Iperf 是一个网络性能测试工具。Iperf可以测试TCP和UDP带宽质量。Iperf可以测量最大TCP带宽,
具有多种参数和UDP特性。Iperf可以报告带宽,延迟抖动和数据包丢失。
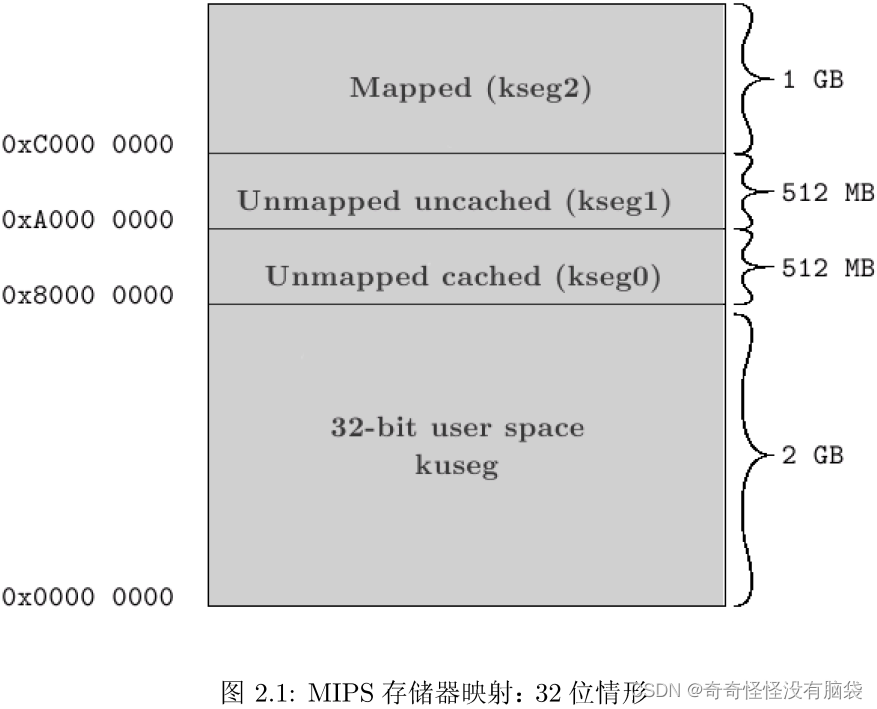
Iperf使用方法与参数说明
参数说明
-s 以server模式启动,eg:iperf -s
-c host 以client模式启动,host是server端地址,eg:iperf -c 222.35.11.23
通用参数

-f [k|m|K|M] 分别表示以Kbits, Mbits, KBytes, MBytes显示报告,默认以Mbits为单位,eg:iperf -c 222.35.11.23 -f K -i sec 以秒为单位显示报告间隔,eg:iperf -c 222.35.11.23 -i 2 -l 缓冲区大小,默认是8KB,eg:iperf -c 222.35.11.23 -l 16 -m 显示tcp最大mtu值 -o 将报告和错误信息输出到文件eg:iperf -c 222.35.11.23 -o c:\iperflog.txt -p 指定服务器端使用的端口或客户端所连接的端口eg:iperf -s -p 9999;iperf -c 222.35.11.23 -p 9999 -u 使用udp协议 -w 指定TCP窗口大小,默认是8KB -B 绑定一个主机地址或接口(当主机有多个地址或接口时使用该参数) -C 兼容旧版本(当server端和client端版本不一样时使用) -M 设定TCP数据包的最大mtu值 -N 设定TCP不延时 -V 传输ipv6数据包 server专用参数 -D 以服务方式运行ipserf,eg:iperf -s -D -R 停止iperf服务,针对-D,eg:iperf -s -R client端专用参数 -d 同时进行双向传输测试 -n 指定传输的字节数,eg:iperf -c 222.35.11.23 -n 100000 -r 单独进行双向传输测试 -t 测试时间,默认10秒,eg:iperf -c 222.35.11.23 -t 5 -F 指定需要传输的文件 -T 指定ttl值
操作举例:
1)TCP测试
服务器执行:#iperf -s -i 1 -w 1M
客户端执行:#iperf -c host -i 1 -w 1M 其中-w表示TCP window size,host需替换成服 务器地址。
2)UDP测试
服务器执行:#iperf -u -s
客户端执行:#iperf -u -c 10.32.0.254 -b 900M -i 1 -w 1M -t 60
Iperf -u -c -i 1 -l 542 -b 2m -t 999999 iperf -u -c 10.111.111.11 -l256 -b50M -t999999 -i1 iperf -u -s -i1 -w4m
其中-b表示 使用带宽数量,千兆链路使用90%容量进行测试就可以了。
几个命令参数:
#iperf -c 10.1.1.1 //客户端命令 #iperf -s //服务端命令 -f [b|B|k|K|m|M|g|G] //f参数表示单位 -r //r参数表示双向数据测试,但要先测c到s的带宽 -d //d参数和r近似,并且功能更强,可同时测试双向数据 -w [2000] //w参数后跟数字,单位是byte, -p [12000] //p参数可指定端口号 -t [20] //t参数默认表示测试10次,后加数字可以自己定义 -i [2] //i参数表示测试开始到结束的间隔时间,单位s -u -b 10m //udp 10mbps 测试 -m //最大mpu测试 -P //并行测试 -h //帮助
iperf工具使用
很多公司都在将自己的无线网络升级到802.11n,以实现更大的吞吐量、更广的覆盖范围和更高的可靠性,
然而保证无线LAN(WLAN)的性能对于确保足够的网络容量和覆盖率尤为重要。下面,我们将探讨如何通过
iPerf来测定网络性能,这是一个简单易用测量TCP/UDP的吞吐量、损耗和延迟的工具。
应用前的准备
iPerf是专门用于简化TCP性能优化的工具,使用它可以很容易地测量吞吐量和带宽的最大值。当与UDP一
起使用时,iPerf还可以测量数据丢失和延迟(抖动)。iPerf可以在任何IP 网络上运行,包括本地以太网,因特
网接入连接和Wi-Fi网络。
使用iPerf之前,必须安装两个组件:iPerf 服务器(用于监听到达的测试请求)和iPerf客户端(用于发起测
试会话)。iPerf可通过开放源代码或可执行二进制方式获取,它支持许多操作系统平台,包括Win32、Linux、
FreeBSD、MacOS X、OpenBSD和Solaris。你可以在NLANR上下载iPerf的Win32安装程序,而Java GUI版本
(JPerf)则可以从SourceForge下 载。
为了测量Wi-Fi性能,你可能需要在所测试的接入点(AP)的以太网主机上游位置上安装iPerf——这个也就
是你的测试服务器。接着,在一个或更多的Wi-Fi笔记本上安装iPerf——这些将是你的测试客户端。这个就是典型
的Wi-Fi客户端与有线服务器之间的应用网络。如果你的目的是测量AP性能,那么可以把iPerf服务器与AP放置在
相同LAN上,并通过高速或超高速以太网连接。如果你的目的是清除瓶颈问题,那么可以将iPerf服务器要与实际的
应用服务器放置在相同位置,这样就会有一个可比较的网络通道。
另外,iPerf 服务器和客户端可以同时安装在Wi-Fi笔记本上的。当你要在无线客户端上支持视频或语音通信,
那么这对于测量客户端到客户端性能是有帮助的。同样,要确保iPerf流量能够穿越你要测试的整个网络通道。比
如,如果你要在相邻位置的Wi-Fi客户端上测量性能的最佳值,你必须把你的iPerf客户端和服务器接入到相同的
AP上。如果你想要观察穿越上流交换机或WAN的路由是如何影响网络性能的,那么可以把你的iPerf服务器接入
到一个中央AP上,并且将iPerf客户端与在不同的地点的AP连接。
运行iPerf
在默认的情况下,iPerf客户端与指定的监听5001端口的iPerf服务器建立一个TCP会话。比如,在命令提示符
上执行命令:iperf –s,打开iPerf服务器;然后打开另一个窗口来启动你的iPerf客户端:
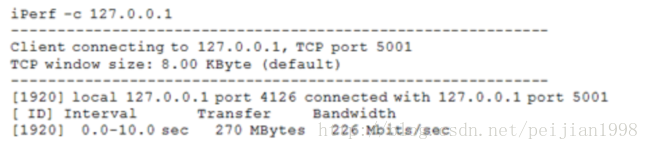
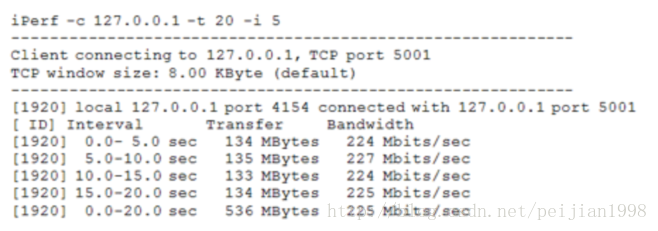
上面命令是你可以用来测量通过某个计算机回环地址(127.0.0.1)吞吐量。如果执行失败,那么这就表示
你没有正确的安装iPerf。默认的情况下,iPerf运行一个10秒钟的测试,测量所传输的字节总数(如270兆字节)
和相应的带宽使用估计(如226兆比特每秒)。测试长度可以通过指定时间参数(-t seconds)或缓冲参数
(-n buffers)控制。而且,你还可以在指定时间间隔(-i seconds)中看到测试的结果。
如果要长时间地运行多个的测试,你应该更愿意将iPerf服务器作为后台程序运行,并将服务器输出写入
一个日志文件中。在Win32平台上,它可以通过把iPerf作为服务(iPerf --s --D --o logfile.txt)安装来实现。
如果你测试的流量将要通过网络防火墙,那么要确保打开端口5001或指定iPerf使用已经开放的端口
(如,iPerf --c --p 80)。如果你的iPerf服务器处于NAT防火墙之后,那么你可能需要配置一个端口转发规则
来进行连接(这种情况在服务器到客户端流量的双向测试中也一样适用)。最后,要禁用你的iPerf客户端和
服务器上的任何个人防火墙。当客户端能够到达服务器时,你就可以开始测量网络性能了。
测量TCP吞吐量
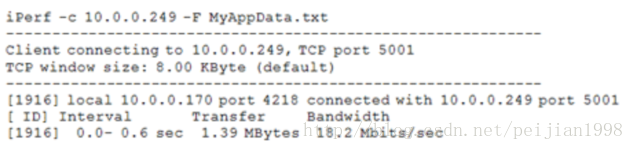
为了确定最大TCP吞吐量,iPerf尝试从客户端尽可能快地向服务器上发送数据。默认时数据是以8KB大小
缓冲发送的,这也是通过操作系统的默认的TCP窗口大小值。为了模拟特定TCP应用,你可以指定你的iPerf
客户端从一个特定的文件(-F 文件名)或交互式输入(-I)来发送数据。比如:
如果你没有指定发送方式,iPerf客户端只会使用一个单一的线程。而你可以修改为使用多个并行线程
(-P数目)来发送数据。在测试Wi-Fi时,在同一台笔记本上的多线程可能会略微增加整体的吞吐量。

但是,有时你将需要使用多台拥有各自Wi-Fi适配器的笔记本来模拟几个不同位置用户体验的性能。
这是因为在同一个笔记本上运行的多线程仍然共享同一个Wi-Fi适配器上的占 用时间。
另外一方面,如果你的笔记本上拥有多个激活的适配器,你可以使用IP地址(-B IPAddress)将
iPerf客户端绑定到一个适配器上。这个对于同时连接到Ethernet和Wi-Fi(3G、Wi-Fi)的多连接笔记本
来说是相当重要的。
iPerf原先是开发用来辅助TCP参数优化的,但在此我们不想深入研究TCP窗户尺度和最大段长度,
因为这不是我们目前讨论的重点。然而,在测试高吞吐量AP时,你可能发现有必要对TCP参数进行调优,
以便在每个iPerf 客户端上获得更大吞吐量——详细请阅读DrTCP。
使用测试工具iPerf监控无线网络性能:测量UDP丢包和延迟
iPerf同样也可以用于测量UDP数据包吞吐量、丢包和延迟指标。与TCP测试不同的是,UDP测试不采取
尽可能快地发送流量的方式。与之相对的是,iPerf尝试发送1 Mbps的流量,这个流量是打包在1470字节的
UDP数据包中(成为以太网的一帧)。我们可以通过指定一个目标带宽参数来增加数据量,单位可以是Kbps
或Mbps(-b #K 或 --b #M)。举例如下:
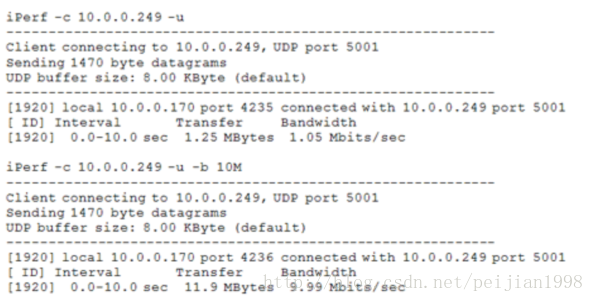
然而,上面的例子只说明了iPerf客户端能够以多快的速度传输数据。为了得到更多关于UDP发送的数据,
我们必须查看服务器上的结果:
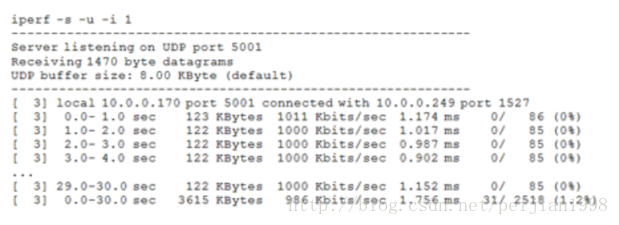
这样,我们就可以看到吞吐量(间隔1秒测量的),以及丢包数(丢失的数据屯接收到的数据对比)
和延迟(如jitter——在连续传输中的平滑平均值差)。延迟和丢失可以通过应用的改变而被兼容。比如,
视频流媒体通过缓冲输入而能够容忍更多的延迟,而语音通讯则随着延迟增长性能下降明显。
UDP测试可以通过改变报文缓冲长度进行优化,长度单位为Kbytes 或 Mbytes(-l #K or #M)。
与以太网帧的1500比特的MTU(最大转换单位)不同的是,802.11数据帧可以达到2304比特(在加密之前)。
但是,如果你正在测试的路径中包括Ethernet和802.11,那么要控制你的测试数据包长度,使它在一个
Ethernet帧以内,以避免分片。
另一个有趣的iPerf UDP测试选项是服务类型(Type of Service, ToS),它的大小范围从0x10 (最小延迟)
到0x2 (最少费用)。在使用802.11e来控制服务质量的WLAN中,ToS是映射在Wi-Fi多媒体(WMM)存取范畴的。
对比两种方式
在802.11a/b/g网络中,无线电的传输性能变化在在两个方向上都很相似。比如,当距离导致数据传输率下降
或干扰造成重要数据包丢失时,发送和接收的应用吞吐量都受到影响。
在802.11n网络中,MIMO天线和多维空间流使问题又有所不同。从笔记本发送到AP上的数据帧可能(有意地)
使用一个完全与从AP发送到笔记本上帧时不同的空间路径。这样的结果是,现在对两个方向的测试都很重要的。
幸运的是,iPerf本身就已经拥有这个功能,这是由两个选项所控制的:
--d选项是用于告诉iPerf服务器马上连接回iPerf客户端的由
--L 所指定端口,以支持同时测试两个方向的传输。
--r选项虽然有些类似,但是它是告诉iPerf服务器等到客户端测试完成后再在相反的方向中重复之前的测试。
最后,如果你需要支持多点传送应用,那么可以使用-B选项指定多点传送组IP地址来启动多个iPerf服务器。
然后再打开你的iPerf客户端,连接之前启动的多点传送组iPerf服务器。