最近在看生成对抗网络(Generative Adversarial Networks,GAN)的时候,几乎在每一篇文章中都会看到mainfold这个词,哪么它在GAN中想要表达什么呢?或者说GAN和流形学习(Mainfold Learning)之间又有着什么样的关联呢?下面给出我在查阅了相关资料的一个简单的总结。
对于机器学习所使用的大多数数据集而言,数据的维度都很高,例如,MNIST中的样本为 32 × 32 32 \times 32 32×32,那么数据所在的空间就是1024维。如果直接去处理这样的数据,当前的机器学习算法显得就无能为力了。然而,对于大部分的数据来说,尽管它所在的数据空间维度很高,但是通常高维的数据通常可以由低维空间中的数据表示。因此,如果我们可以找到高维数据空间到低维空间的映射,那么就可以大幅度的减小数据的维度,经过降维的数据就可以满足现有的机器学习算法的输入要求。在真正的了解流行学习之前,我们先来看几个基本概念。
维度
维度(Dimensionality )是指在空间或对象中指定任意点所需的最小坐标数。例如,对于一条直线来说,我们只需要使用一个坐标轴就可以表示它;对于一个平面图像,我们就需要增加一个坐标轴;而对于三维图像而言,它就需要使用 x , y , z x,y,z x,y,z所组成的坐标系就行表示。
流形
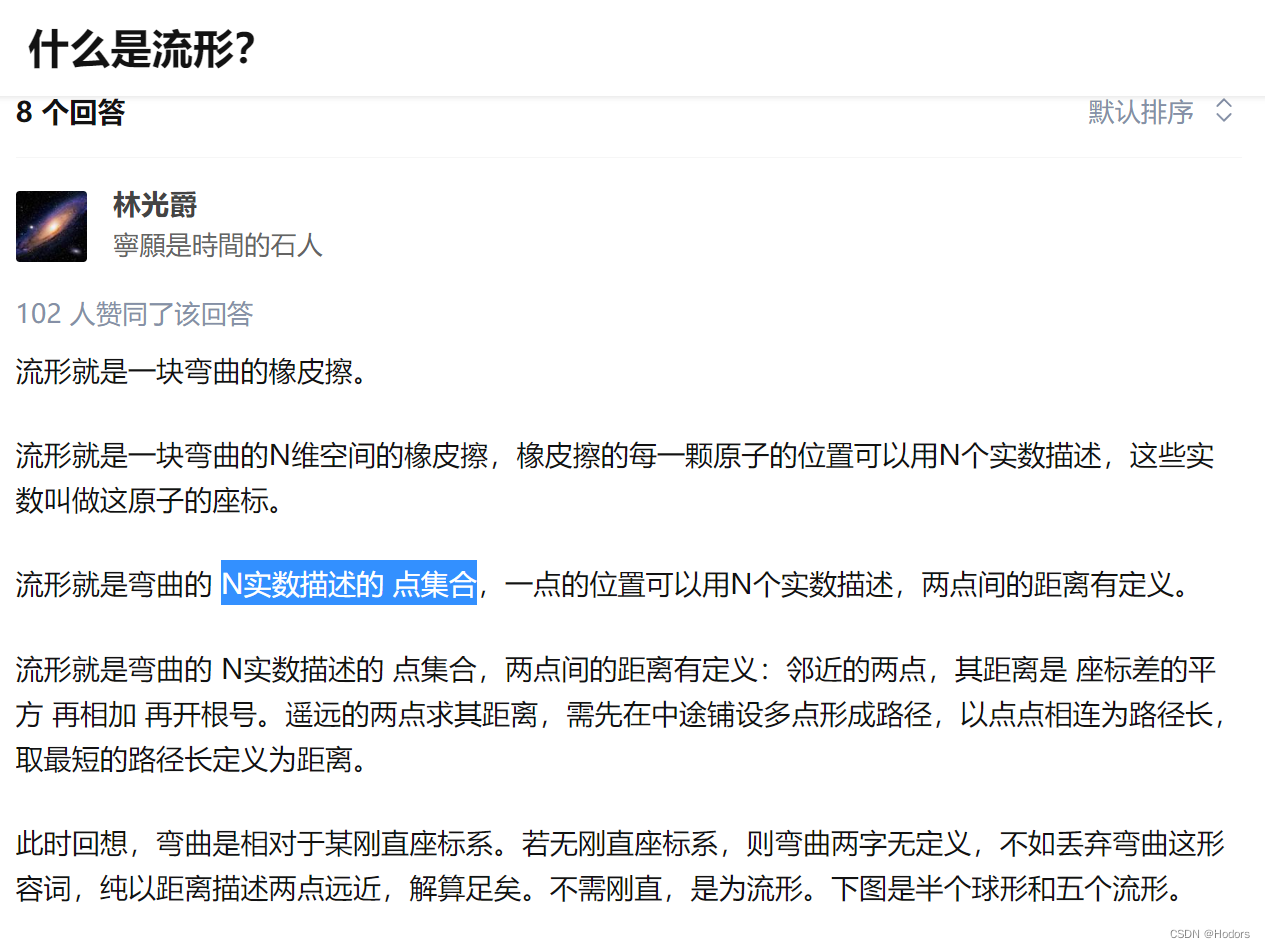
流形(manifold)是几何中的一个概念,它是高维空间中的几何结构,即空间中的点构成的集合。可以简单的将流形理解成二维空间的曲线,三维空间的曲面在更高维空间的推广。
拓扑学角度:局部区域线性,与低维欧式空间拓扑同胚(连续的变换最后都能变成一样的两个物体,称为同胚,Homeomorphism)。
微分几何角度:有重叠chart的光滑过渡(把流体的任何一个微小的局部看作是欧几里德空间,称为一个chart)。
黎曼流形就是以光滑的方式在每一点的切空间上指定了欧式内积的微分流形。
流形学习
流形学习认为我们所能观察到的数据实际上是由一个低维流形映射到高维空间上的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示。
流形学习方法是模式识别中的基本方法,分为线性流形学习算法和非线性流形学习算法,线性方法就是传统的方法如主成分分析(PCA)和线性判别分析(LDA)。关于PCA,可见之前的一篇博客:[主成分分析(Principal Component Analysis,PCA)]
非线行流形学习算法包括等距映射(Isomap),局部线性嵌入(LLE)、拉普拉斯特征映射(LE)等。
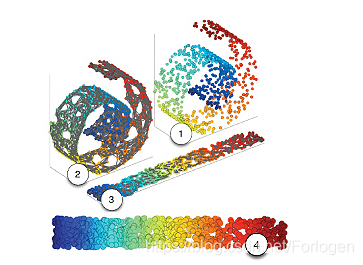
上图是一个很常见的“瑞士卷”的数据,它位于一个三维空间中,但是我们可以使用非线性流行学习方法将其铺平到二维空间中,从而方便我们的处理。
那么流形学习在机器学习中具有什么作用呢?我认为可以简单的从两个方便来看:
降维
对于拥有很多特征的数据而言,它所在空间的维度可能很高,但是特征之间并不是完全独立的,它们之间会有一些关联性,比如描述房屋的特征中的面积和卧室的数量往往是有着紧密的联系的,那么在在具体的描述房屋时,我们就可以选择丢弃其中一个,但基本上不影响表达的准确性。因此,我们认为数据在高维空间中是有冗余的,而在低维空间是没有冗余的,通过流行学习我们就可以找到数据在低维空间中的关键特征,这样就减小了处理的难度,又保留了数据的大部分重要的信息,原理可以类比PCA。
因为流形是在局部与欧式空间同胚的空间,即它在局部具有欧式空间的性质,能用欧式距离进行距离的计算。例如我们的地球就是一个二维的流形,但是在局部可以认为是欧式空间。

但是在很多的情况下这种方式是不太靠谱的。比如我们在地球仪上的赤道任选两点,想要找到两点之间的最短距离。我们知道两点之间直线最短,按照这个简单的想法,想要从某点出发到达另一点,就只能直接穿过地心,这显然是不符合逻辑的。实际上,如果我们将地球仪展开成二维平面,测量的是地表上的距离,也称为测地线距离,而不是三维空间球面上两个的欧式距离。
下面我们再来看一下关于流行学习最著名的两种算法:等度量映射和局部线性嵌入。
等度量映射(Isometric Mapping,Isomp)
根据前面的叙述前面我们知道,直接在高维的空间中计算直线距离有时是不可行的,因为两点之间距离最短的路径在低维空间中有时是不可达的。在低维流形中计算的是代表两点之间本真距离的“测地线距离”,那么如何在高维空间中正确的计算两点之间的最短距离呢?
借助高维流形的局部和欧式空间同胚的性质,我们可以将整体细分为很多的局部,在局部寻找每一个点基于欧式距离的近邻点,那么就可以建立一个高维流形的近邻连接图。这样两点之间最短距离的计算就转换成了近邻连接图中两点之间的最短路径,而图的最短路径的求解,我们可以直接使用Dijkstra算法或是Floyed算法。
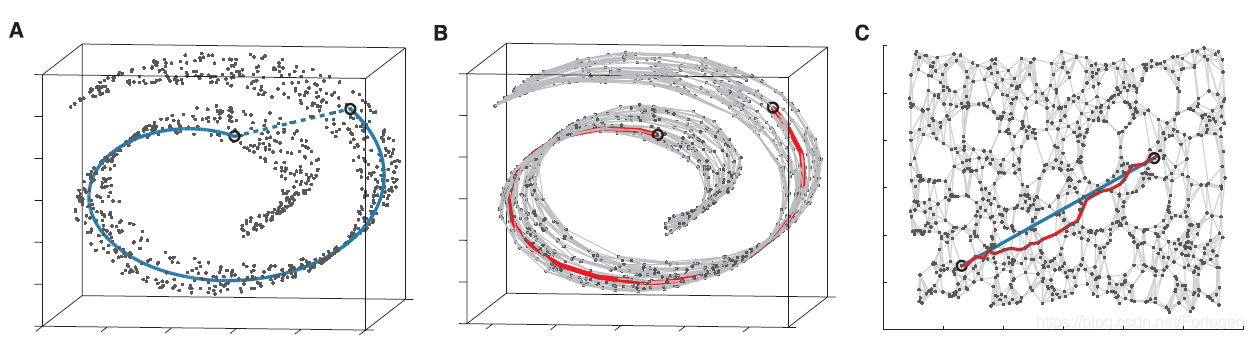
Isomap的算法流程如下所示
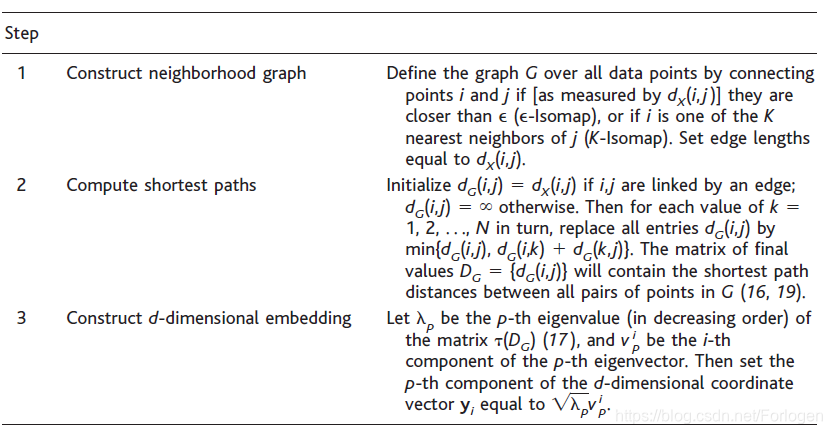
- 在输入空间 X X X一对数据点 i , j i,j i,j,根据距离 d x ( i , j ) d_{x}(i,j) dx(i,j) 找到在高维流形 M M M的邻域上的近邻点,而近邻点的选择可以根据设定的计算距离的阈值 ϵ \epsilon ϵ或是近邻点的最大个数 K K K;
- 通过计算 G G G中 i i i和 j j j之间的最短路径 d G ( i , j ) d_{G}(i,j) dG(i,j)来计算高维流形 M M M上两个点之间的测地线距离 d M ( i , j ) d_{M}(i,j) dM(i,j);
- 将MDS应用到图距离矩阵 D G ( d g ( i , j ) ) D_{G}(d_{g}(i,j)) DG(dg(i,j)) 中,构造在 d d d维欧式空间 Y Y Y中的数据嵌入,通过最小化代价函数 E = ∥ τ ( D G ) − τ ( D Y ) ∥ L 2 E=\left\|\tau\left(D_{G}\right)-\tau\left(D_{Y}\right)\right\|_{L^{2}} E=∥τ(DG)−τ(DY)∥L2来选择 Y Y Y中点的坐标向量 y i y_{i} yi,使其能最好的保留高维流形固有的几何结构
Isomap的特点:
- 不同于PCA、MDS只能应用于线性降维,Isomap可以发现高维流形中复杂的非线性的低维嵌入空间
- Isomap算法是全局的,它要找到所有样本全局的最优解,当数据量很大时或者样本维度很高时,计算量非常大
- Isomap可以保证渐进的收敛到真实的结构,即使高维流形是很复杂的几何结构,Isomap依然可以保证产生全局最优的低维表示
- 当数据中含有噪声足够多时,Isomap会出现拓扑不稳定的现象,此时得到的低维嵌入空间并不能正确的反映高维流形的结构
下面我们看一下在Isomap提出的论文《A Global Geometric Framework for Nonlinear Dimensionality Reduction》中所给出的几个实验结果。
对于人脸图像数据集来说,图像的大小为 64 × 64 64 \times 64 64×64,那么每个图像的维度就是4096,而通过Isomap降维后,我们就可以用left-right pose、up-down pose和lighting direction三个维度的信息表示4096维原始输入空间的信息,如下所式
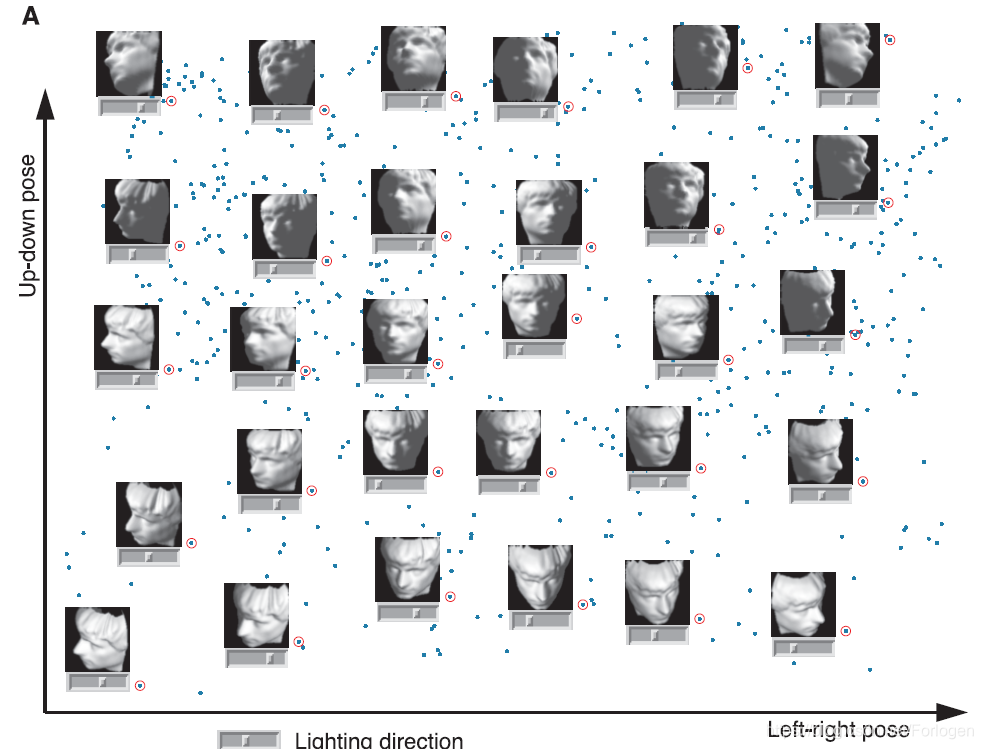
其中蓝色的点为数据点,红圈圈住的点和旁边的图像对应,坐标轴的两个维度为left-right pose和up-down pose,底下的滑块表示lighting direction。
对于手写数字2来说,使用Isomap降维后,可以使用Bottom loop articulation和Top arch articulation两个维度表示原始输入的信息

而且通过在降维得到的低维表示中进行插值,我们可以看出图像明显的变换情况

局部线性嵌入(Locally Linear Embedding,LLE)
LLE主页: https://cs.nyu.edu/~roweis/lle/algorithm.html
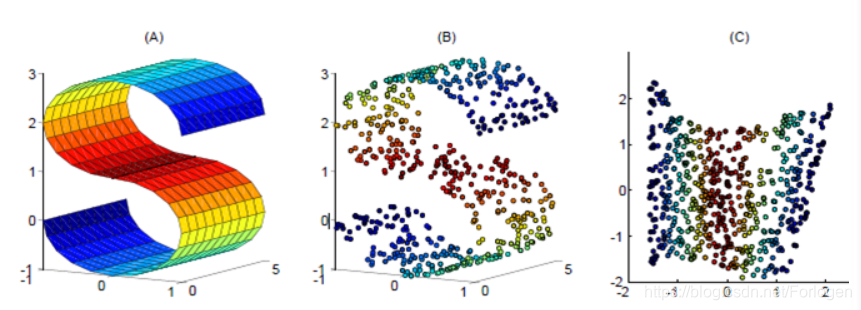
Isomap存在的一个很大的问题是,当数据中的噪声较多时,高维流形的拓扑就会变得不稳定。如下所示,当在Swiss roll数据集中加入一些高斯噪声后,降维得到的低维空间就无法保持高维流形的拓扑结构

为了缓解这个问题,不同于Isomap保持邻域内的样本的距离,LLE的基本思想是试图保持邻域内样本之间的线性关系,希望从高维空间映射到低维空间后,各邻域内的样本之间的线性关系不发生改变,从而希望可以从局部的线性结构恢复全局的非线性结构。
LLE的使用实例如下所示
关于LLE算法的详细数学推导可见:
局部线性嵌入(LLE)原理总结
LLE算法总结:
- 主要优点:
- 可以学习任意维的局部线性的低维流形。
- 算法归结为稀疏矩阵特征分解,计算复杂度相对较小,实现容易。
- 可以处理非线性的数据,能进行非线性降维。
- 主要缺点:
- 算法所学习的流形只能是不闭合的,且样本集是稠密的。
- 算法对最近邻样本数的选择敏感,不同的最近邻数对最后的降维结果有很大影响。
Sklearn库中提供关于流行学习的不同算法的支持,下面是给出的效果简单对比图

刻画数据的本质
既然学习到了“将数据从高维空间降维到低维空间,还能不损失信息”的映射,那这个映射能够输入原始数据,输出数据更本质的特征(就像压缩一样,用更少的数据能尽可能多地表示原始数据)。
其实,深度学习主要的特点就是“特征学习”,所谓特征,就是能“表示事物本质的内容”,一般来说特征的维度应该小于数据本身。
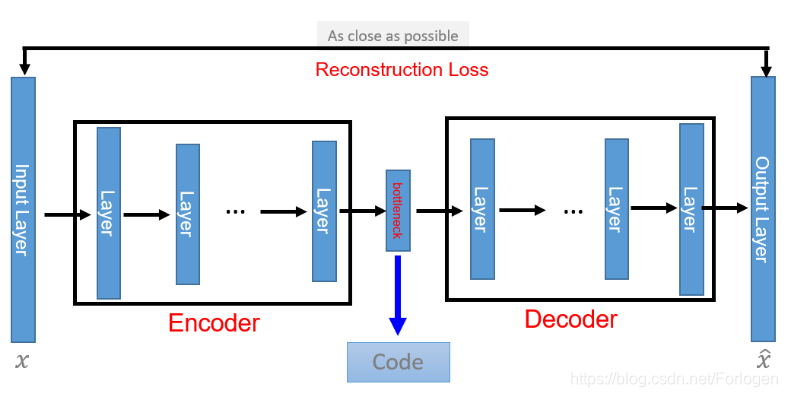
例如在如上所示的自编码器(Auto-encoder)中,中间瓶颈层的latent code的维度小于输入图像和重建图像的维度,但是通过不断的训练,使用latent code就可以解码得到和原始输入图像很接近的结果,这表示latent code学习到了关于表示图像的某些关键的特征,而不是简单的“记住”所有的特征。
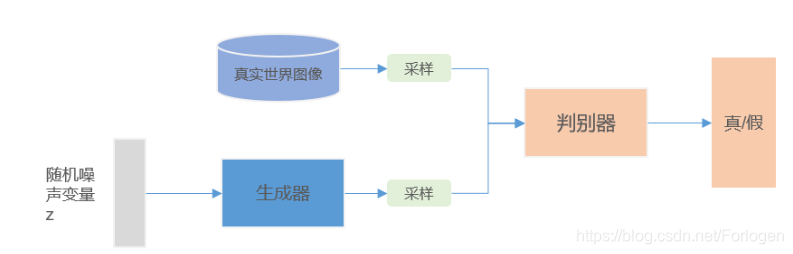
而且在生成对抗网络(Generative Adversarial Nets,GAN)中,即使真实图像是简单的 80 × 80 80 \times 80 80×80 大小的图像,数据的维度也是6400,假设输入到生成中的随机噪声向量为100维,同样的经过不断训练,生成器学习到表示样本关键特征的latent code 的维度小于100维,更别说真实数据的6400维了。所以,从中我们也可以看出,GAN根据高维流形的低维嵌入,可以学习到关于数据的关键信息。
参考
https://blog.csdn.net/dllian/article/details/7472916
http://blog.pluskid.org/?p=533
http://www.cnblogs.com/jiangxinyang/p/9314256.html
https://blog.csdn.net/bbbeoy/article/details/78002756
https://www.zhihu.com/question/24015486
https://zhuanlan.zhihu.com/p/40214106
https://prateekvjoshi.com/2014/06/21/what-is-manifold-learning/
https://scikit-learn.org/stable/modules/manifold.html
https://www.cnblogs.com/pinard/p/6266408.html?utm_source=itdadao&utm_medium=referral
http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=09D59893614EF635A2105213E0BDC2B1?doi=10.1.1.385.5679&rep=rep1&type=pdf