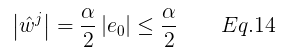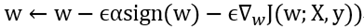提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
创新点
论文概述
方法详解
网络结构:
杂七杂八
总结
参考
创新点
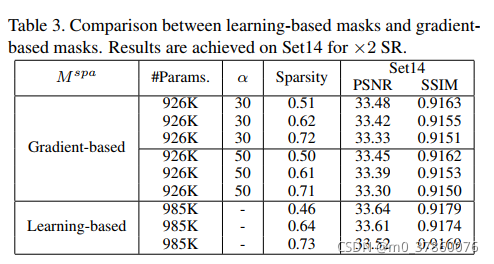
1.提出了一种稀疏卷积层,在卷积过程中使用二进制有效性掩码来指示缺失的元素。
2.大规模数据集
论文概述
1.深度补全
本篇论文之后,深度补全这个概念更加明显,之前的深度补全的问题和图像处理的任务相似,像图像超分辨方法,处理的问题类似将低分辨率的深度图优化到高分辨率
2.稀疏卷积
引入一个新的稀疏卷积层,在卷积过程中使用二进制有效性掩码来指示缺失的元素,此方法直接对输入操作,考虑了丢失数据的位置,根据像素有效性对卷积核进行加权,另外,第二个将关于像素的有效性的信息传递给网络后续层,使我们的方法能够处理大量稀疏度而不会显着降低准确性。
3.大规模数据集
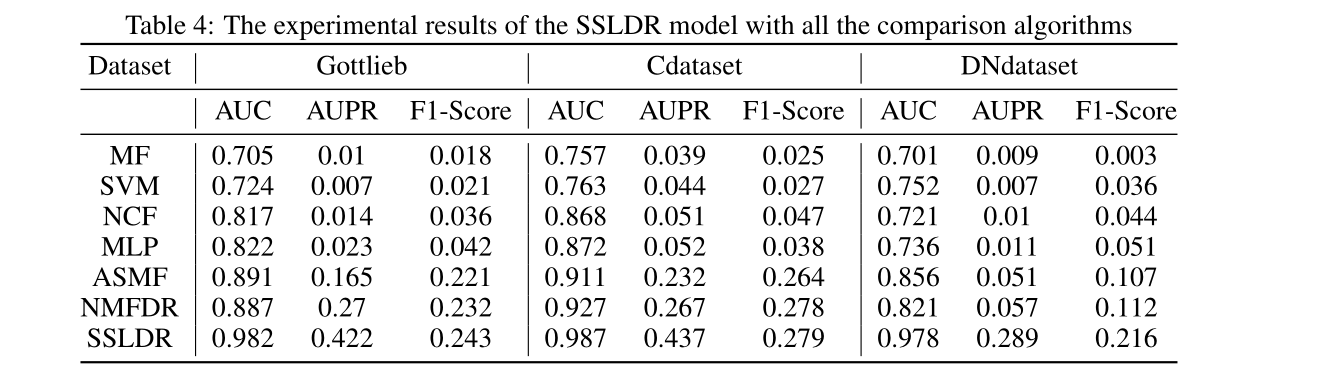
基于KITTI原始数据集创建了一个新的大规模数据集,该数据集由93k帧组成,具有半稠密的deep ground truth。结果表明,我们提出的累积和清理管道能够消除原始激光雷达扫描中的异常值,同时显著增加数据密度。减少了动态物体导致雷达扫描出现的显著误差。
4.对于数据稀疏性水平是不变的
意思是在输入数据是任何训练和测试稀疏度的情况下,性能上不会有较大差异,不像baseline在更稀疏和更密集的输入都有很大的误差
方法详解
标准卷积层:

f表示输入到输出的映射,本文是输出的深度图像素到对应深度信息的映射。核大小为2k+1,权重为w,偏差为b。如果输入包含多个特征,则xu、v和wi,j表示向量,其长度取决于输入通道的数量
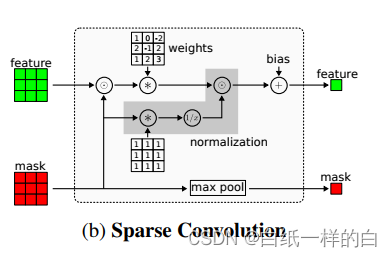
稀疏卷积:
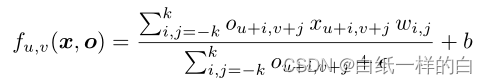
本文提出的方法,稀疏卷积计算,评估观察到的像素并归一化(直接对输入操作),设o={ou,v}表示相应的二进制变量,观察到有效值值为1,未观察到值为0,分母添加一个常数,避免分母为0,分子为添加了二进制掩码的原深度图,输入稀疏深度图是单通道,则掩码作为第二个通道添加到输入中。
由于本文方法直接对输入操作,不会像其他(例如通过插值增加输入采样)方法引入额外干扰项。
最大池化:
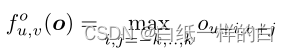
如果至少有一个观察到的变量对过滤器可见,则该值为1,否则为0。结合卷积的输出,这将作为下一个稀疏卷积层的输入
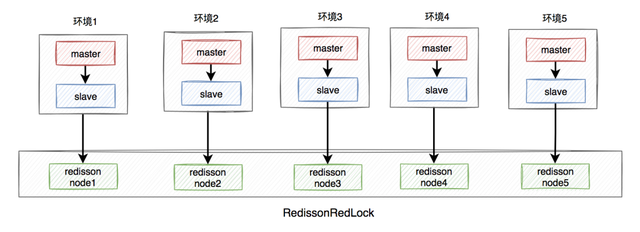
网络结构:
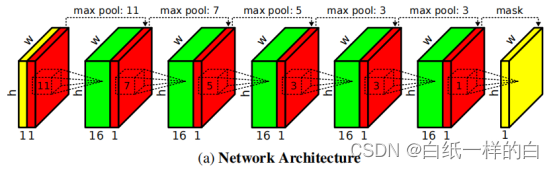
我们网络的输入是一个稀疏深度图(黄色)和一个二进制观察掩码(红色)。它通过几个稀疏卷积层(虚线),内核大小从11×11减小到3×3。
训练了具有五个卷积层的全卷积网络(FCN)的三种不同变体,这些卷积层的内核大小分别为11、7、5、3和3。每个卷积有一个16个输出通道的步长,然后是一个ReLU作为非线性激活函数。
杂七杂八
给定一个稀疏深度图,非引导方法的目标是用一个深度神经网络模型直接完成它
非引导方法通常不如RGB引导方法,存在模糊效应和目标边界失真。RGB图像提供了丰富的语义线索,这对于填充不规则形状的对象的缺失值至关重要
稀疏卷积使用二进制有效性掩码来区分有效值和缺失值,并只在有效数据之间进行卷积。有效性掩码的值由其局部邻居通过最大池化来确定。这是第一个基于深度学习的方法优于非学习方法,并显示了深度学习在任务上的潜力。此外,它还激发了许多后续的研究。
当网络的输入是稀疏和不规则的(例如,当只有10%的像素携带信息时),对于每个滤波器位置应如何定义卷积运算变得不太清楚,输入的数量和位置会发生变化。
Naıve方法有一个问题,对于未观察到的输入,一可以给他赋值编码,例如0,但这样问题是网络需要能分辨观察到的输入和无效的输入;二网络学习观察掩码和输入之间的关系。这两种变体鲁棒性不强。
总结
下面有我写博客的参考,估计不全找不到了,原作要是有幸看到的话劳烦告知
参考
(5条消息) 论文笔记_S2D.14-2014-NIPS_利用多尺度深度网络从单张图像预测深度图_惊鸿一博的博客-CSDN博客(5条消息) Normalization_gwpscut的博客-CSDN博客_normalization