selenium的表单相关操作
selenium是浏览器自动化测试框架,是一个用于Web应用程序测试的工具,可以直接运行在浏览器当中,并可以驱动浏览器执行指定的动作,如点击、下拉、填充数据、删除cookie等操作,还可以获取浏览器当前页面的源代码,就像用户在浏览器中操作一样。该工具所支持的浏览器有IE浏览器、Mozilla Firefox以及Google Chrome等。selenium有很多语言的版本,比如:Java、Ruby、Python等。
操作表单元素
常见的表单元素
§ Input
§ button
§ checkbox
§ select
1、操作输入框: 分为两步, 第一步:找到元素 第二步:使用send_keys(value),将数据填充进去。示例代码如下:
# 以百度为例
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 3:35 PM
# 文件 :selenium操作input.py
# IDE :PyCharm# 导入webdriver 模块
from selenium import webdriver
# 导入time模块
import time# 创建浏览器引擎
driver = webdriver.Chrome(executable_path='chromedriver')# 指定url
url = 'http://www.baidu.com'# 使用引擎打开网页
driver.get(url)# 通过ID查找input框
inputTag = driver.find_element_by_id('kw')
# 向input框发送python值
inputTag.send_keys('python')# 停顿3秒
time.sleep(3)
使用clear 方法可以清除输入框中的内容。示例代码如下:
# 自动清除
inputTag.clear()
# 停顿3秒
time.sleep(3)# 关闭当前浏览页
driver.close()
2、操作checkbox:因为要选中checkbox 标签,在网页中是通过鼠标点击的。因此想要选中checkbox标签,那么选中这个标签,然后执行click事件。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 3:35 PM
# 文件 :selenium操作checkbox.py
# IDE :PyCharm# 导入webdriver模块
from selenium import webdriver
import time# 创建浏览器引擎
driver = webdriver.Chrome(executable_path='chromedriver')# 设定url
url = 'https://passport.mingrisoft.com/login/index.html?tpl=sch'# 打开网页
driver.get(url)# 通过name查找checkbox,本例默认是选中的
checkboxTag = driver.find_element_by_name('rempwd')
# 执行click()命令,取消默认选中
checkboxTag.click()
# 停顿3秒
time.sleep(3)
# 关闭当前浏览页
driver.close()
3、选择select:select元素不能直接点击。因为点击后还需要选中元素,因此selenium专门为select标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素当成参数传到这个类中,创建这个对象。以后就可以使用这个对象进行选择了。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name('jumpMenu'))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value('http://www.95yueba.com')
# 根据可是的文本选择
selectTag.select_by_visible_text('95秀客户端')
# 取消所有选项
selectTag.deselect_all()
4、操作按钮:操作按钮有很多种方式。比如单击、右击、双击等。常用的是点击。直接调用click函数就可以。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 4:59 PM
# 文件 :selenium操作按钮标签.py
# IDE :PyCharm# 导入webdriver 模块
from selenium import webdriver
# 导入Select模块
from selenium.webdriver.support.ui import Select
# 导入time模块
import time# 创建浏览器引擎
driver = webdriver.Chrome(executable_path='chromedriver')# 指定url
url = 'http://www.baidu.com'# 使用引擎打开网页
driver.get(url)# 通过ID查找input框
inputTag = driver.find_element_by_id('kw')
# 向input框发送python值
inputTag.send_keys('python')# 查找百度一下按钮
submitTag = driver.find_element_by_id('su')
# click()执行百度命令
submitTag.click()
# 关闭当前浏览器页面
driver.close()
行为链
所谓“行为链”就是一连串的操作动作。有时候在页面中的操作可能要有很多步,那么这时候可以使用鼠标行为链类ActionChains来完成。例如将鼠标移动到某个元素上并执行点击事件。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 5:34 PM
# 文件 :selenium操作行为链.py
# IDE :PyCharm# 导入模块
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'url = 'http://www.baidu.com/'# 创建driver
driver = webdriver.Chrome(executable_path=execute_path)
driver.get(url)# 找到input、百度一下标签
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')# 创建行为
actions = ActionChains(driver)
# 选中input框,然后输入'中国女足'
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag, '中国女足')
# 选中百度一下标签,然后单击
actions.move_to_element(submitTag)
actions.click(submitTag)
# 统一执行actions
actions.perform()time.sleep(13)
driver.close()
还有更多的鼠标相关操作
- click_and_hold(element):点击但不松开鼠标
- context_click(element):右键点击
- double_click(element):双击
更多方法参考:http://selenium-python.readthedocs.io/api.html
Cookie操作
1、获取所有的cookie
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 6:57 PM
# 文件 :selenium操作cookie.py
# IDE :PyCharm# 导入模块
from selenium import webdriver# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'# 创建driver
driver = webdriver.Chrome(executable_path=execute_path)# 指定url
url = 'https://www.baidu.com/'# 访问url
driver.get(url)for cookie in driver.get_cookies():print(cookie)driver.close()
程序运行结果如下:
{'domain': '.baidu.com', 'expiry': 1675940497, 'httpOnly': False, 'name': 'BAIDUID_BFESS', 'path': '/', 'sameSite': 'None', 'secure': True, 'value': '058DB780F413036AE207FA5D5DBDFD0D:FG=1'}
{'domain': '.baidu.com', 'expiry': 1644408097, 'httpOnly': False, 'name': 'BA_HECTOR', 'path': '/', 'secure': False, 'value': 'ac81212k8l8180e5ug1h077oi0q'}
{'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '35414_35104_31254_35488_34584_35491_35796_35316_26350_35765_35745'}
{'domain': '.baidu.com', 'expiry': 1675940496, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': '058DB780F413036AE207FA5D5DBDFD0D:FG=1'}
{'domain': '.baidu.com', 'expiry': 3791888143, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': '058DB780F413036A0DFEEB9DEAF54433'}
{'domain': '.baidu.com', 'expiry': 3791888143, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1644404497'}
{'domain': 'www.baidu.com', 'expiry': 1645268497, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '123253'}
{'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'}
Process finished with exit code 0
2、根据cookie的key获取cookie的value,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 6:57 PM
# 文件 :selenium操作cookie.py
# IDE :PyCharm# 导入模块
from selenium import webdriver# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'# 创建driver
driver = webdriver.Chrome(executable_path=execute_path)# 指定url
url = 'https://www.baidu.com/'# 访问url
driver.get(url)
# 通过某个key获取cookie的value
print(driver.get_cookie('PSTM'))
driver.close()
程序运行结果如下:
{'domain': '.baidu.com', 'expiry': 3791888742, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1644405096'}Process finished with exit code 0
3、删除所有的cookies,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 6:57 PM
# 文件 :selenium操作cookie.py
# IDE :PyCharm# 导入模块
from selenium import webdriver# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'# 创建driver
driver = webdriver.Chrome(executable_path=execute_path)# 指定url
url = 'https://www.baidu.com/'# 访问url
driver.get(url)
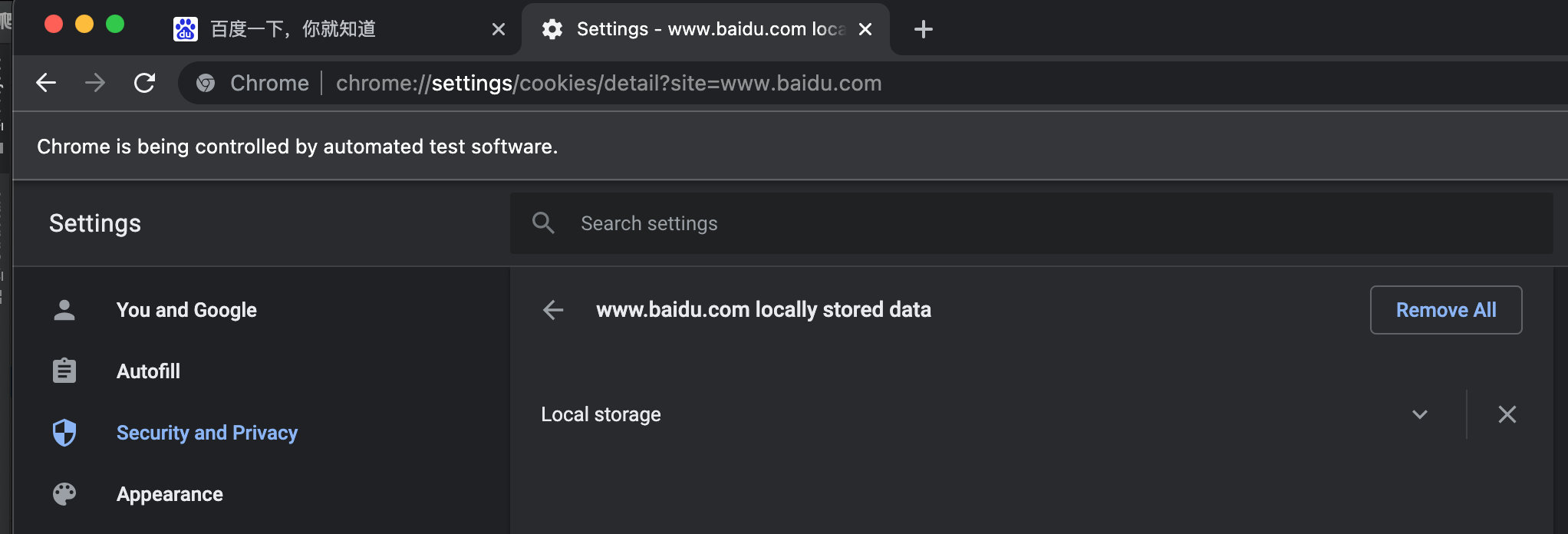
# 删除所有cookies
driver.delete_all_cookies()程序运行结果如下:
4、删除某个cookie,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 6:57 PM
# 文件 :selenium操作cookie.py
# IDE :PyCharm# 导入模块
from selenium import webdriver# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'# 创建driver
driver = webdriver.Chrome(executable_path=execute_path)# 指定url
url = 'https://www.baidu.com/'# 访问url
driver.get(url)for cookie in driver.get_cookies():print(cookie)# driver.close()# 根据cookie的key获取cookie值
# print(driver.get_cookie('PSTM'))# 删除指定的cookie
driver.delete_cookie('PSTM')
print(driver.get_cookie('PSTM'))
程序运行结果如下:
{'domain': '.baidu.com', 'expiry': 1644409502, 'httpOnly': False, 'name': 'BA_HECTOR', 'path': '/', 'secure': False, 'value': '2s04ag8l0g252g6k6o1h0794f0q'}
{'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '35105_31253_34584_35490_35246_35796_35315_26350_35724_35765_35746'}
{'domain': '.baidu.com', 'expiry': 1675941902, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': 'ACFC052478761063262775E7A2DE4C5F:FG=1'}
{'domain': '.baidu.com', 'expiry': 3791889549, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': 'ACFC052478761063DE9BEFA0F014E38F'}
# 没删除之前是存在的
{'domain': '.baidu.com', 'expiry': 3791889549, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1644405902'}
{'domain': 'www.baidu.com', 'expiry': 1645269902, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '123253'}
{'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'}
# 删除之后,返回结果None
NoneProcess finished with exit code 0
页面等待
现在网页很多采用了Ajax技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待时间过长导致某个dom元素还没加载,但是你的代码直接使用了这个WebElement,那么会报错NullPointer的异常。为了解决这个问题,selenium提供了两种等待方式:隐式等待,显示等待。
1.隐式等待:调用driver.implicitly_wait,那么在获取任何元素之前,会先等待10秒时间。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 8:25 PM
# 文件 :隐式等待.py
# IDE :PyCharm# 导入模块
from selenium import webdriver
# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'# 创建driver
driver = webdriver.Chrome(executable_path=execute_path)# 指定url
url = 'https://www.csdn.net/'driver.get(url)# 隐式等待10秒
driver.implicitly_wait(10)
# 随意指定一个id值
driver.find_element_by_id('dfsfasdfasfasfsfdsafds')
2.显式等待:显式等待是表明某个条件成立后才执行获取元素的操作。也可以在等待的时候指定一个最大的时间,如果超过这个时间那么就报异常错误。显式等待应该使用selenium.webdriver.support.excepted_conditions期望的条件和selenium.webdriver.support.ui.WebDriverWait来配合完成。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 8:30 PM
# 文件 :显式等待.py
# IDE :PyCharm# 导入模块
from selenium import webdriver
from selenium.webdriver.common.by import By
# 导入显式等待模块
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECheaders = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36','cookie':'uuid_tt_dd=10_20562014200-1642230088053-480005; __gads=ID=6d32e6ec1ea72d65-225f830cd5cf00dc:T=1642230106:RT=1642230106:S=ALNI_MZjtH_S6lcshDmkkDY4DQKIA1Ateg; ssxmod_itna=QqAxyD0DRD9G9ixl+D+rFOep8GfDc0AWOYPhx0HAeiODUxn4iaDToPTDGq+mR4YeSQm3BDQeYGYPGCijnRbiVb1YP5QbDneG0DQKGmzxGUFD7w+e2p=qDPDbxYPDGQqDbDY8tGwDY5HDGqDnDY=XD7Ug7AmWFMjgeudDCgmpli+zWi5oDOpxfi5IW8D=0DeI7i5K+A+zWc4qeowjSEFDGSTQ2iD=; ssxmod_itna2=QqAxyD0DRD9G9ixl+D+rFOep8GfDc0AWOYPxnK3xqqDsqDBQDjbPxx=MdidGYnBa2KYHl+iq7KwCb8uGrDgeC7owaD4m0DHDa7dIL3soD+I+02APk8wU977qxT8zGTNw63Xu1Mf=8QGDStRKPzTE+Df0p/+vBjRQszRPoMqf248fp03YujRGGUWjhzlUEIjrfAC2fzOYpG3dF1RfOaGDWD7jgD7=DeqxxD==; UserName=weixin_41905135; UserInfo=5d63720898c541cfa30ae44e4525ef44; UserToken=5d63720898c541cfa30ae44e4525ef44; UserNick=Bruce_Liuxiaowei; AU=E1F; UN=weixin_41905135; BT=1642230175210; p_uid=U110000; Hm_up_6bcd52f51e9b3dce32bec4a3997715ac={"islogin":{"value":"1","scope":1},"isonline":{"value":"1","scope":1},"isvip":{"value":"1","scope":1},"uid_":{"value":"weixin_41905135","scope":1}}; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_20562014200-1642230088053-480005!5744*1*weixin_41905135; c_dl_prid=1643325931307_582254; c_dl_rid=1644247742278_429472; c_dl_fref=https://blog.csdn.net/orange_xiang/article/details/82924296; c_dl_fpage=/download/weixin_38701952/12853345; c_dl_um=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-82924296.first_rank_v2_pc_rank_v29; dc_session_id=10_1644408299161.775025; dc_sid=8287d83a7595ae0d8779cb4fcedbe31a; csrfToken=Lb84yS2_Mi8haar-7oGjC4bZ; c_first_ref=default; c_first_page=https://www.csdn.net/; c_segment=5; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1644373995,1644395322,1644401531,1644409224; c_page_id=default; log_Id_click=364; c_pref=https://www.csdn.net/; c_ref=https://blog.csdn.net/weixin_41905135?spm=1000.2115.3001.5343; dc_tos=r71fd2; log_Id_pv=444; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1644410632; log_Id_view=722'
}
# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'# 创建driver
driver = webdriver.Chrome(executable_path=execute_path)# 指定url
url = 'https://www.csdn.net/'
driver.get(url)
try:element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'sousuo')) # 参数以元组形式传入)
finally:driver.quit()
3、一些其他等待条件
- presence_of_element_located:某个元素已经加载完毕
- presence_of_all_element_located:网页中所有满足条件的元素加载完毕
- element_to_be_cliable:某个元素可以点击了
切换页面
有时候窗口中有很多子tab页面。这时候需要切换页面的。selenium提供了一个叫做switch_to_window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/9/22 9:57 PM
# 文件 :切换页面.py
# IDE :PyCharm# 导入模块
from selenium import webdriver# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'# 指定url
url1 = 'https://www.douban.com/'
url2 = 'https://www.baidu.com/'
driver = webdriver.Chrome(executable_path=execute_path)driver.get(url1)
driver.execute_script("window.open('https://www.baidu.com/')")
程序运行结果如下图:
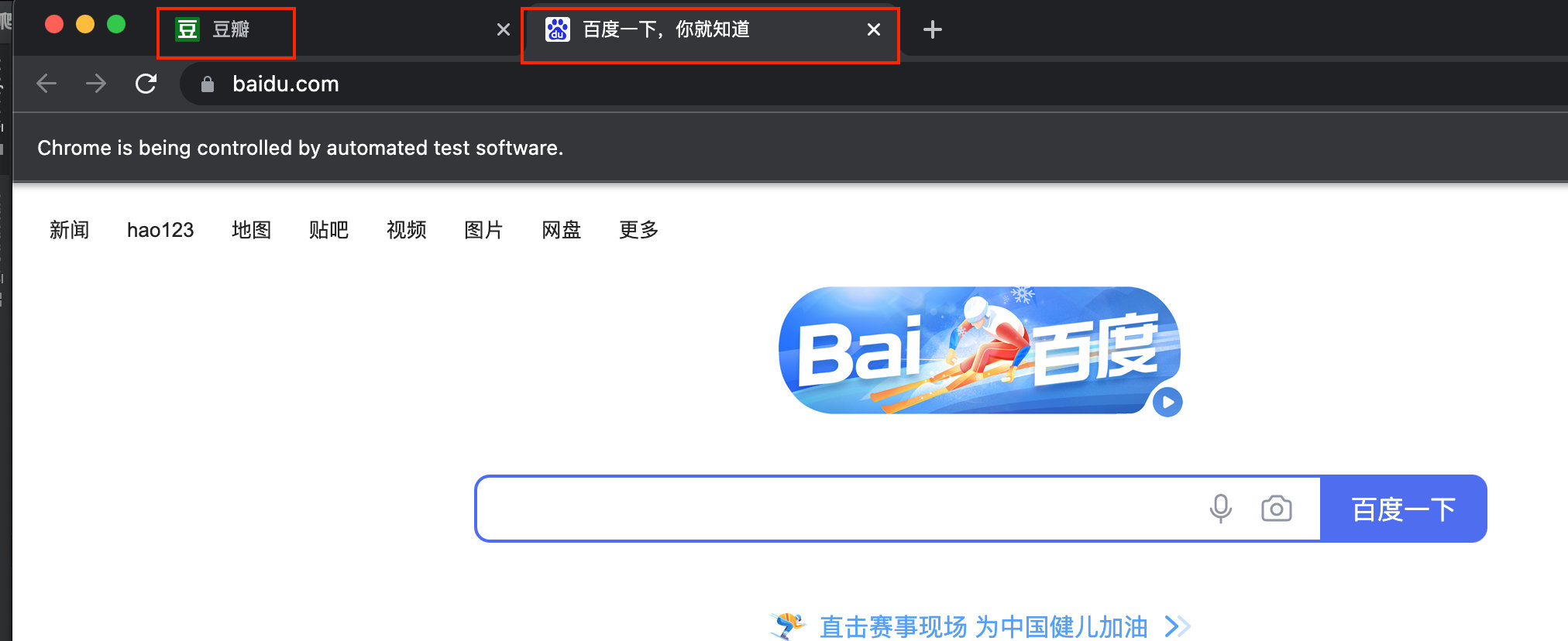
切换到指定窗口,代码如下:
# 从driver.window_handlers中取出具体的窗口,driver.window_handlers是一个列表,里面是窗口句柄
# 此案例只打开两个窗口,所以handles列表取‘1’
driver.switch_to_window(driver.window_handles[1])
设置代理ip
爬取网页的时候为避免被封掉ip地址,我们就会需要代理ip,随时更换ip地址。不同的浏览器有不同的实现方式,本文以Chrome浏览器为例。示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/10/22 9:57 AM
# 文件 :设置代理ip.py
# IDE :PyCharm# 导入模块
from selenium import webdriver# chromedriver路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'options = webdriver.ChromeOptions()
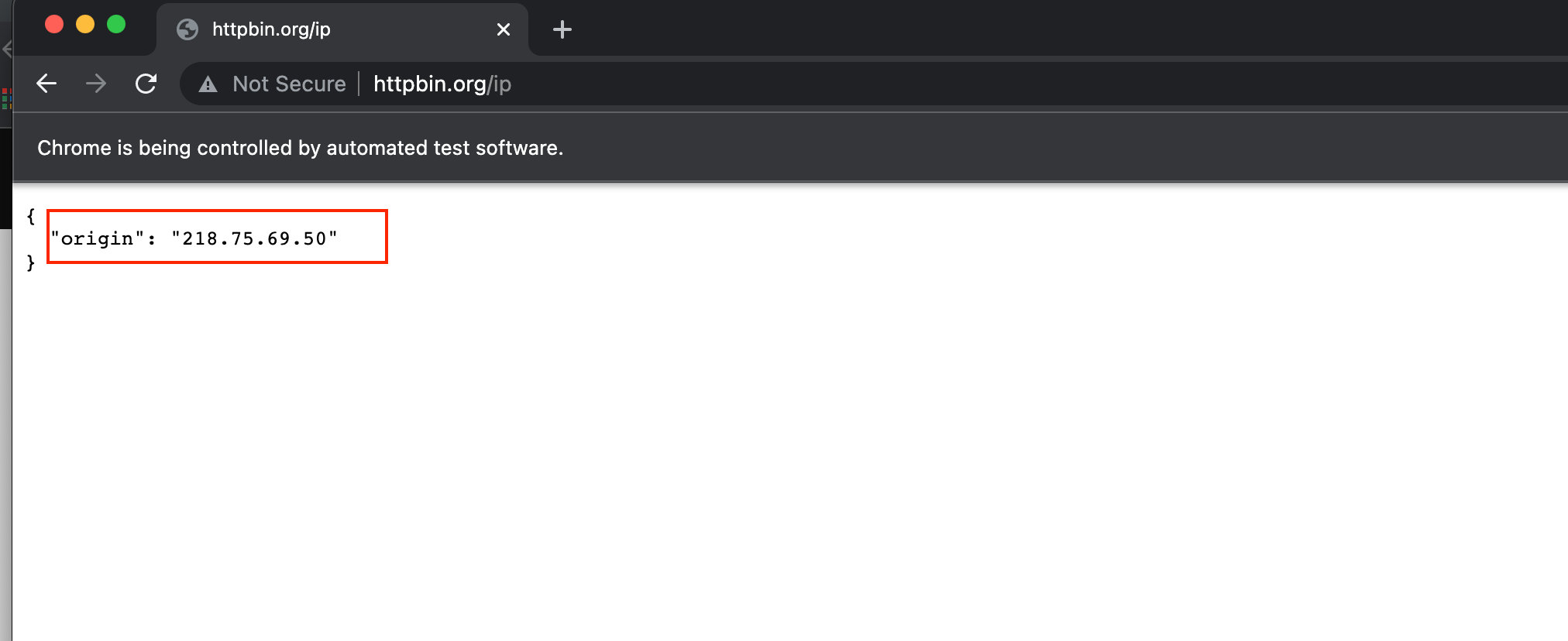
options.add_argument("--proxy-server=http://218.75.69.50:57903")driver = webdriver.Chrome(executable_path=execute_path, chrome_options=options)
driver.get('http://httpbin.org/ip')
程序运行结果如下图:
WebElement元素
从网页中获取网页元素,from selenium.webdriver.remote.webelement import WebElement 类是每个获取的元素的所属类。一些常用的属性如下:
1、get_attribute:获取标签某个属性值
2、screenshot:获取当前页面的截图,并保存为png格式,此方法只能在driver上使用。
示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/10/22 10:28 AM
# 文件 :获取网页元素.py
# IDE :PyCharm# 导入模块
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement# 指定浏览器驱动的路径
execute_path = '../使用selenium爬取动态加载的信息/chromedriver'
# 创建浏览器驱动
brower = webdriver.Chrome(executable_path=execute_path)# 指定url
url = 'http://www.baidu.com/'# 打开网页
brower.get(url)# 找到搜索按钮"百度一下"
baidu_Btn = brower.find_element_by_id('su')
print(type(baidu_Btn))
# 获取按钮属性value的值
print(baidu_Btn.get_attribute('value'))# 保存网页截图
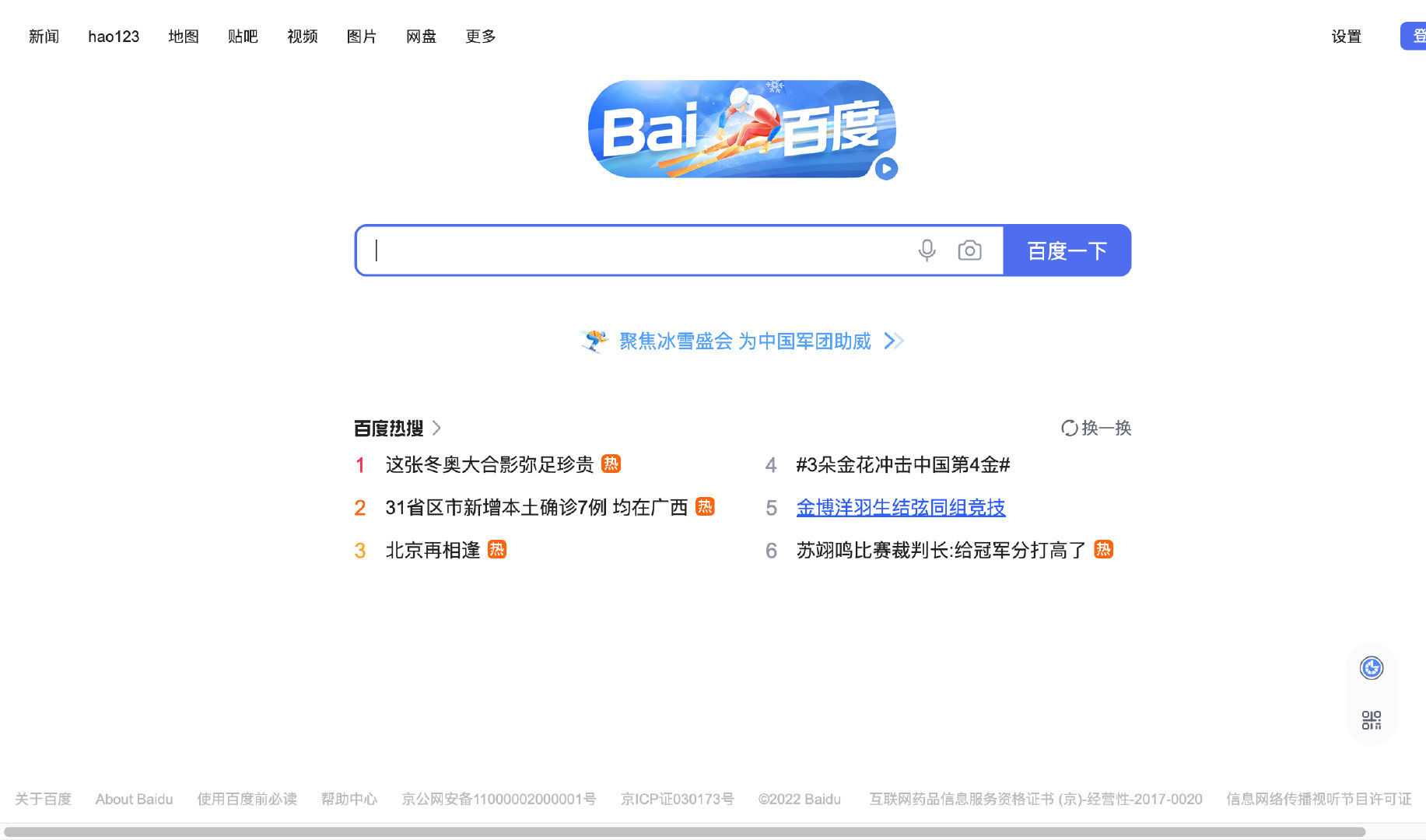
brower.save_screenshot('baidu.png')
运行结果如下: