目录
- 什么是Combiner
- 本质
- 实例
- 编写Mapper类
- 编写Reducer类
- 编写Driver类
- 结果
什么是Combiner
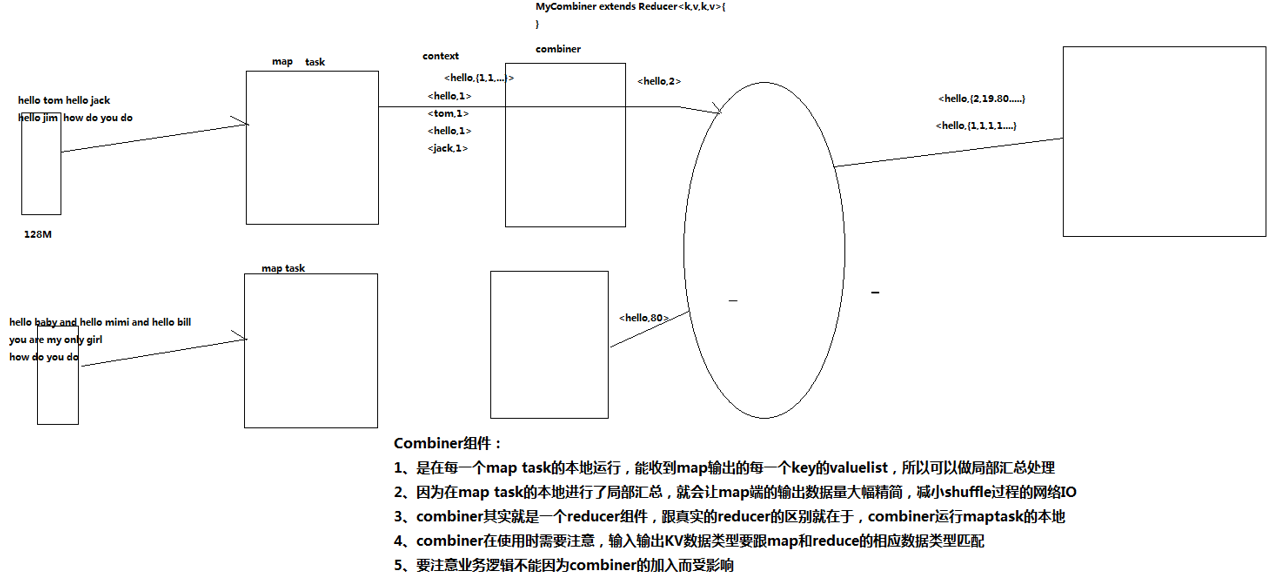
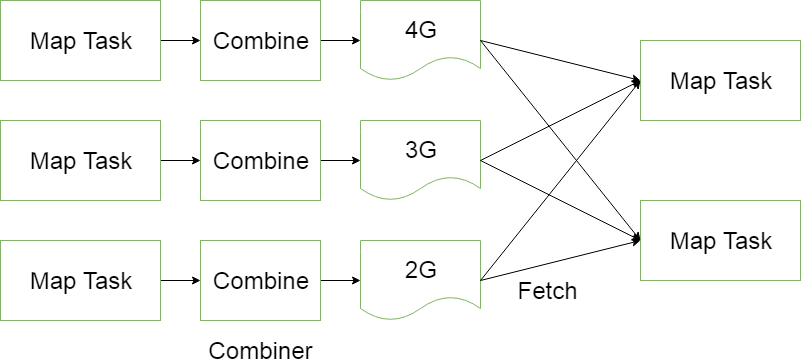
MapReduce中的Combiner就是为了避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载。通俗来说就是在Map之后,如果Map阶段不进行合并的话,到达reduce端的数据将是下面这种类型的:<a,1><a,1><a,1>,reducer要处理的工作量大,还要消耗大量的IO,reduce的数量是相对于map是更少的,所以可以把合并的工作交给map来做,这个工作就是combiner的工作,经过combiner之后的结果集是这样的:<a,3> <b,2>
Combiner工作机制如下:
<a,1><a,1><a,1> ---------> <a,3>
<b,1><b,1> ---------> <b,2>
本质
- Combiner是MR程序中Mapper和Reducer之外的一种组件。
- Combiner组件的父类就是Reducer。
- Combiner和Reducer的区别在于运行的位置:
Combiner是在每一个MapTask所在的节点运行;
Reducer是接收全局所有Mapper的输出结果; - Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减少网络传输量。
实例
编写Mapper类
package Combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*** @author 公羽* @time : 2020/11/4 22:25* @File : WcMapper.java*/
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for (String word : words) {k.set(word);context.write(k, v);}}
}
编写Reducer类
package Combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;/*** @author 公羽* @time : 2020/11/4 22:25* @File : WcReducer.java*/
public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable>{int sum;IntWritable v = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {// 1 累加求和sum = 0;for (IntWritable count : values) {sum += count.get();}// 2 输出v.set(sum);context.write(key,v);}
}
编写Driver类
package Combiner;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/*** @author 公羽* @time : 2020/11/4 22:26* @File : WcDriver.java*/
public class WcDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取配置信息以及封装任务Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);// 2 设置jar加载路径job.setJarByClass(WcDriver.class);// 3 设置map和reduce类job.setMapperClass(WcMapper.class);job.setReducerClass(WcReducer.class);// 4 设置map输出job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// !!!!!!!!!!!!!!!!!添加此行job.setCombinerClass(WcReducer.class);// 5 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path("E:\\hadoop\\Demo\\word_test.txt"));FileOutputFormat.setOutputPath(job, new Path("E:\\hadoop\\Demo\\output"));// 7 提交boolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
结果
在job.setCombinerClass(WcReducer.class);添加后可以明显的发现map和reduce的值变小,combine的值在增加,这体现了combine能减少IO并提升作业的执行性能但是在求平均数的场景下,会出现错误的结果