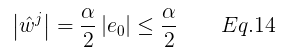一 speculative简介
在spark作业运行中,一个spark作业会构成一个DAG调度图,一个DAG又切分成多个stage,一个stage由多个Task组成,一个stage里面的不同task的执行时间可能不一样,有的task很快就执行完成了,而有的可能执行很长一段时间也没有完成。造成这种情况的原因可能是集群内机器的配置性能不同、网络波动、或者是由于数据倾斜引起的。而推测执行(speculative)就是当出现同一个stage里面有task长时间完成不了任务,spark就会在不同的executor上再启动一个task来跑这个任务,然后看哪个task先完成,就取该task的结果,并kill掉另一个task。其实对于集群内有不同性能的机器开启这个功能是比较有用的。
二 如何在spark中启动speculative
1,在spark-env.sh里设置
spark.speculation=true # 这样会作用到所有spark任务
2,在代码里通过sparkConf设置
conf.set("spark.speculation", true)
3,在用spark sql时
spark.sql("set spark.speculation = true")
4,map和reduce可以分开设置
sqlContext.sql("set mapreduce.map.speculative = true")
sqlContext.sql("set mapreduce.reduce.speculative = true")
三 speculative 运行机制
1, 监控Slow Task(Straggler Task)
spark程序运行时,会在TaskSchedulerImpl类中启动一个独立的线程池(task-scheduler-speculation)每100ms检查一次所有Task中是否有Slow Task.
2, Straggler Task衡量指标
如下图所示,在Spark调度作业中,DAGScheduler会将每个Stage中的Task封装到TaskSet,并将TaskSet交给TaskScheduler,TaskScheduler 会按顺序将Task发给Executor,并由Executor端执行这些Task。在这些Task计算过程中,Driver端如何衡量哪些Task是Straggler Task(TaskSet中所有的Task都是并行计算,在不同的Executor中计算),这个衡量过程Spark称为Speculative Task,符合Speculative Task的Task,Spark 称为Straggler Task.
相关参数
spark.speculation.interval 100:检测周期,单位毫秒
spark.speculation.quantile 0.75:完成task的百分比
spark.speculation.multiplier 1.5:时间比例
spark.speculation.interval 参数的意思是设置检测周期,默认100毫秒检测一次是否执行推测执行。
spark.speculation.quantile 参数的意思是同一个stage里面有task完成的百分比,默认为75%。
spark.speculation.multiplier 这个参数是一个时间比例。意思是当task完成了75%的时候,取完成了的task的执行时间的中位数,再乘以这个时间比例,默认为1.5。当未完成的task的执行时间超过了这个乘积值,就开启推测执行。
现存问题:
在分布式环境中导致某个Task执行缓慢的情况有很多,负载不均、程序bug、资源不均、数据倾斜等,而且这些情况在分布式任务计算环境中是常态。Speculative Task这种以空间换时间的思路对计算资源是种压榨,同时如果Speculative Task本身也变成了Slow Task会导致情况进一步恶化。