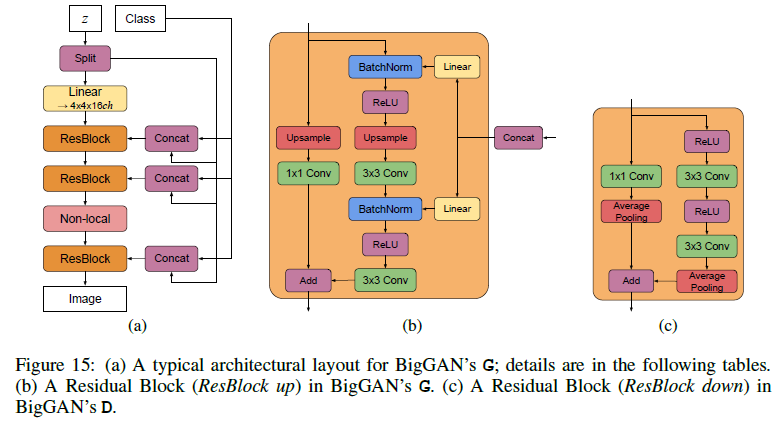
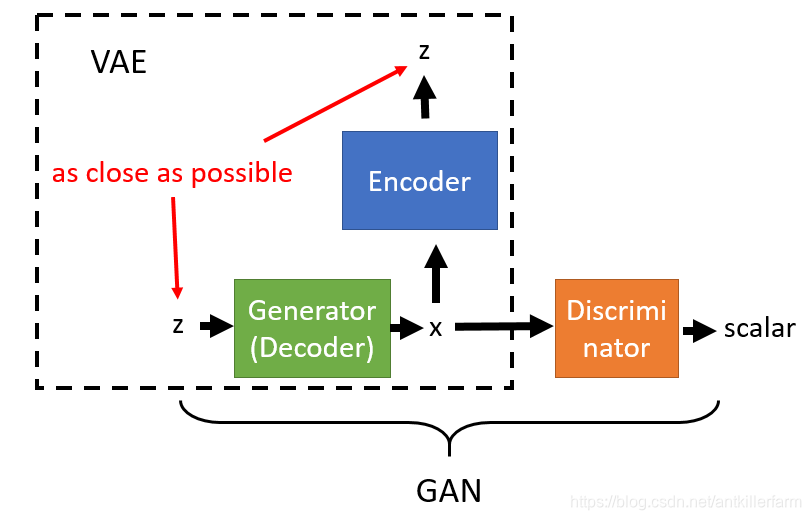
正如图所示,BigGAN在先验分布z的嵌入上做了改进,普遍的GAN都是将z作为输入直接嵌入生成网络,而 BigGAN 将潜向量z送到G的多个层而不仅仅是初始层,这实际降低了内存占用和训练成本,并使得训练更加可控。
如下图,将潜向量z分成多块,然后和条件标签c连接后一起送入到生成网络的各个层中,对于生成网络的每一个残差块又可以进一步展开为右图的结构。可以看到潜向量z的块和条件标签c在残差块下是通过合并操作后送入批次归一化层,其中这种嵌入是共享嵌入,线性投影到每个层的偏置和权重上。
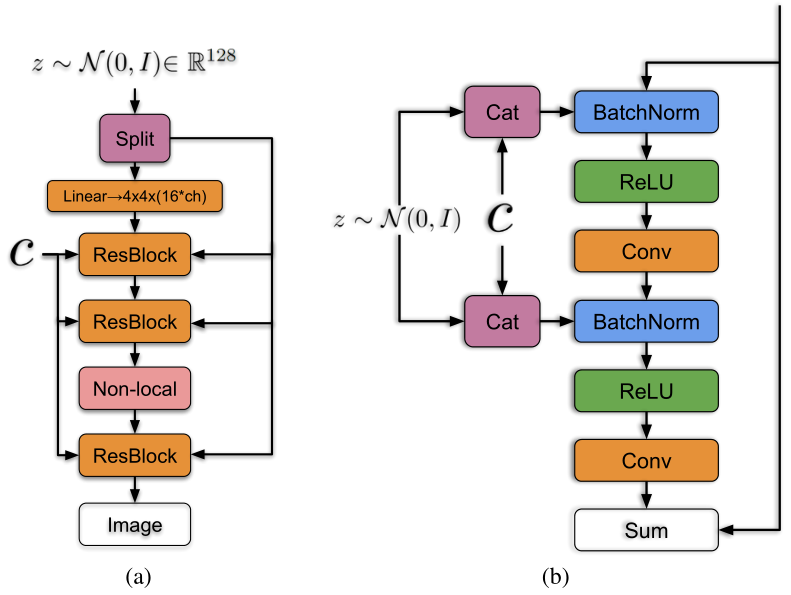
而这种条件嵌入连带分类嵌入的特殊批次归一化,使得生成图像的类别可控。
截断技巧
虽然训练的时候用正态分布采样的潜向量z作为输入,但是研究者在测试采样的时候,通过调整幅度高于所选阈值的值落入阈值内来截断 z向量,使得单个样品质量的改善。代价是整体样品品种的减少。如下图截断强度增加,生成的狗狗也愈发相似,右侧是将截断应用于模型后产生饱和度伪影而导致的较差结果。

一般情况下,普通的截断只能有16%的优秀图像生成的成功率,否则就会出现上述的伪影。研究者通过引入正交正则化,使得截断约束更为松弛,成功率也达到了60%。该正则化公式如下:
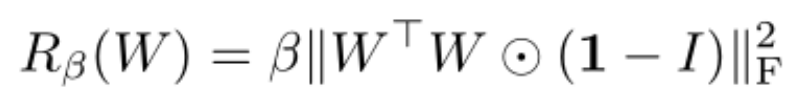
笔者学力不足,对这一块倒是没有过深追究,因为仅仅是不含截断的BigGAN生成的动漫图像就已经很惊艳众人。
累加批次归一化
动漫版BigGAN使用的批次归一化(BatchNorm)和常见的稍微有一些不一样,称为累加批次归一化。在训练的过程中,这种归一化并不会通过滑动平均的方式逐渐存储均值和方差,而是每一批次都重新计算均值和方差。这种方式之所以可行的原因是,动漫版BigGAN训练的每个batch_size实在是太大了,大到一个批次里计算出来的均值和方差与实际整个数据集的均值和方差偏差不会太大。不过这也是训练过程中,在训练结束后需要再多此统计均值和方差将这两个值固定下来,使得小批次也能正常使用这个训练好的模型。这一点被动漫版BigGAN的研究者给一时疏忽掉了,以至于插值的结果非常糟糕。笔者发现了这个问题,并向他们提出,有幸帮助他们解决了一个大麻烦。
在飞桨上玩转模型
1. 从其它框架上将模型迁移到飞桨
在模型的搭建之初,笔者参考了其他研究者用PyTorch复现的BigGAN的模型架构,结果是万万没想到啊,训练出这个精妙的动漫生成模型的大神研究者,用的BigGAN模型与平时所见还有些迥异,甚至一些算子都不一样,便令人有些头疼。谁不想要一个能一键生成、轻松玩耍的模型呢?
可惜它不是。笔者只好开始了漫漫的算子对齐路。这个部分并不算是技术含量很高的地方,更加偏向于重复劳动。因为原模型是其它框架的静态图模型实现,对于笔者这个早已遁入动态图的选手来说,确实是一件劳心费力的事,好在模型的构成相对线性,没有造成太大麻烦。
在对齐算子后还要进行一番检验,需要先把权重转换为PaddlePaddle模型的权重,一般用NumPy作为二者权重转换的桥梁。通过hook手段记录中间输出,进行层层对比。也是一件相当繁琐的事情,因此还发现原模型使用的谱归一化与常见的谱归一化配置还不太一样,笔者不得不又去补了补课,重新实现了一份谱归一化的代码。当两边中间输出皆为接近0的结果时,笔者心中才松了口气。
2. 模型搭建
终于到了这一步,搭建推理玩耍用的模型,真是令人激动得搓手。为了实验时避免过多的变数,笔者将推理用的模型中使用的批次归一化(BatchNorm)和谱归一化(SpectralNorm)中本来每一次推理都会改变重新计算的值固定。
此次实验完成时使用的是PaddlePaddle 1.8.4动态图模式,不过不用担心,从1.8.4到2.0也很轻松转换的。
1、生成器的结构代码
import paddle
import paddle.fluid as fluid
from paddle.fluid import layers, dygraph as dgclass Generator(dg.Layer): # not trainabledef __init__(self, code_dim=128, n_class=1000, chn=96, blocks_with_attention="B4", resolution=512):super().__init__()def GBlock(in_channel, out_channel, n_class, z_dim, use_attention):return ResBlock(in_channel, out_channel, n_class=n_class, z_dim=z_dim, use_attention=use_attention)self.embed_y = dg.Linear(n_class, 128, bias_attr=False)self.chn = chnself.resolution = resolution self.blocks_with_attention = set(blocks_with_attention.split(",")) self.blocks_with_attention.discard('')gblock = []in_channels, out_channels = self.get_in_out_channels()self.num_split = len(in_channels) + 1z_dim = code_dim//self.num_split + 128self.noise_fc = SpectralNorm(dg.Linear(code_dim//self.num_split, 4 * 4 * in_channels[0]))self.sa_ids = [int(s.split('B')[-1]) for s in self.blocks_with_attention]for i, (nc_in, nc_out) in enumerate(zip(in_channels, out_channels)):gblock.append(GBlock(nc_in, nc_out, n_class=n_class, z_dim=z_dim, use_attention=(i+1) in self.sa_ids))self.blocks = dg.LayerList(gblock)self.output_layer_bn = BatchNorm(1 * chn, epsilon=1e-5)self.output_layer_conv = SpectralNorm(dg.Conv2D(1 * chn, 3, [3, 3], padding=1))def get_in_out_channels(self):resolution = self.resolutionif resolution == 1024:channel_multipliers = [16, 16, 8, 8, 4, 2, 1, 1, 1]elif resolution == 512:channel_multipliers = [16, 16, 8, 8, 4, 2, 1, 1]elif resolution == 256:channel_multipliers = [16, 16, 8, 8, 4, 2, 1]elif resolution == 128:channel_multipliers = [16, 16, 8, 4, 2, 1]elif resolution == 64:channel_multipliers = [16, 16, 8, 4, 2]elif resolution == 32:channel_multipliers = [4, 4, 4, 4]else:raise ValueError("Unsupported resolution: {}".format(resolution))in_channels = [self.chn * c for c in channel_multipliers[:-1]]out_channels = [self.chn * c for c in channel_multipliers[1:]]return in_channels, out_channelsdef forward(self, input, class_id, input_class_emb=False):if isinstance(input, list):codes = [input[0]]codes += [input[2*i+1:2*i+3] for i in range(len(input)//2)]else:codes = layers.split(input, self.num_split, 1)if not input_class_emb:class_emb = self.embed_y(class_id) # 128else:class_emb = class_idout = self.noise_fc(codes[0])out = layers.transpose(layers.reshape(out,(out.shape[0], 4, 4, -1)),(0, 3, 1, 2))for i, (code, gblock) in enumerate(zip(codes[1:], self.blocks)):if isinstance(input, list):condition = [layers.concat([c, class_emb], 1) for c in code]else:condition = layers.concat([code, class_emb], 1)out = gblock(out, condition)out = self.output_layer_bn(out)out = layers.relu(out)out = self.output_layer_conv(out)return (layers.tanh(out) + 1) / 2笔者修改了模型前向生成过程中传入潜向量的手段,使得模型能够控制更多层次的生成。
2、插值函数
import os
import numpy as np
import paddle.fluid as fluid
from paddle.fluid import layers, dygraph as dg
from PIL import Image
from tqdm import tqdm
from .model import model_cachefrom sys import stdoutclass RandomState(object):rng = None
rds = RandomStatedef std_gen(batch_size=8, seed=None):with dg.no_grad():model_cache.train_mode = Falsemodel_cache.initialized = Falseif seed is not None:rds.rng = np.random.RandomState(seed)elif rds.rng is None:rds.rng = np.randomG = model_cache.Gx_np = rds.rng.randn(batch_size,140).astype('float32')y_np = rds.rng.randint(0,1000,size=[batch_size]).astype('int64')x = dg.to_variable(x_np)y = dg.to_variable(y_np)y_hot = layers.one_hot(layers.unsqueeze(y,[1]), depth=1000)img_pd = G(x, y_hot)img = np.uint8(img_pd.numpy().clip(0,1)*255)imgs = []for i in range(len(img)):imgs += [Image.fromarray(img[i].transpose([1,2,0]))]return imgs在加载预训练模型后,使用std_gen函数,如:
# 运行模型的标准生成输出过程 Run Output Process of Model's Standard Generation
import numpy as np
from PIL import Image
from IPython.display import displaydef concat_imgs_bsz8(imgs):np_imgs = [np.asarray(img) for img in imgs]img1 = np.concatenate(np_imgs[:4], 1)img2 = np.concatenate(np_imgs[4:], 1)img = Image.fromarray(np.concatenate([img1, img2], 0))return img.resize([img.size[0]//2, img.size[1]//2])imgs = std_gen(8, seed=233)
for i, img in enumerate(imgs):img.save(f'data/std_seed233_{str(i).zfill(3)}.png')
display(concat_imgs_bsz8(imgs))生成如下结果:

通过改变不同的随机数种子,可以获取到更多的可能。
当时这第一次采样出现的结果就深深震撼到了笔者,虽然还有一些小小的缺陷,但是,这不就是明晃晃的绘画素材吗?如果说ArtBreeder网站上生成人身立绘是1,那动漫版的BigGAN可谓是x。不仅可以生成各角度人物,还可以生成又没的动漫自然场景和宏伟的动漫式建筑。
这可是蕴含着几百个G的动漫图片数据集的模型,使用它生成动漫图片,选择自己中意的,再进行一些修改,对于画师来讲,可不就成了极佳的生产力工具嘛。
3. 更多的可能
首先,读者们是否还记得文章开始时展示的动图。没错,那就是在多张生成图片中进行插值产生的绝妙效果。
另外,大家可还记得BigGAN的潜向量是分多层注入的,也就是说,可以固定一些层级,只改变另一些层级的潜变量,达到部分特征修改的能力。经实验,越往底层,图像的形状变化越大;越往顶层,图像的变化越发集中在颜色上。可以想象,你生成了一张蛮不错的图片,但对颜色却不太满意,此时你只需要改变输入较高层的潜向量,便可以只改变颜色而不改变图像内容。妙不可言~
总结与思考
1. BigGAN的一些缺陷
虽然说BigGAN生成的结果相当精妙绝伦,但却都过于不可控制。究其原因,是输入的潜向量维度过小,140维的潜向量还要分割为每层20维的潜向量,此时的向量便是高度抽象的。不像StyleGAN及StyleGAN2,虽然训练时每层输入是相同的512维潜向量或两个512维潜向量交叉混合输入,但实际相当于512*14(256x256)乃至更多的维度的输入,这与生成的图像flatten后的维度并没有差多少,所以易于将真实图像进行编码。如果将这种方法引入BigGAN,凭借BigGAN生成的多样性,应该能使得模型的可能性更上一层楼。
2. 应用的可能性
在文中笔者有提到,动漫BigGAN可以方便画师思考创意。不过笔者更希望一个模型能是所有人都能玩上一玩的模型,如果前面说的提升的可能能成真的话,未来或许有这样的应用:
1) 随便画几个圈代表头和四肢,模型生成指定姿态的图像,若同时输入角色人脸等特征,生成也会是同一个角色。
2) 输入线稿和多个彩色点,生成线稿上色结果。
3) 遮盖真实图像部分,模型进行补全。
BigGAN已经彰显了一种潜在可能,那么全民“会画”的时代还远吗?
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨开源框架项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddlePaddle
Gitee:
https://Gitee.com/PaddlePaddle/PaddlePaddle
·飞桨官网地址·
https://www.paddlepaddle.org.cn/