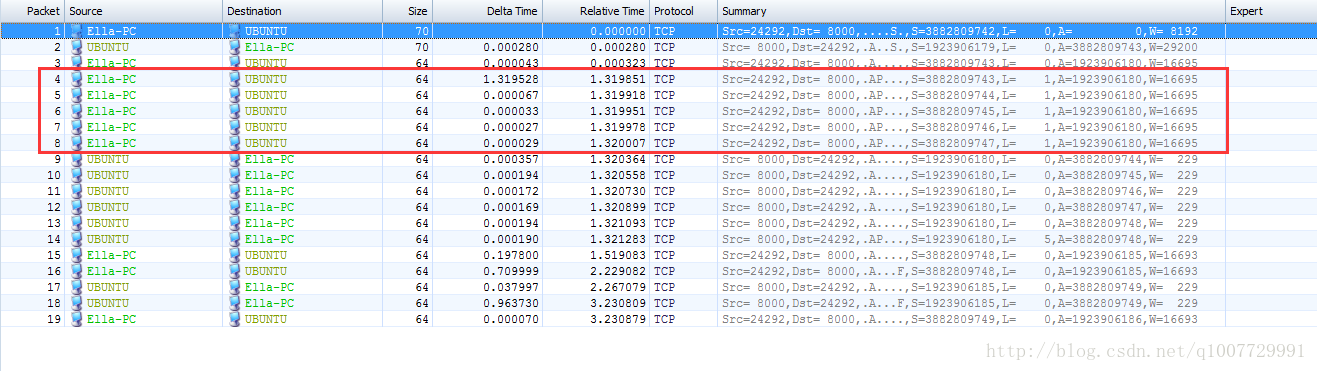
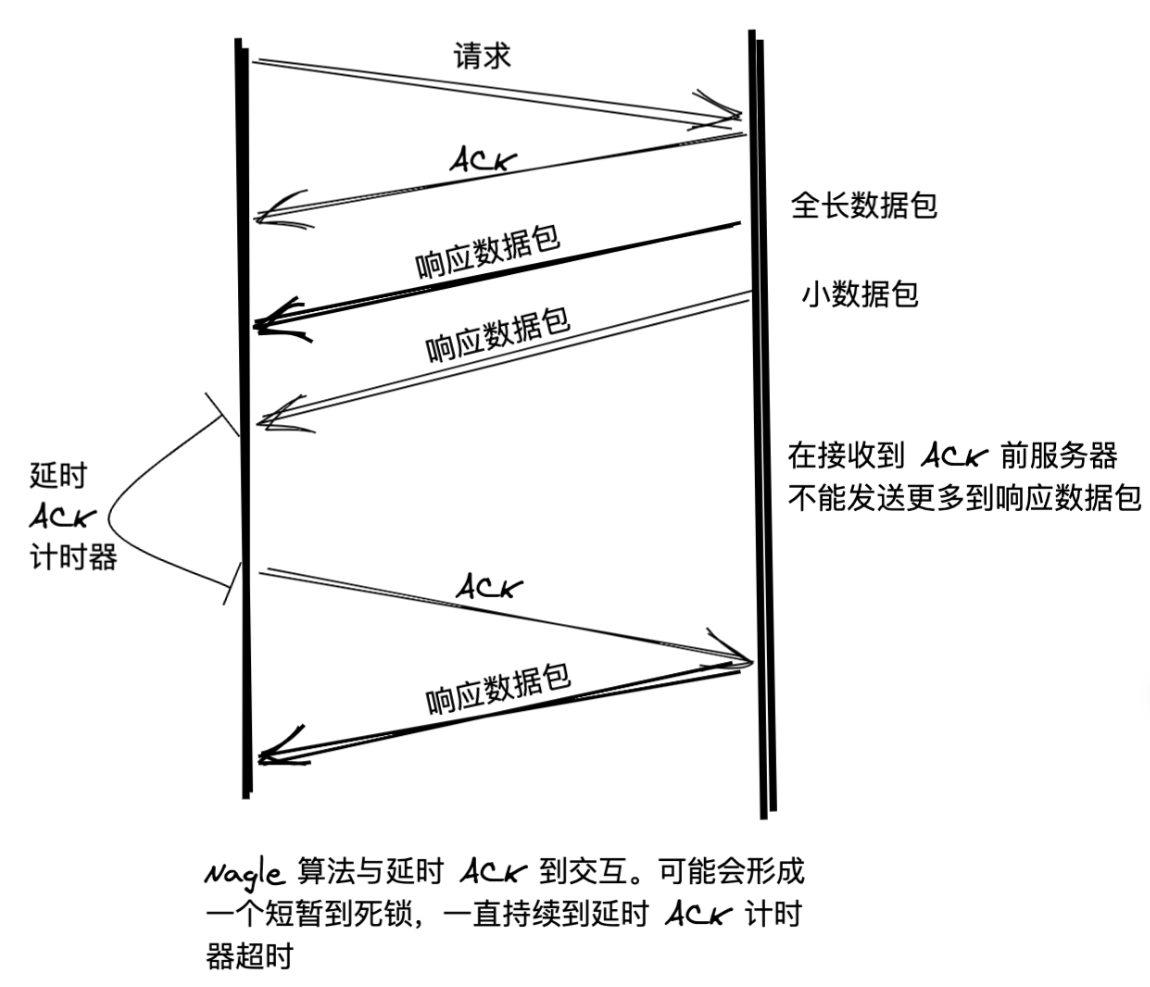
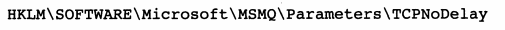Nagle算法主要是避免发送小的数据包,要求TCP连接上最多只能有一个未被确认的小分组,在该分组的确认到达之前不能发送其他的小分组。
Nagle算法的目的:避免发送大量的小包,网络上每次只能一个小包存在,在小包被确认之前,只能积累发送大包,如果包长度达到MSS,则允许发送;如果该包含有FIN,则允许发送;但发生了超时(一般为200ms),则立即发送, 启动TCP_NODELAY,就意味着禁用了Nagle算法
Nagle算法会严重影响请求响应式协议的延迟。
如果我们的程序设计的不够合理,Nagle算法可能会增加程序的延迟。
如果你的程序是 write-write-read 模式,在使用了Nagle算法后,第二个 write 就会被推后一个RRT发送而造成一个很长的ack等待,从而产生一个延迟。为了避免这种情况,一般建议在应用层做缓冲,将两个write合在一起,成为 write-read。
但是还有一种情况是,在一个连接上并发的有多个请求时,我们很难将数据整合在一起,它们来自程序中不同的位置。而这种情况Nagle算法会大大增加程序的延迟。
因此,如果你没有十足的把握驾驭Nagle算法的话,我们建议使用 TCP_NODELY 关闭Nagle算法。
示例:观察 Nagle算法 的延迟
服务器端代码:recipes/tpc/nodelay_server.cc
客户端代码:recipes/tpc/nodelay.cc
而代码的逻辑也很简单。客户端是一个 write-write-read 程序,通过制定参数 对比 采取不同TCP选项下程序的延迟情况。
// nodelay_server.cc 服务端代码部分
// 处理逻辑:收header ——》收数据 ——》回响应
//...
int main(int argc, char* argv[])
{//...bool nodelay = argc > 1 && strcmp(argv[1], "-D") == 0;while (true){TcpStreamPtr tcpStream = acceptor.accept();printf("accepted no. %d client\n", ++count);if (nodelay)tcpStream->setTcpNoDelay(true);while (true){int len = 0; // 收headerint nr = tcpStream->receiveAll(&len, sizeof len);if (nr <= 0)break;printf("%f received header %d bytes, len = %d\n", now(), nr, len);assert(nr == sizeof len);std::vector<char> payload(len); // 收数据nr = tcpStream->receiveAll(payload.data(), len);printf("%f received payload %d bytes\n", now(), nr);assert(nr == len); // 回响应int nw = tcpStream->sendAll(&len, sizeof len);assert(nw == sizeof len);}printf("no. %d client ended.\n", count);}
}
double start = now();for (int n = 0; n < num; ++n){printf("Request no. %d, sending %d bytes\n", n, len);if (buffering) // 如果设置缓冲,我们将header与数据合在一起发送{std::vector<char> message(len + sizeof len, 'S');memcpy(message.data(), &len, sizeof len);int nw = stream->sendAll(message.data(), message.size());printf("%.6f sent %d bytes\n", now(), nw);}else // 如果没有设置缓冲,分两次发送header和数据{stream->sendAll(&len, sizeof len);printf("%.6f sent header\n", now());usleep(1000); // prevent kernel merging TCP segmentsstd::string payload(len, 'S');int nw = stream->sendAll(payload.data(), payload.size());printf("%.6f sent %d bytes\n", now(), nw);}}
编译服务端代码:g++ -o nodelay_server nodelay_server.cc Acceptor.cc InetAddress.cc TcpStream.cc Socket.cc -lpthread -std=c++11
编译客户端代码:g++ -o nodelay nodelay.cc Acceptor.cc InetAddress.cc TcpStream.cc Socket.cc -lpthread -std=c++11
测试:使用ping命令,可以看到正常的RTT约31ms延迟。然后执行程序,大概有61ms的延迟,是RTT的两倍。

使用 buffering 选项,可以看到延迟减少到35ms左右。

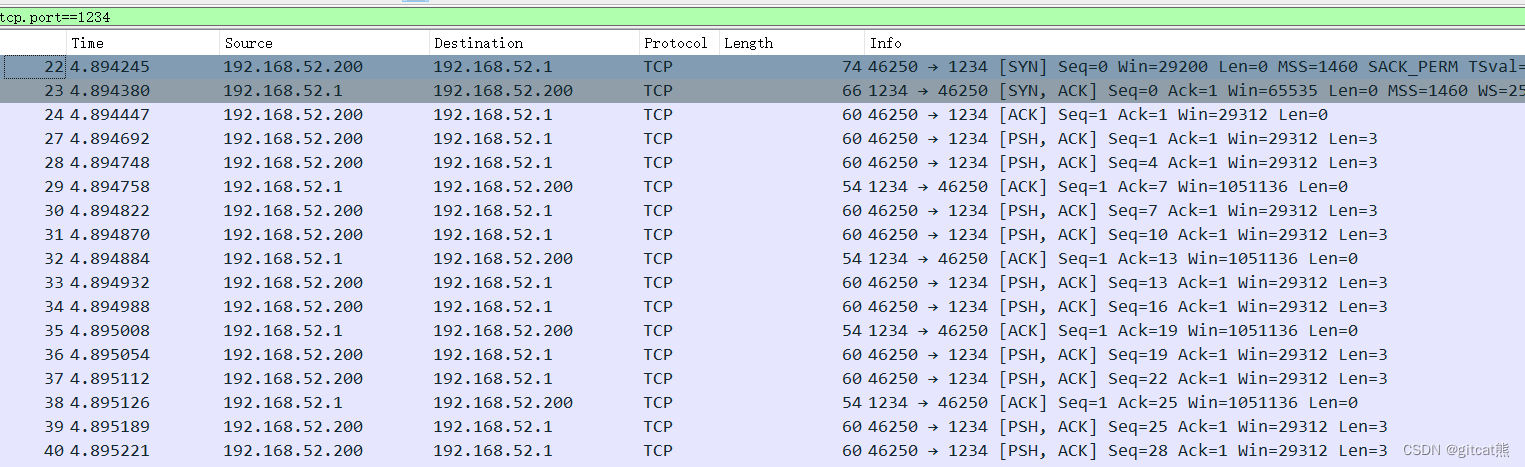
通过tcpdump我们可以看到,客户端一次发送了 1005 个字节的数据。客户端 write-read