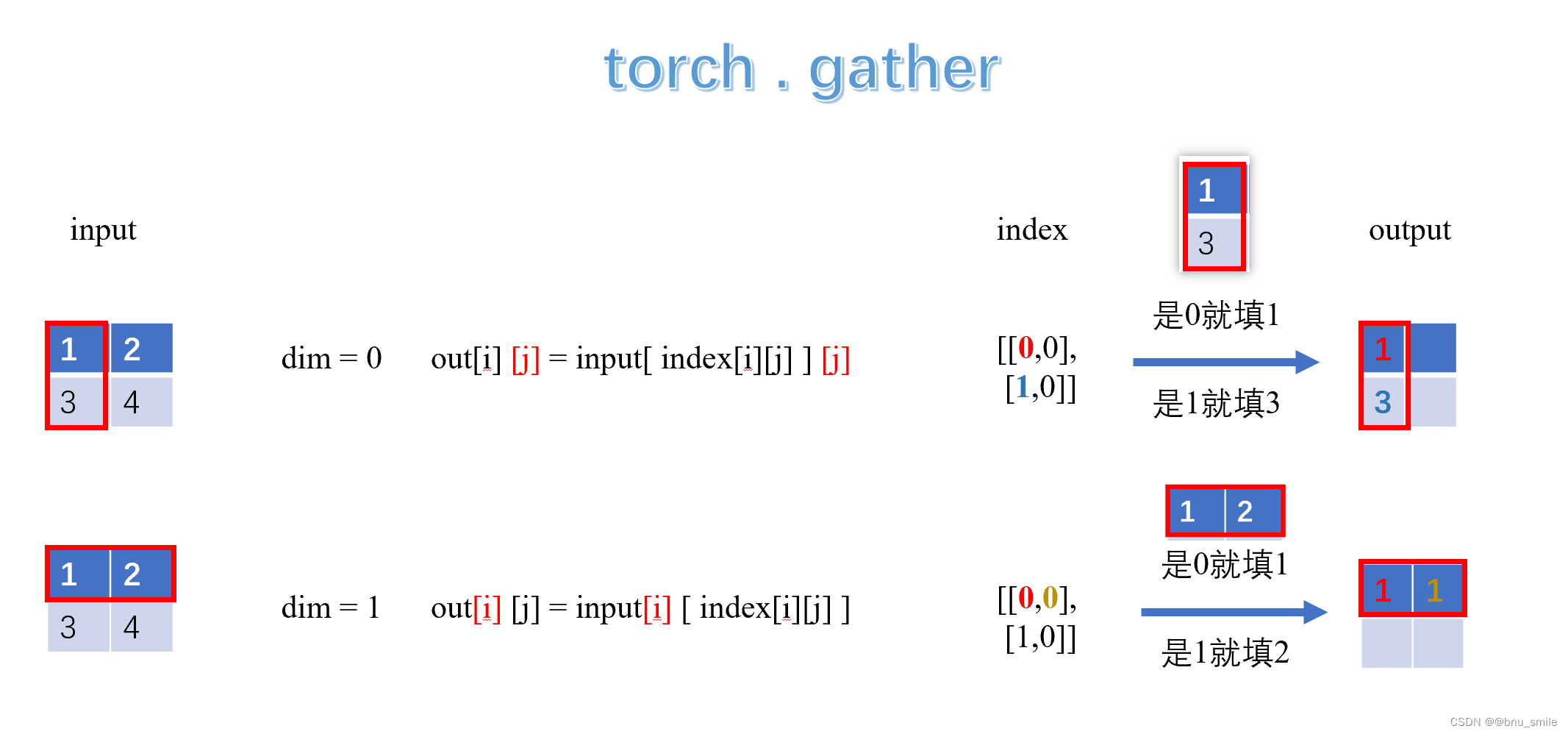
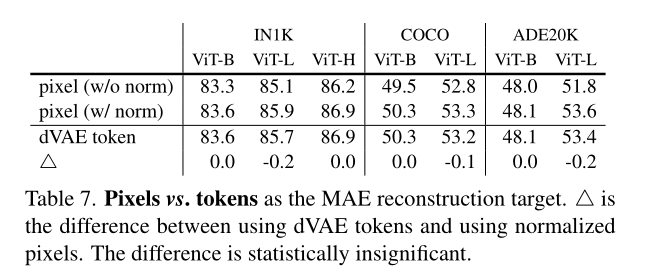
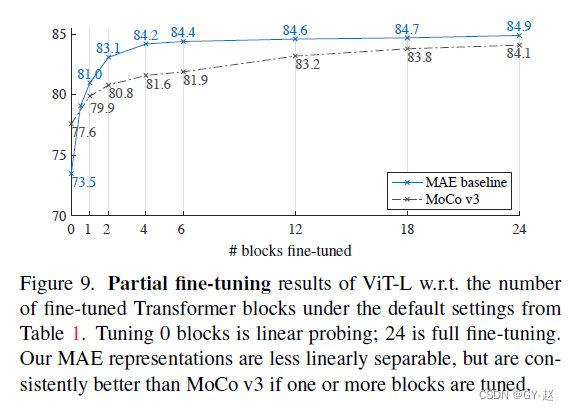
isnumeric( )还是一个很实用的函数,在算法题目里面应该会有比较大的作用。
检测字符串是否只由数字组成,如果字符串中只包括数字,就返回Ture,否则返回False。

华为的一道算法题:
读入一个字符串str,输出字符串str中的连续最长的数字串。
输入:abcd12345ed125ss123456789 输出:123456789
代码:
x = input()
curlen, curstr, maxlen, maxstr = 0, '', 0, ''for i, v in enumerate(x):if v.isnumeric():curlen += 1curstr += vif curlen > maxlen:maxlen = curlenmaxstr = curstrelse:curlen = 0curstr = ''
print(maxstr)