《Fused Text Segmentation Networks for Multi-oriented Scene Text Detection》
用于多场景文本检测的融合文本分割网络。(2018.5.7)
文章笔记
摘要 - 本文从实例感知语义分割的角度介绍了一种新的面向多向场景文本检测的端到端框架。 我们提出了融合文本分割网络,它在特征提取过程中结合了多级特征,因为与一般对象相比,文本实例可能依赖于更精细的特征表达。 它利用来自语义分割任务和基于区域建议的对象检测任务的优点,共同和同时检测和分割文本实例。 不涉及任何额外的管道,该方法超越了多方位场景文本检测基准的现有技术水平:ICDAR2015偶然场景文本和MSRA-TD500分别达到Hmean 84.1%和82.0%。 更重要的是,报告了包含弯曲文本的全文的基线,这表明了所提方法的有效性。
介绍
近年来,场景文本检测引起了计算机视觉和机器学习界的极大关注。在照片翻译和收据内容识别等许多基于内容的图像应用的推动下,它已成为学术界和工业界一个充满希望和挑战的研究领域。在自然图像中检测文本是困难的,因为文本和背景在野外都可能很复杂,并且经常遭受诸如遮挡和不可控制的光照条件的干扰[1]。以前的文本检测方法[2],[3],[4] ],[5],[6]在几个基准测试中取得了可喜的成果。文本检测中的基本问题是使用表示文本区域,传统上,手工制作的特征被设计[3],[7],[8]来捕捉文本区域的属性,如纹理和形状,而在过去的几年中,基于深度学习的方法[9], [10],[6],[11],[12],[13]直接从训练数据中学习等级特征,在各种基准测试中展示更准确和有效的性能,如ICDAR系列竞赛[14],[15],[ 16。现有方法[10],[9],[6],[13]已经获得了用于检测水平或近水平文本的良好性能。虽然水平文本检测具有轴对齐边界框基本事实的约束,但是多向文本不限于特定方向,并且通常使用四边形来进行注释。因此,与水平场景文本检测基准[14],[15]相比,它报告ICDAR 2015竞赛挑战4附带场景文本定位[16]的准确度相对较低。
最近,已经提出了一些方法[17],[18],[19],[20],[21],[22]来解决多方向文本检测。通常,目前有四种不同类型的方法。基于区域的方法[19],[22],[21]利用先进的物体检测技术,如更快的RCNN [23]和SSD [24]。基于分割的方法[25],[26]主要利用完全卷积神经网络(FCN)来生成文本分数图,这通常需要几个阶段和组件来实现最终检测。基于直接回归的方法[18]从给定点回归对象的位置和大小。最后,混合方法[20]将文本分数图和旋转/四边形边界框生成结合起来,在多方向文本检测中协同获得高效准确的性能。在实例感知语义分割的最新进展[27],[28]的启发下,我们提出了一种处理多向文本检测任务的新视角。在这项工作中,我们利用基于精确区域建议的方法[23]的优点,以及基于灵活分割的方法,可以轻松生成任意形状的文本掩码[25],[26]。它是一个端到端的可训练框架,不包括冗余和低效的管道,如使用文本/非文本显着图[25]和文本行生成[26]。基于区域提议网络(RPN),我们的方法同时检测和分割文本实例,然后是非最大抑制(NMS)以抑制重叠实例。最后,作为整个检测过程的结果,生成适合每个实例区域的最小四边形边界框。
我们的主要贡献总结如下:
• 我们从实例感知分段角度提供了一个针对多向文本检测的端到端高效且可训练的解决方案,不包括任何冗余管道。
• 在特征提取期间,要素图以融合方式组合,以自适应地满足文本实例的更精细表示。
• 引入Mask-NMS以在面向严重倾斜或行级文本实例时改进标准NMS。
• 没有许多花里胡哨的东西,我们的方法在当前的多方向文本检测基准测试中优于现有技术水平。
相关工作
在过去的几年中,在自然图像中检测文本已被广泛研究,其动机是许多与文本相关的现实世界应用,例如照片OCR和盲导航。用于场景文本检测的主流传统方法之一是基于连通分量(CC)的方法[29],[30],[10],[31],[32],它们将文本视为一组单独的组件,例如字符。在这些方法中,笔划宽度变换(SWT)[3],[31]和最大稳定极值区域(MSER)[33],[32],[7]通常用于寻找候选字符。最后,这些候选者被组合以获得文本对象。虽然这些自下而上的方法在一些基准[14],[15]上可能是准确的,但它们经常遭受太多管道的困扰,这可能导致效率低下。另一种主流传统方法是基于滑动窗口[2],[34],[10]。这些方法通常使用固定大小或多尺度窗口来滑动搜索最可能包含文本的区域的图像。然而,滑动窗口的过程可能涉及大的计算成本,这导致低效率。通常,传统方法通常需要几个步骤来获得最终检测,并且手工设计的特征通常用于表示文本的属性。因此,它们可能会遇到低效率和低泛化能力,以应对非均匀照明等复杂情况[35]。
基于深度学习的对象检测和语义分割方法的最新进展提供了用于在野外阅读文本的新技术,其也可以被视为一般对象检测的实例。在Faster RCNN [23]和SSD [24]等对象检测框架的推动下,这些方法通过使用区域提案网络首先对一些文本区域提案进行分类来实现最先进技术[22],[17],或直接从一组默认框[13],[19]回归文本边界框坐标。这些方法能够在水平或多向场景文本检测基准上实现领先的性能。然而,即使采用适当的旋转,它们也可能被限制为矩形边界框约束[21]。不同于这些方法,基于FCN的方法生成文本/非文本地图,其在像素级别对文本进行分类[25]。虽然它可能适合于自然图像中任意形状的文本,但它通常涉及多个管道,导致效率低下[25],[17]。
受到实例感知语义分割[27],[28]的最新进展的启发,我们提出了一种称为融合文本分割网络(FTSN)的端端可训练框架,以处理任意形状的文本检测,而不涉及额外的管道。 它继承了对象检测和语义分割架构的优点,它可以同时有效地检测和分割文本实例,并准确地给出像素级别的预测。 由于文本可能依赖于更精细的特征表示,因此设置由多级特征映射形成的融合结构以适合该属性。
方法
提出的多方位场景文本检测框架如图2所示。 它是一个深CNN模型,主要由三部分组成。 通过resnet-101主干[36]提取每个图像的特征表示,然后将多级特征图融合为FusedMapA,将其馈送到用于感兴趣的文本区域(ROI)生成的建议网络(RPN)区域和用于稍后的FusedMapB。 rois'PSROIPooling。 最后,将rois发送到检测,分段和框回归分支,以输出像素级别的文本实例及其对应的边界框。 后处理部分包括NMS和最小四边形生成。

图2 拟议的框架由三部分组成:特征提取,特征融合以及区域提议和文本实例预测。 虚线表示具有1x1内核大小和1024个输出通道的卷积。 红色线用于上采样操作,蓝线表示使用给定ROI执行PSROIPooling的功能图。
A.网络架构
卷积特征表示以融合方式设计。文本实例不像一般对象,例如具有相对较强语义的人和汽车。相反,文本在类内几何中经常变化很大。因此,应考虑低级特征。基本上,resnet-101由五个阶段组成。在区域提议之前,阶段3和上采样阶段4特征映射通过元素添加组合形成FusedMapA,然后阶段5的上采样特征映射与FusedMapA融合以形成FusedMapB。注意,在阶段5期间不涉及下采样。相反,我们使用洞算法[37],[38]来保持特征步幅并保持感受野。这样做的原因是文本属性和分段任务都可能需要更精细的功能,并且涉及最终的下采样可能会丢失一些有用的信息。因为使用阶段3的特征步幅可能会导致原始RPN中的数百万个锚点[23],这使得模型训练变得困难,所以我们添加了一个3×3的步长2卷积来减少如此庞大的锚点数量。关注FCIS [27],我们使用联合蒙版预测和分类,用于在conv-cls-seg特征图上通过PSROIPooling生成的2×(1 + 1)内/外分数图上同时对文本实例进行分类和掩盖,并且框回归分支使用4×(1 + 1) PSROIPooling之后来自convbox的特征映射(“1 + 1”表示一个类用于文本而另一个用于背景)。我们默认在实验中使用图2所示的k = 7。值得注意的是,在PSROIPooling之后,特征图的分辨率变为21×21。因此,我们使用全局平均合并[39]进行分类(按像素方式最大化)和框回归分支,以及掩模分支上的逐像素softmax。
B.真实标签和损失函数
整个多任务损失L可以解释为
L = L rpn + L ins(1)
L rpn = L rcls +λrL rbox(2)
L ins = L cls +λmL mask +λbL box(3)
损L由两个子阶段损失组成:RPN损失L rpn其中L rcls用于区域建议分类和L rbox用于框回归,并且基于每个ROI的文本实例损失L ins,其中L cls,L mask和L box分别表示例如分类,掩码和框回归任务的损失。 λ是控制每个损失项之间平衡的超参数。
C.后处理
Mask-NMS为了获得最终检测结果,我们使用NonMaximum Suppression机制(NMS)来过滤重叠的文本实例并保留那些得分最高的实例。 在NMS之后,我们为覆盖掩码的每个文本实例生成最小四边形,如图1所示。

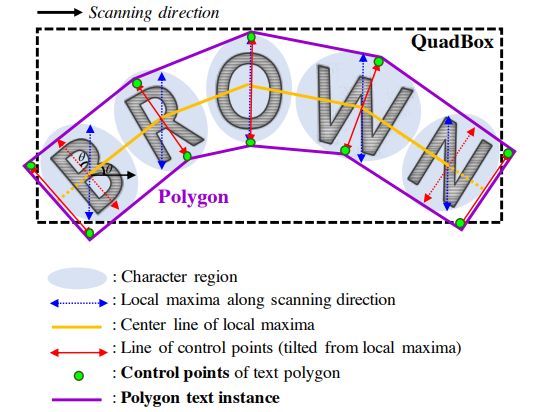
图1 FTSN工作流程。 从左到右,输入图像,文本实例分割结果和最终处理的四边形结果如图所示。
标准NMS在边界框中计算IOU,这对于字级和近水平结果的过滤可能很好。 然而,如图4所示,当它们靠近并且倾斜很大时,或者当单词保持接近于如图5所示的相同行时,它可以过滤一些正确的行级检测。 因此,我们提出了一个名为Mask-NMS的修改后的NMS来处理这种情况。 Mask-NMS主要将边界框IOU计算更改为所谓的maskmaximum-intersection(MMI),如下所述:

图4

图5
实验
为了评估提议的框架,我们在三个公共基准上进行了定量实验:ICDAR2015,MSRA-TD500和Total-Text。

结果



结论
我们提出了FTSN,一种端到端的高效准确的多方位场景文本检测框架。 它在字级线性注释基准测试方面优于先前的最新技术方法,并报告了总体文本的基线,证明了良好的泛化能力和灵活性。