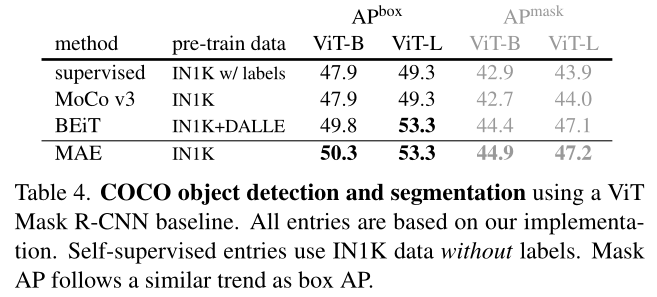
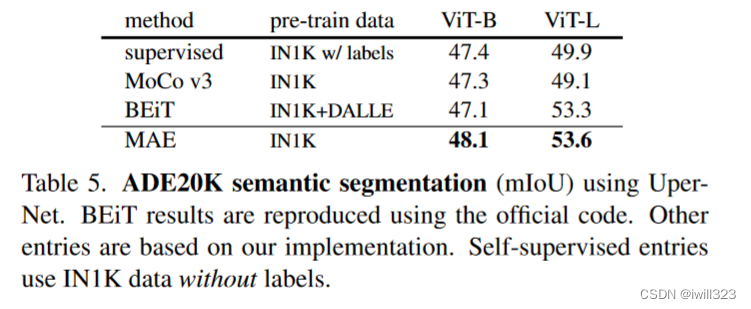
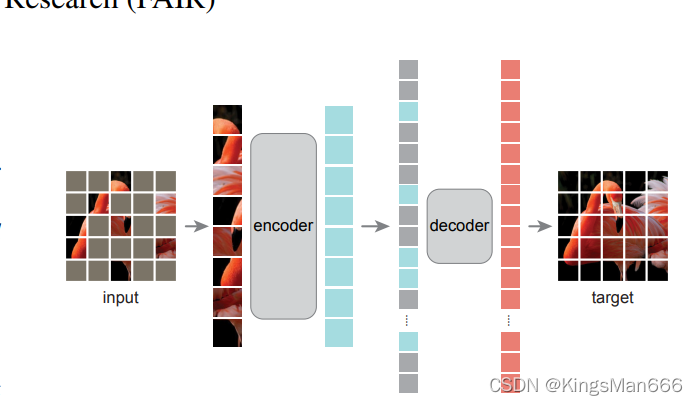
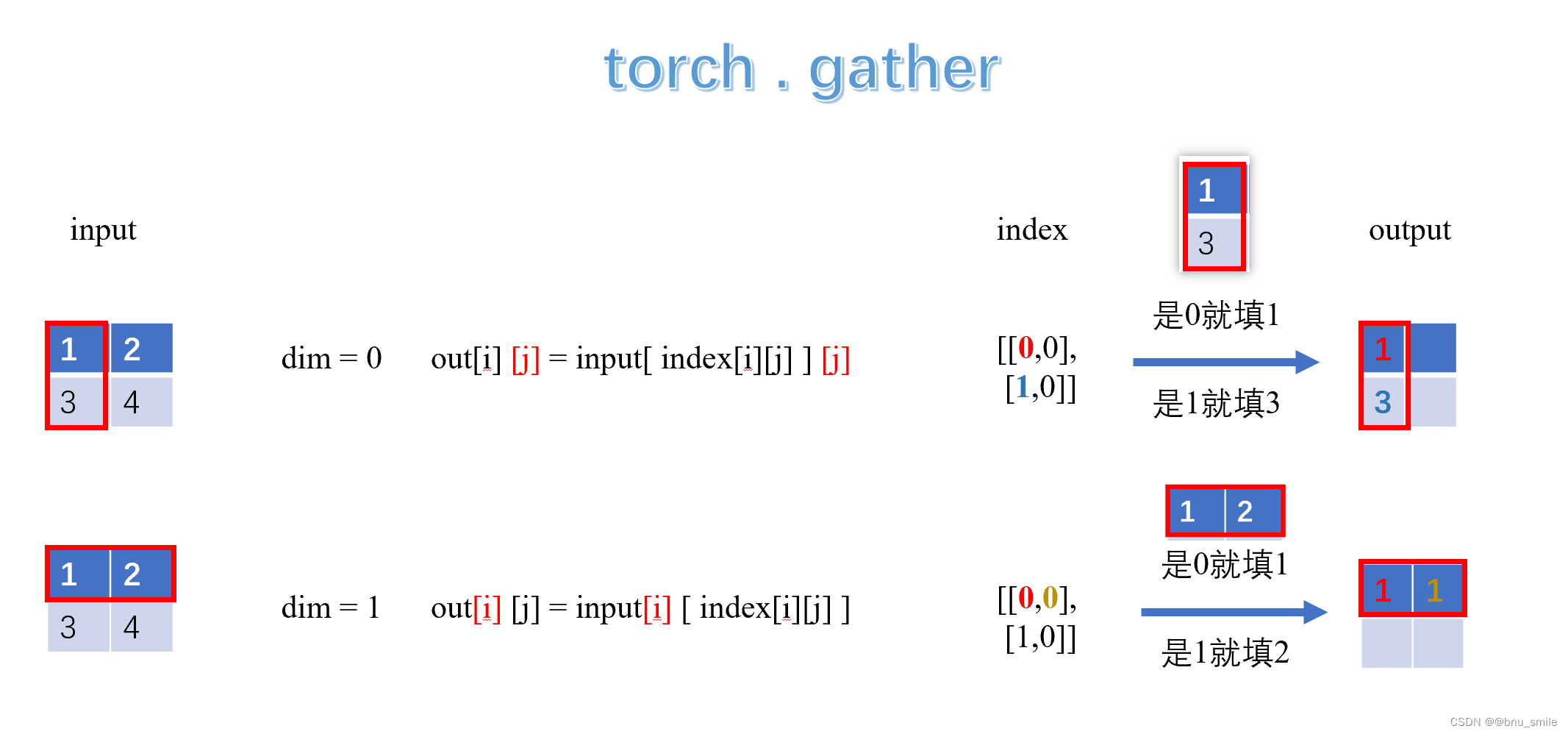
前言
分类问题的评价指标是准确率,那么回归算法的评价指标就是MSE,RMSE,MAE、R-Squared。下面一一介绍
均方误差(MSE)
MSE (Mean Squared Error)叫做均方误差。看公式
image.png
这里的y是测试集上的。
用 真实值-预测值 然后平方之后求和平均。
猛着看一下这个公式是不是觉得眼熟,这不就是线性回归的损失函数嘛!!! 对,在线性回归的时候我们的目的就是让这个损失函数最小。那么模型做出来了,我们把损失函数丢到测试集上去看看损失值不就好了嘛。简单直观暴力!
均方根误差(RMSE)
RMSE(Root Mean Squard Error)均方根误差。
image.png
这不就是MSE开个根号么。有意义么?其实实质是一样的。只不过用于数据更好的描述。
例如:要做房价预测,每平方是万元(真贵),我们预测结果也是万元。那么差值的平方单位应该是 千万级别的。那我们不太好描述自己做的模型效果。怎么说呢?我们的模型误差是 多少千万?。。。。。。于是干脆就开个根号就好了。我们误差的结果就跟我们数据是一个级别的可,在描述模型的时候就说,我们模型的误差是多少万元。
MAE
MAE(平均绝对误差)