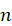转载:https://blog.csdn.net/Sun7_She/article/details/40344329
AI-3的80~84不懂
A*算法不懂
引言:
什么是搜索:
根据问题的实际情况不断寻找可利用的知识,构造出一条代价较少的推理路线,使问题得到圆满的解决的过程称为搜索。
包括两个方面:
——找到从初始事实到问题最终答案的一条推理路径
——找到的这条路径在时间和空间上复杂度最小
搜索分两大类:
盲目搜索:也称无信息搜索,即只按预定的控制策略进行搜索,在搜索过程中获得的中间信息不用来改进控制策略。
启发式搜索:在搜索中加入了与问题有关的启发性信息,用于指导搜索朝着最有希望的方向进行,加速问题的求结果称并找到最优解。
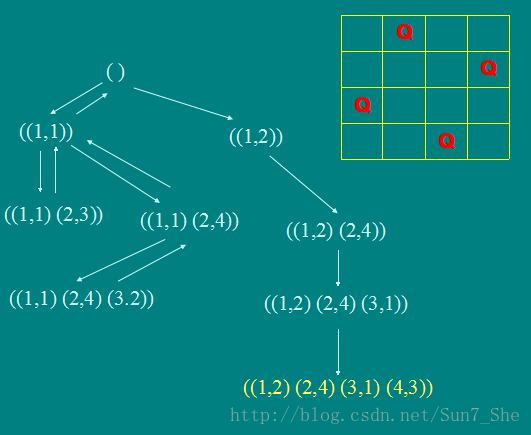
回溯问题——皇后问题
存在问题:深度问题、死循环问题
解决办法:对搜索深度加以限制、记录从初始状态到当前状态的路径
图搜索策略:
在对问题的状态空间进行搜索时:
回溯搜索:只保留从初始状态到当前状态的一条路径
图搜索:保留所有已经搜索过的路径
一些基本概念:
节点深度——根节点深度=0
其他节点深度=父节点深度+1
路径:设一节点序列为(n0, n1,…,nk),对于i=1,…,k,若节点ni-1具有一个后继节点ni,则该序列称为从n0到nk的路径。
路径的耗散值:一条路径的耗散值等于连接这条路径各节点间所有耗散值的总和。用C(ni, nj)表示从ni到nj的路径的耗散值。
扩展一个节点:生成出该节点的所有后继节点,并给出它们之间的耗散值,这一过程称为“扩展一个节点”。
无信息图搜索过程:
深度优先搜索、宽度优先搜索
深度优先搜索的性质:
一般不能保证找到最优解
当深度限制不合理时,可能找不到解,可以将算法改为可变深度限制
最坏情况时,搜索空间等同于穷举
与回溯法的差别:图搜索
是一个通用的与问题无关的方法
时间复杂度O(bm): 如果 m 比b大很多则比较严重
空间复杂度O(bm), 线性空间
缺点:如果目标节点不在搜索所进入的分支上,而该分支又是一个无穷分支,则就得不到解.因此该算法是不完备的
优点:如果目标节点恰好在搜索所进入的分支上,则可以较快地得到解
宽度优先搜索性质:
当问题有解时,一定能找到解
当问题为单位耗散值,且问题有解时,一定能找到最优解
方法与问题无关,具有通用性
效率较低
属于图搜索方法
时间复杂度1+b+b2+b3+… +bd + b(bd-1) = O(bd+1)
空间复杂度O(bd+1)————空间是大问题(和时间相比)
缺点:当目标节点距离初始节点较远时会产生许多无用的节点,搜索效率低
优点:只要问题有解,则总可以得到解,是完备的,而且是最短路径的解
回溯与宽度优先方法的结合:
目的:解决宽度优先方法的空间问题和回溯方法不能找到最优解的问题。
思想:首先给回溯法一个比较小的深度限制,然后逐渐增加深度限制,直到找到解或找遍所有分支为止。
时间和空间复杂度:
一字棋的棋局数:9!=105
跳棋的棋局数:大约1078
国际象棋的棋局数:大约10120
围棋的棋局数:大约10761
搜索速度10-100年/步
搜索一遍国际象棋的时间是1016年(一亿亿年),宇宙的寿命100亿年.
启发式图搜索:
利用知识来引导搜索,达到减少搜索范围,降低问题复杂度的目的
启发信息的强度——强:降低搜索工作量,但可能导致找不到最优解
弱:一般导致工作量加大,极限情况下变为盲目搜索,但可能找到最优解
希望:
引入启发知识,在保证找到最佳解的情况下,尽可能减少搜索范围,提高搜索效率
路径的耗散值和求取路径所需搜索的耗散值二者的组合最小
基本思想:
定义一个评价函数f,对当前的搜索状态进行评估,找出一个最有希望的节点来扩展
启发式搜索算法A(A算法)
1、A算法与A*算法定义
或图通用算法在采用如下形式的估计函数时, 称为A算法。
f(n)=g(n)+h(n)
其中g(n)表示从s到n点费用的估计,因为n为当前节点,搜索已达到n点,所以g(n)可计算出。h(n)表示从n到g接近程度的估计,因为尚未找到解路径,所以h(n)仅仅是估计值。
符号意义:
g(n):从S到n的最短路径的耗散值
h(n):从n到g的最短路径的耗散值
f(n)=g(n)+h(n):从s经过n到g的最短路径的耗散值
g*(n)、h*(n)、f*(n)分别是g(n)、h(n)、f(n)的估计值
算法特例:
1、若令 h(n)≡0,则A算法相当于宽度优先搜索,因为上一层节点的搜索费用一般比下一层的小。
2、g(n)≡h(n)≡0,则相当于随机算法。
3、g(n)≡0,则相当于最佳优先搜索算法。
4、特别是当要求 h(n)≤h*(n),
就称为这种A算法为A*算法。
A算法举例:
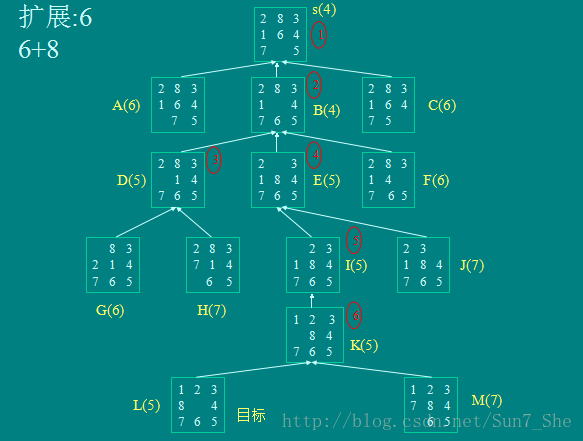
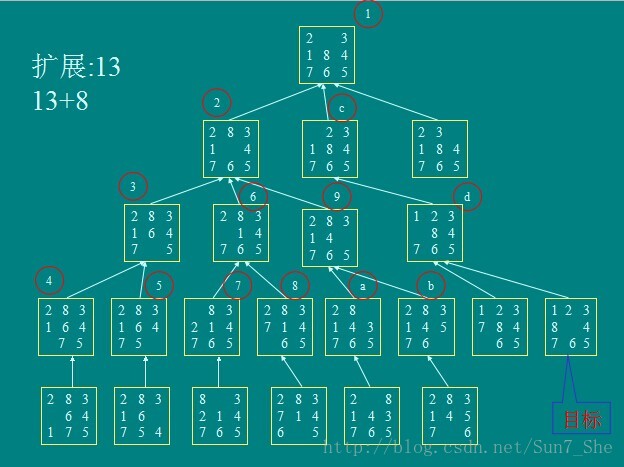
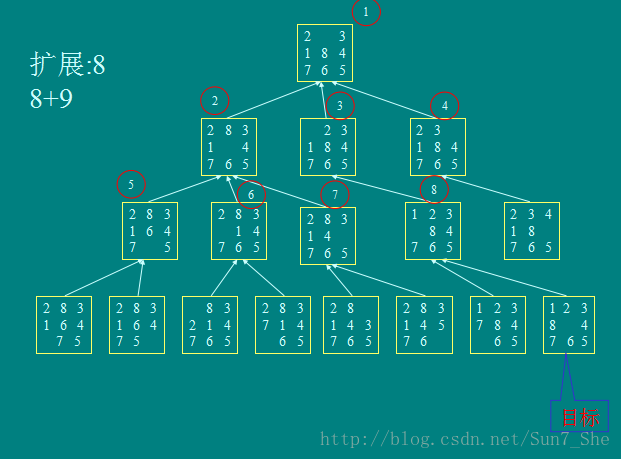
同一问题三种不同方法的比较:
深度优先
扩展次数:13 未扩展结点 8 搜索树中的结点21
宽度优先
扩展次数:8 未扩展结点 9 搜索树中的结点17
启发式搜索
扩展次数:6 未扩展结点 8 搜索树中的结点14
A*算法:
在A算法中,如果满足条件: (1) g(n)是对g*(n)的估计 g(n)>0 (2) h(n)≤h*(n) , 则A算法称为A*算法。
迭代加深A*
基本思想:回溯与A*的结合
其他搜索算法:
1、爬山法(局部搜索算法)
2、分枝定界法
3、动态规划法:如果对于任何n,当h(n)=0时,A*算法就成为了动态规划算法
算法描述:通过删除多余后继节点大大减少了搜索空间,从而降低了搜索费用。
删除了四个节点,从而减少了8个节点的扩展生成。
4、分支界限法:分支界限法是优先扩展当前具有最小耗散值分支路径的端节点;评价函数:f(n)=g(n)