文章目录
- [146. LRU 缓存机制](https://leetcode-cn.com/problems/lru-cache/)
- ACM模式
- LRU 在 MySQL 中的应用
- LRU 在 Redis 中的应用
- 面试官:来,手写一个线程安全并且可以设置过期时间的LRU缓存
146. LRU 缓存机制
力扣原题
class Node{public int key;public int value;public Node next;public Node pre;public Node(int key,int value){this.key=key;this.value=value;}
}class DoubleList{private Node head, tail;private int size;public int size(){return size;}public DoubleList( ){head=new Node(0,0);tail=new Node(0,0);head.next=tail;tail.pre=head;size=0;}//删除public void delete(Node x){x.pre.next=x.next;x.next.pre=x.pre;size--;}//删除头部元素并返回public Node deleteFirst(){if(head.next==null){return null;}Node tem=head.next;head.next=tem.next;tem.next.pre=head;size--;return tem;}//尾部添加public void addLast(Node x){tail.pre.next=x;x.pre=tail.pre;x.next=tail;tail.pre=x;size++;}}class LRUCache {private HashMap<Integer,Node> map;private DoubleList doubleList;private int capacity;public LRUCache(int capacity) {this.capacity=capacity;map=new HashMap<>();doubleList=new DoubleList();}public int get(int key) {//先判断是否存在if(!map.containsKey(key)){return -1;}//key设置为最近使用的,先删除,再添加到链表尾部Node x=map.get(key);doubleList.delete(x);doubleList.addLast(x);return map.get(key).value;}public void put(int key, int value) {//先判断是否存在if(map.containsKey(key)){Node x=map.get(key);doubleList.delete(x);Node y=new Node(key,value);doubleList.addLast(y);map.put(key,y);return;}if(doubleList.size()==capacity){//删除链表头节点Node y=doubleList.deleteFirst();map.remove(y.key);}Node z=new Node(key,value);doubleList.addLast(z);map.put(key,z);}
}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/
ACM模式
import java.util.HashMap;public class LRUCache {/** Least Recent Used* 淘汰掉最不经常使用的* 使用HashMap + 双链表,实现CRUD时间复杂度为O(1)*//** 使用内部类定义一个双链表* 至于为什么是这四个成员变量呢?* LRU最大的特点,就是一个双链表的节点,同时也是HashMap的value* 那么HashMap的key从哪里来呢?* 没错,HashMap中的key和双链表节点中的key是同一个东西。* 这样说起来好像很奇怪,很啰嗦,很不优雅。然而最好,甚至必须这样做。解释如下:* 想象两个情形:* 1. 只在双链表中存value。那么——* 我们要弹出双链表最后一个元素,需要在双链表和HashMap中进行两次删除操作。* 但在HashMap中的删除操作,要借助双链表中的信息。* 废话,因为只有双链表知道谁是“最不常使用的元素”啊。* 而如果双链表中没有key,那岂不是没法在HashMap中以O(1)时间找到这个元素。* 2. 只在双链表中存key。那么——* 请问你value打算放哪里?你仿佛在搞笑哦。= =*/class DLinkedNode {int key;int value;DLinkedNode pre;DLinkedNode next;}/** 这里是成员变量,private可以去掉,没什么影响* 重要的事情再说一遍:* LRU最大的特点,就是一个双链表的节点,同时也是HashMap的value* cnt is short for count,就是目前的元素数量,作为判断。* cap is short for capacity,就是最大容量* hh和tt,是head和tail的卖萌版。虚拟头结点和尾节点。* 此时,他们是LRU数据结构的成员变量。*/private HashMap<Integer, DLinkedNode> h = new HashMap<>();private int cnt;private int cap;private DLinkedNode hh, tt;/** 初始化,没什么好讲的。*/public LRUCache(int cap) {this.cnt = 0;this.cap = cap;hh = new DLinkedNode();tt = new DLinkedNode();hh.pre = null;tt.next = null;hh.next = tt;tt.pre = hh;}/** 在某一元素被访问到的时候,先调用这个toHead()方法.* 这样,链表中从前到后的顺序,刚好就是被访问到的顺序。* 很幸运,对链表当中顺序的改动,并不影响HashMap。* 因为,改变链表的顺序,只需要改变它的前后指向,* 而不需要变动它自身的内存地址。* 何况,链表本身在内存中的存储也并不是一块连续的空间。* 这个方法本身的实现很简单:* 先让这个节点跟它的前后节点断开,然后头插。*/private void toHead(DLinkedNode node) {node.pre.next = node.next;node.next.pre = node.pre;this.push(node);}/** 头插,不解释~*/private void push(DLinkedNode node) {node.pre = this.hh;node.next = this.hh.next;this.hh.next.pre = node;this.hh.next = node;}/** 很不幸,优先级最低的节点要说再见了。* 那篇点击量最高的文章,拜托,你都没有维护链表诶!* 虽然你那样也可以运行。哈哈~*/private void popTail() {DLinkedNode tmp = tt.pre;tmp.pre.next = tt;tt.pre = tmp.pre;h.remove(tmp.key);tmp = null;}/** 通过Key获取元素,同时把这个被访问的元素设为表头的元素。* 刚刚被访问,优先级自然是最高。* 如果元素不存在,返回-1。*/public int get(int key) {DLinkedNode tmp = h.get(key);if (tmp == null) return -1;this.toHead(tmp);return tmp.value;}/** 这里就是最重要的set()方法,即“创建或修改”操作。* 一般的题目,就是要求set()和get()方法。* 也只有这个方法中,包含了缓存的容量这一参数。* 虽然前面看似是铺垫,但个人认为,前面的操作才是核心思想。* 前面的弄懂了,这里自然懂。* 实现起来也没难度,只要理顺逻辑就好。* 千万别把else写到里面那层代码里去。* 更不要自作聪明,把对cnt的操作放在前面的函数里面,把自己绕进去了。*/public void set(int key, int value) {DLinkedNode tmp = h.get(key);if (tmp == null) {tmp = new DLinkedNode();tmp.key = key;tmp.value = value;this.h.put(key, tmp);this.push(tmp);cnt ++ ;if (cnt > cap) {this.popTail();cnt -- ;}} else {tmp.value = value;this.toHead(tmp);}}/** 测试一下,输出3 2 -1。成功!*/public static void main(String[] args) {LRUCache lruCache = new LRUCache(3);lruCache.set(1, 2);lruCache.set(2, 3);lruCache.set(3, 4);System.out.println(lruCache.get(2));lruCache.set(2, 2);lruCache.set(4, 5);System.out.println(lruCache.get(2));System.out.println(lruCache.get(1));}}————————————————
版权声明:本文为CSDN博主「爆锤胖头鱼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/CSDNSJTU/article/details/105872082
https://blog.csdn.net/kexuanxiu1163/article/details/111877904
那么请问:为什么这里要用双链表呢,单链表为什么不行?
需要删除操作。删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。
哈希表里面已经保存了 key ,那么链表中为什么还要存储 key 和 value 呢,只存入 value 不就行了?
当缓存容量已满,我们不仅仅要删除最后一个 Node 节点,还要把 map 中映射到该节点的 key 同时删除,而这个 key 只能由 Node 得到。如果 Node 结构中只存储 val,那么我们就无法得知 key 是什么,就无法删除 map 中的键
LRU 在 MySQL 中的应用
面试官:LRU 在 MySQL 中的应用?
LRU 在 MySQL 的应用就是 Buffer Pool,也就是缓冲池。它的目的是为了减少磁盘 IO。
缓冲池是一块连续的内存,默认大小 128M,可以进行修改。这一块连续的内存,被划分为若干默认大小为 16KB 的页。
写buffer pool的时候发现没有空闲页了,就要从Buffer pool中淘汰数据也,就根据LRU链表的数据来
InnoDB的数据页不是都是在访问的时候才缓存到BP里的,而是有一个预读机制,也就是访问某个page的数据的时候,相邻的一些page可能会很快被访问到,所以先把这些page放到BP中缓存起来。
这种预读机制又分为两种类型:一个是线程预读,InnoDB把64个相邻的page叫做一个extent(区)。如果顺序地访问了一个extent的56个page,这时候InnoDB会把这个extent缓存到BP中。第二种叫随机预读,如果BP中已经缓存的数据页个数超过13时,就会把这个extent剩余的所有page都缓存到BP中。很明显,预读把可能即将用到的数据提前加载到BP中,肯定能提升IO的性能。
但是预读也会带来一些副作用,就是导致占用的内存空间更多,剩余空闲页更少,甚至会将真正需要被缓存的热点数据挤出BP,下次访问又要去磁盘IO。那如何让热点数据不收到预读的数据的影响呢?
InnoDB将 LRU list分成两部分,靠近head的叫做new sublist,用来存放热数据,靠近tail的叫做old sublist,用来存放冷数据。中间的分割线叫做midpoint,也就是对buffer pool做一个冷热分离。
工作时,所有新数据假如到BP的时候,一律先放到冷数据区的head,所以如果有一些预读的数据没有被用到会在冷区直接被淘汰。放到LRUlist以后,如果再次被访问,都把它移动到热去的head。
如果热区的数据长时间没有被访问,会被先移动到冷区的head部,最后在tail被淘汰。

为了避免并发的问题,对LRU链表的操作是要加锁的。也就是每一次链表的移动,都会带来资源的竞争和等待,因此要提高效率,就要尽量减少LRU链表的移动。比如把热区非常靠近head的page移动到head。所以还有一个优化,如果一个缓存页处于热数据区,且在热数据区的前1/4,那么当访问这个页的时候,就不再将其移动到热数据区的头部。如果缓存页处于热区的后3/4,那么当访问这个页的时候,会将其移动到热区的头部。
————————————————
版权声明:本文为CSDN博主「纵横千里,捭阖四方」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xueyushenzhou/article/details/115531869
还有一个场景是全表扫描的 sql,有可能直接把整个缓冲池里面的缓冲页都换了一遍,影响其他查询语句在缓冲池的命中率。
那么怎么处理这种场景呢?
把 LRU 链表分为两截,一截里面放的是热数据,一截里面放的是冷数据。
LRU 在 Redis 中的应用
Redis 没有使用真实的 LRU 算法的原因是因为这会消耗更多的内存。
Redis 对 LRU 算法进行了改进,增加了淘汰池。通过采样一小部分键,然后在采样键中回收最适合的那个。修改下面这个参数的配置,改变采样点数量,调整算法的精度。
maxmemory-samples 5
数据库中有 3000w 的数据,而 Redis 中只有 100w 数据,如何保证 Redis 中存放的都是热点数据?
先指定淘汰策略为 allkeys-lru 或者 volatile-lru,然后再计算一下 100w 数据大概占用多少内存,根据算出来的内存,限定 Redis 占用的内存。接下来的,就交给 Redis 的淘汰策略了。









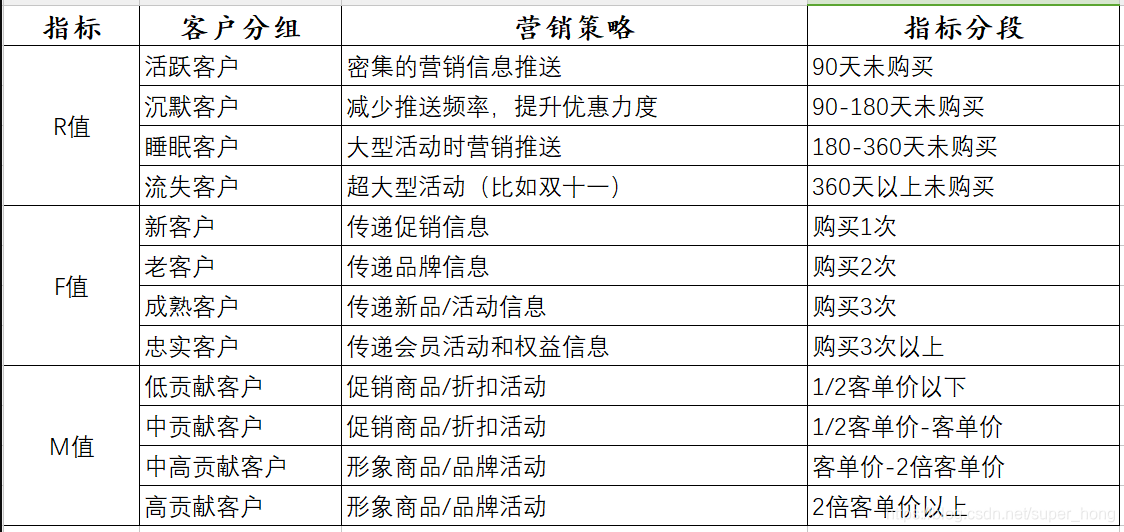

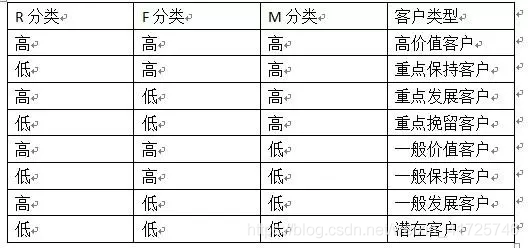


![[数据分析] RFM分析方法](https://img-blog.csdnimg.cn/4afccd29631649ee96f6f08818292452.png)