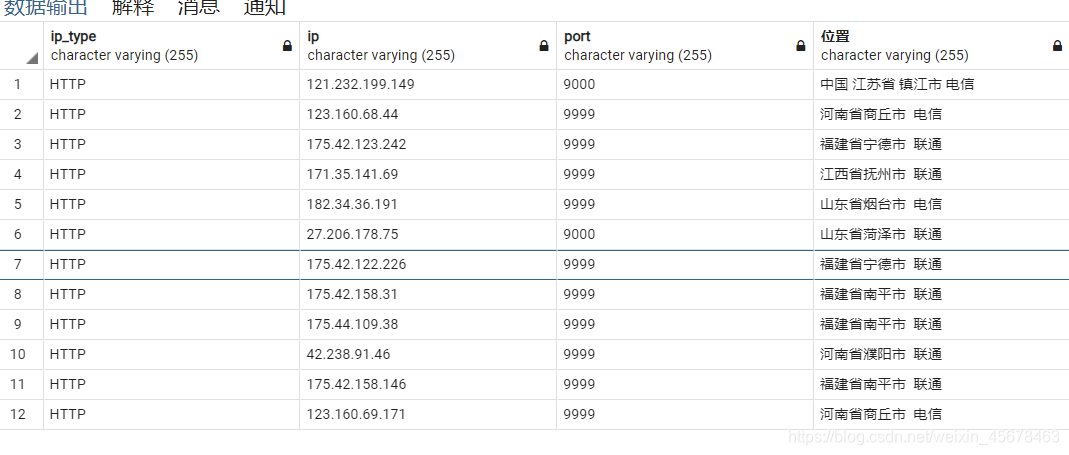
在获取 IP 时,已经成功将各个网站的代理 IP 获取下来了,然后就需要一个检测模块来对所有的代理进行一轮轮的检测,检测可用就设置为满分,不可用分数就减 1,这样就可以实时改变每个代理的可用情况,在获取有效 IP 的时候只需要获取分数高的 IP
代码地址:https://github.com/Stevengz/Proxy_pool
另外三篇:
Python搭建代理IP池(一)- 获取 IP
Python搭建代理IP池(二)- 存储 IP
Python搭建代理IP池(四)- 接口设置与整体调度
由于代理 IP 的数量非常多,为了提高 IP 的检测效率,这里使用异步请求库 Aiohttp 来进行检测。至于为什么不用抓取时用的 Requests 库,是因为它是一个同步请求库,在发出一个请求之后需要等待网页加载完成之后才能继续执行程序。这个过程会阻塞在等待响应中,如果服务器响应非常慢,一个请求就会需要十几秒,程序不会继续往下执行
异步请求库就解决了这个问题,在请求发出之后,程序可以继续接下去执行其他的事情,当响应到达时会通知程序再去处理这个响应,这样程序就没有被阻塞,可以充分把时间和资源利用起来
添加设置
增加了几个测试用的常量
setting.py
# 数据库地址
HOST = '127.0.0.1'
# MySql端口
MYSQL_PORT = 3306
# MySQl用户名、密码
MYSQL_USERNAME = '***'
MYSQL_PASSWORD = '***'
# 数据库名
SQL_NAME = 'test'# 代理等级
MAX_SCORE = 30
MIN_SCORE = 0
INITIAL_SCORE = 10# 代理池数量界限
POOL_UPPER_THRESHOLD = 1000VALID_STATUS_CODES = [200, 302]# 测试API,建议抓哪个网站测哪个
TEST_URL = 'http://www.baidu.com'# 最大批测试量
BATCH_TEST_SIZE = 30
VALID_STATUS_CODES 变量包含了正常的状态码,获取 Response 后需要判断响应的状态,如果状态码在 VALID_STATUS_CODES 这个列表里,则代表代理可用
定义方法
定义了一个类 Tester,init() 方法中建立了一个 MySqlClient 对象,供类中其他方法使用。接下来定义了一个 test_single_proxy() 方法,用来检测单个代理的可用情况,其参数就是被检测的代理
tester.py
import asyncio
import aiohttp
import time
import sys
from aiohttp import ClientError
from db import MySqlClient
from setting import *class Tester(object):def __init__(self):self.mysql = MySqlClient()# 测试单个代理async def test_single_ip(self, ip):conn = aiohttp.TCPConnector(verify_ssl=False)async with aiohttp.ClientSession(connector=conn) as session:try:if isinstance(ip, bytes):ip = ip.decode('utf-8')real_ip = 'http://' + ipprint('正在测试', ip)async with session.get(TEST_URL, proxy=real_ip, timeout=15, allow_redirects=False) as response:if response.status in VALID_STATUS_CODES:self.mysql.max(ip)print('代理可用', ip)else:self.mysql.decrease(ip)print('请求响应码不合法 ', response.status, 'IP', ip)except (ClientError, aiohttp.client_exceptions.ClientConnectorError, asyncio.TimeoutError, AttributeError):self.mysql.decrease(ip)print('代理请求失败', ip)# 主函数def run(self):print('测试器开始运行')try:count = self.mysql.count()print('当前剩余', count, '个代理')for i in range(0, count, BATCH_TEST_SIZE):start = istop = min(i + BATCH_TEST_SIZE, count)print('正在测试第', start + 1, '-', stop, '个代理')test_ip_group = self.mysql.batch(start, stop)loop = asyncio.get_event_loop()tasks = [self.test_single_ip(ip_tuple[0]) for ip_tuple in test_ip_group]loop.run_until_complete(asyncio.wait(tasks))sys.stdout.flush()time.sleep(5)except Exception as e:print('测试器发生错误', e.args)if __name__ == "__main__":test = Tester()test.run()
test_single_proxy() 方法前面加了 async 关键词,代表这个方法是异步的,方法内部首先创建了 Aiohttp 的 ClientSession 对象,此对象类似于 Requests 的 Session 对象,可以直接调用该对象的 get() 方法来访问页面
运行结果: