1、mysql的like具有局限性
# 体现在功能不全,性能低。不适用于全文搜索(日志或简历中搜索字段)、没有相关性搜索排名等等
select name from goods WHERE name LIKE "%苹果%"
2、试试elasticsearch 搜索
1、解决mysql like 的短板
2、它是分布式的

1)安装es和kibana
1、通过kibana 操作 es
2、通过docker安装elasticsearch,kibana
kibana安装时候的命令中 kibana的版本号要和es一致
3、安装好后就可以通过ip:port 访问 kibana
2) es 基本概念
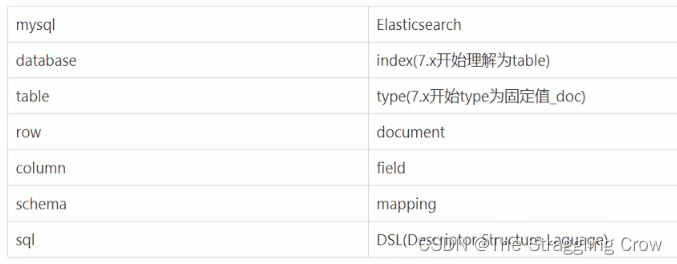
1、7.x以后index 开始理解为table, type这个概念马上取消掉了,不管他就行了
2、schema 就是比如定义列的最大长度是什么类型,es里面叫它映射 mapping
3、索引一个数据就是mysql中的insert一个数据,把数据放进索引,就是mysql里的放进table
所以,索引有两个含义:动词(insert),名词(table)
4、操作起来就是resfulAPI,http的,1)添加数据用PUT 或者 POST (需要自己指定id,POST会自动生成id,PUT同样一条命令是更新,而POST同样一条命令,会再增加一行数据)2)获取数据GET 获取某一个数据 GET user/_source/13)搜索数据GET _search?q=xiaomingGET user/_search?q=xiaoming4) 通过request body查询index中所有GET user/_search{"query":{"match_all":{}}5)注意update数据用这种方式,POST user/_update/1{"doc":{"age":18}}不这样写容易覆盖6) DELETE /usr/_doc/2 # 删除一条#删除indexDELETE user7)批量操作数据(bulk), 批量获取(mget)3)es全文查询
# 对于es来说 from和 size分页在数据量比较小的情况下可行,太大的话要用scroll
GET user/_search
{"query":{"match_all":{}},"from":4,"size":4
}query里面的查用到
复合查询,全文查询,术语查询
比如:搜住址里面的街道,注意大小写不敏感
模糊查询/匹配查询 match
match_phrase 精确查询 / 短语查询
1、我要搜Madison stree,结果必须两个分词都有,而且按顺序连着的
multi_match 查询
比如搜resume的时候,希望搜出来go语言的,但是不希望它出现want_learn那栏里的
这样搜索的时候指定title 和 desc里面出现的go语言
"multi_match":{"query":"go","fields":["title^2","desc"]}title^2 代表title里面查询出来的go权重高
query_string
"query_string":{"default_field":"address","query":"Madison OR street"
}
OR可以换成AND
4)term查询
1、term是不会分词的
小写+分词就是analyzer
存入倒排索引的时候会把大写全部改成小写,所以这时候term查Street就查不到
查street有
那为什么match能搜到呢?因为它在查询数据的时候也是和写入数据同样,
先分词,然后变成小写
2、term是原子查询,就是你写的是什么,它就搜什么
也正因此,如果你搜全是小写"madison street"还是搜不到,因为在倒排索引里
都已经分词了,没有原装的这两词
2> range查询
"range":{"age":{"gte":10, #大于等于 没有e就是没有等于"lte":20, #小于等于"boost":2.0 # 权重}
}
3> exists查询
# 查询出所有有age的数据
"exists":{"field":"age"
}
4> fuzzy 模糊查询
就是你搜golanl 搜索引擎也能知道你要搜 golang
"fuzzy":{"address":"streat"
}
依旧能搜索出来street,因为street和streat的编辑距离是1,很短
match也能做模糊查询
"match":{"address":{"query":"Midison","fuzziness":1 # 1表示开启模糊查询}
}
而直接用fuzzy不会进行分词
5)复合查询
就是用bool将其他查询语言拼凑起来
must表示里面的查询语句必须满足,和filter差不多,但是满足后会加分
should是满足与否无所谓,和不写的区别就是满足的话得分会高一些
must_not
filter 过滤,必须匹配
6)倒排索引
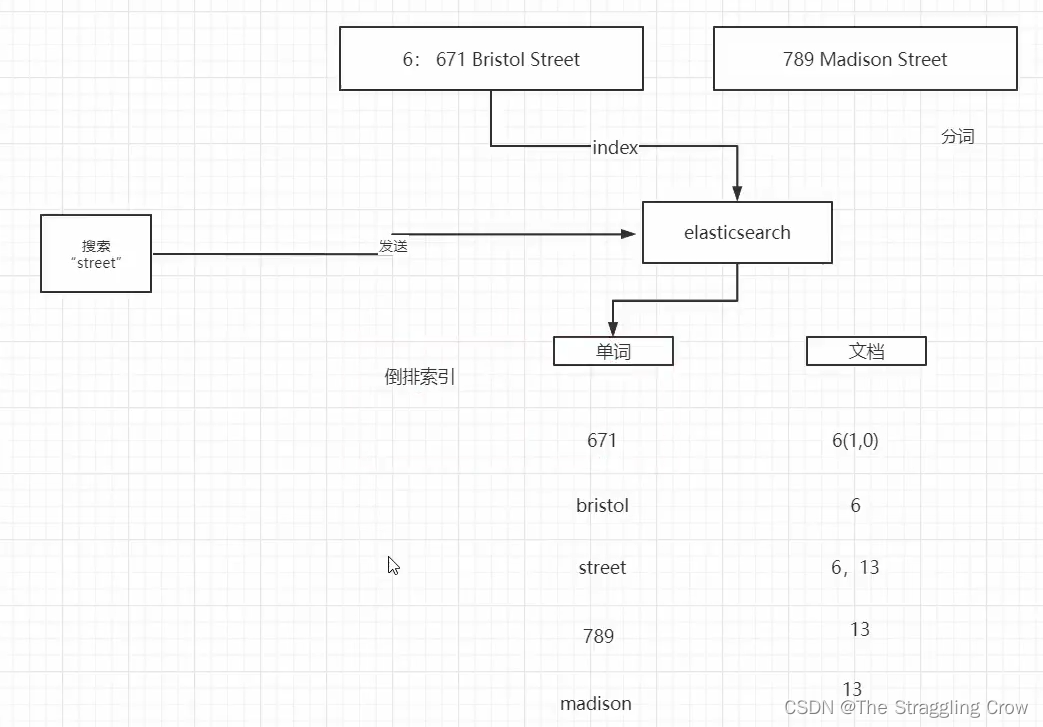
1、es底层存储数据使用的是倒排索引
2、英文的分词很简单,就是通过空格,并且都改成小写,防止后面搜索不到
3、6(1,0)分别代表 671出现在6号文档,出现过一次,在第0位
4、查询的时候,比如查Madison street,如果两个分词都符合得分最高,只符合一个的也会搜出来
5、写入和查询数据的时候都会分词
7)es Analyzer
1、写入数据----> es --analyzer–> 倒排索引
写入和搜索的时候都可以指定analyzer,search_analyzer
2、analyzer就是分词+大写变小写

3、搜索策略
如果写入和查询的时候你指明了analyzer,它们是互不影响的,否则按下图走

8)中文分词
1、词典匹配,比如词典里有没有中华牙膏,
2、基于统计
3、基于深度学习

4、用 IK 分词器
IK要和es的版本对应起来
直接将IK 放到es的外部挂载目录plugins里就行了
分词器之前就要设置好,否则后面不好改,因为之前的都是用原来的分词器分的,这部分数据怎么办?
5、扩展词库
将自己的专有名词加到词库中
在ik/config/ 下建自己的文件夹,里面建自己的mydic.dic 里面填入词汇,在 extra_stopword.dic中加入停用词
进入config vim IKAnalyzer.cfg.xml 将自己的加进去,使其生效
docker restart 容器id