python爬虫设置代理ip池【源代码】
在爬取各大网站时,经常遇到一些由于访问次数过多或者访问频率过高,而导致你的ip被“封”。所以我们运用 代理ip池 来解决这个由于访问频率过高而终止爬取进行。
下面介绍一下免费获取代理ip池的方法:
一、主要思路
1、从代理ip网站(我们这里是快代理)爬取IP地址及端口号 。还有一些其他的免费IP代理网
2、利用百度验证ip是否能用
3、将ip地址转化为这种 ‘http: ‘http://114.99.7.122:8752’’ 格式
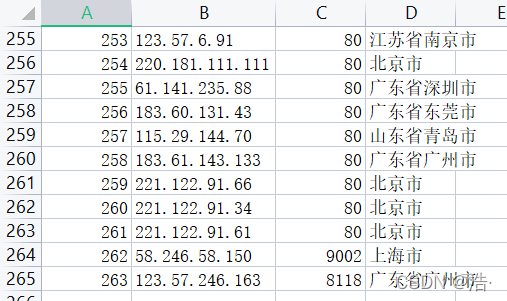
4、把使用能用的代理存储到postgresql数据库
二、 设置代理池的前期准备工作
在Requests中使用代理爬取的格式是
import requests
# 其中proxies是一个字典其格式为:
proxies = {http: 'http://114.99.7.122:8752'https: 'https://114.99.7.122:8752'}
requests.get(url, headers=headers, proxies=proxies)注意:
对于http和https两个元素,这里的http和https
代表的不是代理网站上在ip后面接的类型
代表的是requests访问的网站的传输类型是http还是https
你爬的网站是http类型的你就用http, 如果是https类型的你就用https, 在代理网站上爬的时候也要分别爬http或https的ip
三、源代码分析
1、获取源代码
# 获取源代码
def get_html(page):print("==================正在抓取第{}页===========".format(page))base_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}response = requests.get(base_url, headers=headers)data = response.texttime.sleep(2)return data
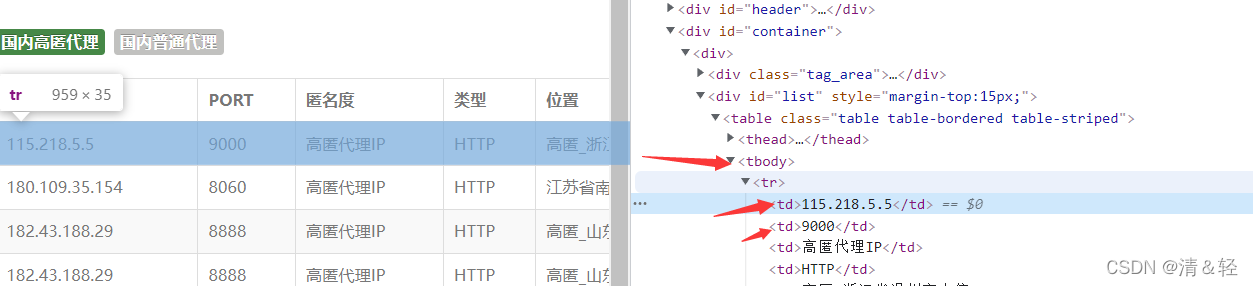
2、对获取到的源码用xpath进行分析,提取数据
def parse_data(data):# 获取ip及porthtml_data = parsel.Selector(data)ip_list = html_data.xpath('//table/tbody/tr')for tr in ip_list:proxies_dict = {}http_type = tr.xpath('./td[4]/text()').extract_first()ip_num = tr.xpath('./td[1]/text()').extract_first()port_num = tr.xpath('./td[2]/text()').extract_first()location = tr.xpath('./td[5]/text()').extract_first()proxies_dict[http_type] = ip_num + ":" + port_numip_data = (http_type, ip_num, port_num, location)insert_db(ip_data)proxies_list.append(proxies_dict)return proxies_list3、利用百度进行检测和筛选有用的ip,存放在can_use列表中
# 检测和筛选有用的ip
def check_ip(proxies_list):"""检测ip"""headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}can_use = []for proxies in proxies_list:try:response = requests.get('https://www.baidu.com/', headers=headers, proxies=proxies, timeout=0.5)if response.status_code == 200:can_use.append(proxies)except Exception as e:print(e)print(can_use)return can_use
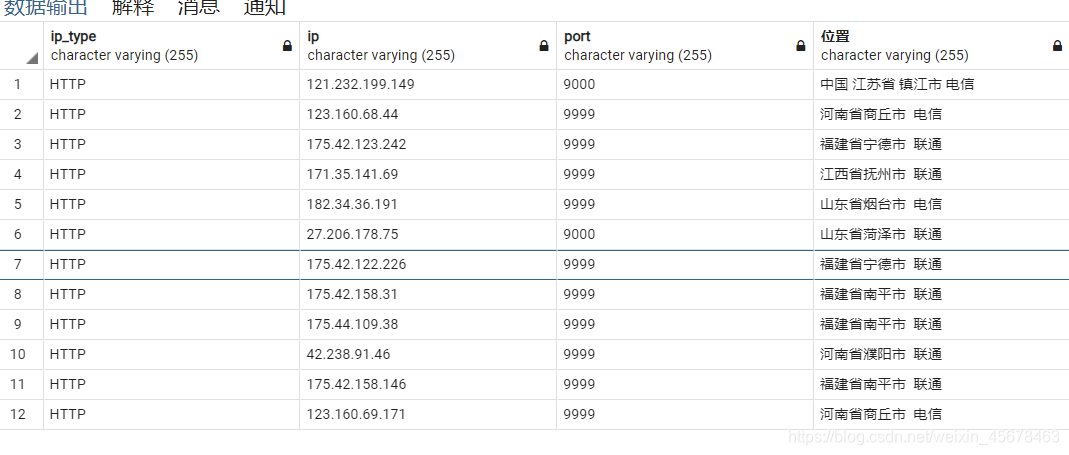
4、在postgresql创建ip表,对有效的ip进行存取,并且在ip表中插入’ip_type, ip, port, 位置’
# 创建ip表,对有效的ip进行存取
def creat_db():sql = 'CREATE TABLE ip(ip_type varchar(255),ip varchar(255), port varchar(255), 位置 varchar(255))'cursor = conn.cursor()cursor.execute(sql)conn.commit()
# 在ip表中插入ip_type, ip, port, 位置值
def insert_db(ip_data):sql = 'INSERT INTO ip(ip_type, ip, port, 位置) VALUES (%s,%s,%s,%s)'cursor = conn.cursor()cursor.execute(sql, ip_data)conn.commit()源代码
# -*- coding: utf-8 -*-
# @Time : 2020/9/22 19:35
# @Author : D
# @FileName: ip地址获取.py
# @Software: PyCharm
import time
import parsel
import requests
import psycopg2conn = psycopg2.connect(database='Python', user='postgres', password='123456', host='127.0.0.1', port=5432)def get_html(page):print("==================正在抓取第{}页===========".format(page))base_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}response = requests.get(base_url, headers=headers)data = response.texttime.sleep(2)return datadef parse_data(data):# 获取ip及porthtml_data = parsel.Selector(data)ip_list = html_data.xpath('//table/tbody/tr')for tr in ip_list:proxies_dict = {}http_type = tr.xpath('./td[4]/text()').extract_first()ip_num = tr.xpath('./td[1]/text()').extract_first()port_num = tr.xpath('./td[2]/text()').extract_first()location = tr.xpath('./td[5]/text()').extract_first()proxies_dict[http_type] = ip_num + ":" + port_numip_data = (http_type, ip_num, port_num, location)insert_db(ip_data)proxies_list.append(proxies_dict)return proxies_listdef check_ip(proxies_list):"""检测ip"""headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}can_use = []for proxies in proxies_list:try:response = requests.get('https://www.baidu.com/', headers=headers, proxies=proxies, timeout=0.5)if response.status_code == 200:can_use.append(proxies)except Exception as e:print(e)print(can_use)return can_usedef creat_db():sql = 'CREATE TABLE ip(ip_type varchar(255),ip varchar(255), port varchar(255), 位置 varchar(255))'cursor = conn.cursor()cursor.execute(sql)conn.commit()def insert_db(ip_data):sql = 'INSERT INTO ip(ip_type, ip, port, 位置) VALUES (%s,%s,%s,%s)'cursor = conn.cursor()cursor.execute(sql, ip_data)conn.commit()if __name__ == '__main__':creat_db()proxies_list = []for page in range(1, 10):data = get_html(page)proxies_list = parse_data(data)can_use = check_ip(proxies_list)print('能用的代理ip:', can_use)print('能用的代理ip数量:', len(can_use))