教你创建一个免费的代理IP池(txt存储版本)
很多人可能会为爬虫被ban,IP被封等反爬机制苦恼,接下来我就教给大家如何白嫖做一个代理IP池。
准备工作
首先是准备工作,因为是第一个版本,因此我打算先用txt存储爬取到的ip,下面是用到的一些变量。
# UA池
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60','Opera/8.0 (Windows NT 5.1; U; en)','Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0','Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11','Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0) ',]# 写入所有代理
proxyList = open('proxy.txt')
# 写入可用代理ip
validList= open('valid.txt')# 控制线程
lock = threading.Lock()
获取所有代理IP地址
肯定免费代理IP有很多是不能用的,但是我们依然需要获取到所有的代理IP,再做下一步的筛选。
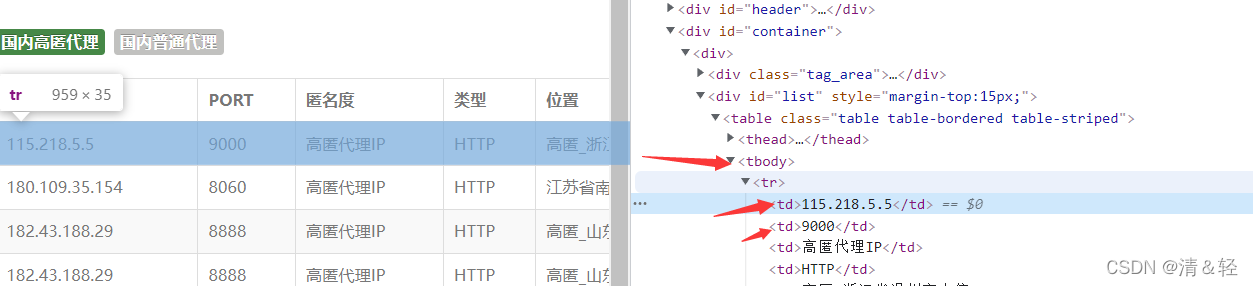
本次作者选择了云代理,快代理,98代理三个网站的免费代理IP,进行了爬取,代码见下:
def getProxy():starttime = time.time()# 爬取云代理ip# http://www.ip3366.net/freegetCloudProxy()# 爬取98代理# https: // www.89ip.cn / index_10.htmlget89Proxy()# 爬取快代理# https://www.kuaidaili.com/free/inha/1/# https://www.kuaidaili.com/free/intr/1/getQuickProxy()endtime = time.time()print(f"爬取代理花费{endtime-starttime}s")def getCloudProxy():print("爬取云代理IP中--------")num = 0import time# 打开我们创建的txt文件proxyFile = open('proxy.txt', 'a')for page in range(1, 8):for stype in range(1, 3):time.sleep(random.randint(1, 3))print(f"正在抓取{stype}的第{page}页数据")# 数据地址url = f'http://www.ip3366.net/free/?stype={stype}&page={page}'# 设置随机请求头headers = {'User-Agent': random.choice(user_agents)}# 发送请求response = requests.get(url=url, headers=headers)# 自适应编码response.encoding = response.apparent_encodinghtml_data = response.text# 解析数据selector = parsel.Selector(html_data)trs = selector.xpath('//table/tbody/tr')for tr in trs:ip = tr.xpath('./td[1]/text()').get() # ipport = tr.xpath('./td[2]/text()').get() # 端口protocol = tr.xpath('./td[4]/text()').get() # 协议# 将获取到的数据按照规定格式写入txt文本中1proxyFile.write('%s|%s|%s\n' % (ip, port, protocol))num += 1print(f"爬取云代理IP{num}条")def getQuickProxy():print("爬取快代理中------")num = 0import time# 打开我们创建的txt文件proxyFile = open('proxy.txt', 'a')for page in range(1, 3):for type in ['inha', 'intr']:time.sleep(random.randint(1, 3))print(f"正在抓取类型{type}第{page}页数据")# 数据地址url = f'https://www.kuaidaili.com/free/{type}/{page}/'# 设置随机请求头headers = {'User-Agent': random.choice(user_agents)}# 发送请求response = requests.get(url=url, headers=headers)# 自适应编码response.encoding = response.apparent_encodinghtml_data = response.text# 解析数据selector = parsel.Selector(html_data)trs = selector.xpath('//table/tbody/tr')for tr in trs:ip = tr.xpath('./td[1]/text()').get().strip() # ipport = tr.xpath('./td[2]/text()').get().strip() # 端口protocol = tr.xpath('./td[4]/text()').get().strip() #协议# 将获取到的数据按照规定格式写入txt文本中1proxyFile.write('%s|%s|%s\n' % (ip, port, protocol))num += 1print(f"爬取快代理IP{num}条")def get89Proxy():print("爬取89代理IP中--------")num = 0import time# 打开我们创建的txt文件proxyFile = open('proxy.txt', 'a')for page in range(1, 156):time.sleep(random.randint(1, 3))print(f"正在抓取第{page}页数据")# 数据地址url = f'https://www.89ip.cn/index_{page}.html'# 设置随机请求头headers = {'User-Agent': random.choice(user_agents)}# 发送请求response = requests.get(url=url, headers=headers)# 自适应编码response.encoding = response.apparent_encodinghtml_data = response.text# 解析数据selector = parsel.Selector(html_data)trs = selector.xpath('//table/tbody/tr')for tr in trs:ip = tr.xpath('./td[1]/text()').get().strip() # ipport = tr.xpath('./td[2]/text()').get().strip() # 端口protocol = 'HTTP' # 默认协议HTTP# 将获取到的数据按照规定格式写入txt文本中1proxyFile.write('%s|%s|%s\n' % (ip, port, protocol))num += 1print(f"爬取89代理IP{num}条")
验证ip有效性
对于获得的所有免费代理IP,对他们进行验证,方法就是使用requests对百度网站进行访问,如何得到的返回码code为200,说明访问成功,即为可用有效IP,代码见下:
def verifyProxyList():'''验证ip有效性并存入valid.txt:return:'''valid = open('valid.txt', 'a')while True:lock.acquire()# 读取存放ip的文件ipinfo = proxyList.readline().strip()lock.release()# 读到最后一行if len(ipinfo) == 0:breakline = ipinfo.strip().split('|')ip = line[0]port = line[1]realip = ip + ':' + port# print(realip)# 得到验证码code = verifyProxy(realip)# 验证通过if code == 200:lock.acquire()print("---Success:" + ip + ":" + port)valid.write(ipinfo + "\n")lock.release()else:pass# print("---Failure:" + ip + ":" + port)
def verifyProxy(ip):'''验证代理的有效性'''# 设置随机请求头headers = {'User-Agent': random.choice(user_agents)}url = "http://www.baidu.com"# 填写代理地址proxy = {'http': ip}try:code = requests.get(url=url, proxies=proxy, timeout=2, headers = headers).status_codeprint(code)return codeexcept Exception as e:return e测试有效IP
最后当然是测试板块啦,使用我们的有效代理IP池对目标网站进行访问,得到网站的内容,但是免费代理IP时效很短,需要控制好获取IP和使用IP的时间间隔,代码见下:
def useProxy():lock.acquire()ips = []# 获取可用ip池# 获取IP列表valid = open('/Users/shangyuhu/PycharmProjects/recruitProject/ProxyIP/valid.txt')while True:# 读取存放ip的文件ipinfo = valid.readline().strip()# 读到最后一行if len(ipinfo) == 0:breakline = ipinfo.strip().split('|')ip = line[0]port = line[1]realip = ip + ':' + portips.append(realip)print(ips)# 要抓取的目标网站地址targetUrl = "https://news.qq.com/"for i in range(10):# 随机使用ip爬虫proxyip = random.choice(ips)# print(proxyip)try:response = requests.get(url=targetUrl, proxies={"http": proxyip, "https": proxyip},verify=False, timeout=15)except Exception as e:continue# 自适应编码response.encoding = response.apparent_encodinghtml_data = response.textprint(html_data)# 用完了lock.release()
函数调用
if __name__ == '__main__':# 清空代理列表和有效代理列表proxy = open('proxy.txt', 'w')proxy.write("")proxy.close()valid = open('valid.txt', 'w')valid.write("")valid.close()# 获取代理IPgetProxy()starttime = time.time()# 验证ip有效性all_thread = []for i in range(30):t = threading.Thread(target=verifyProxyList)all_thread.append(t)t.start()for t in all_thread:t.join()endtime = time.time()print(f"验证代理IP花费时间{endtime-starttime}s")useProxy()proxy.close()valid.close()总结
1.白嫖的肯定不如花钱的,使用效果肯定没有花钱来的舒服。
2.可以使用缓存或者数据库进行存储
3.线程的调用需要控制好
全部代码
全部代码













![mysql一张表复制到另外一张表,报错[23000][1062] Duplicate entry ‘1‘ for key ‘big_2.PRIMARY‘](https://img-blog.csdnimg.cn/img_convert/0e88983003b16ef11aae3a22819d5821.png)
