k-means简介
k-means算法也称k均值算法,是一种常用的聚类算法。聚类算法是研究最多、应用最广的一种无监督学习算法。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”。通过这样的划分,每个簇里的样本可能具有一些潜在的、共同的特质。
例如,对于给定样本集D={x1,x2,x3,…,xm}包含m个无标记样本,其中每个样本xi是一个n维的特征向量,聚类算法将样本集D划分为k个不相交的簇。其中,k个簇之间互不相交,且k个簇的并集为D。
k-means原理
k-means的伪代码
输入:样本集D = {x1,x2,x3,...,xm};聚类簇数k.
过程:
从D中随机抽取k个样本作为初始均值向量{u1,u2,...,uk}
repeat初始化Cl = ∅(1≤l≤k)for i = 1:m计算样本xi与各均值向量uj(1≤j≤k)的距离d;根据距离最近的均值向量确定xi的簇标记;将样本xi划入相应的簇Cl;endfor j = 1:k计算新的均值向量new_uj:对簇中每个样本求和/簇中样本的个数if new_uj ≠ uj将当前均值向量uj更新为new_ujelse保持当前均值向量不变endend
until 当前均值向量均未更新
输出:簇划分为C = {C1,C2,...,Ck}
k值的选取
有手肘法和轮廓系数法两种方法。这里简单介绍手肘法。
手肘法的核心指标是SSE(Sum of Squared Errors),误差平方和
S S E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 SSE=\sum_{i=1}^{k}\sum_{x\in C_i}||x-\mu_i||_2^2 SSE=i=1∑kx∈Ci∑∣∣x−μi∣∣22
其中,Ci是第i个簇,x是Ci中的样本点,μi是Ci的质心(Ci中所有样本的均值)。直观来看,该式是求当前的k值所对应的簇内的各个样本点到中心点欧式距离的平方和,该数值能体现出聚类后各个簇中样本点的密集程度,即SSE值越小,各个簇中的样本点越密集。
对K值进行迭代,分别计算出相应的SSE。随着k值的增大,SSE会随之减小。这是因为随着k值的增大,样本会被划分得更加细致,每个簇就会更加紧凑。
SSE的值会随着K值的增大而不断减小,直到k值与样本集中样本点的个数相等,此时SSE达到最小值。显然,并不是SSE的值越小,所选的K值就越合理。
观察SSE随K值变化而变化的图像,分析K最合理的取值。(代码在后面放出来)

从图像上看,当K值小于3时,SSE下降的幅度很大;而当K值大于3之后SSE下降的幅度大幅减小,这说明K值已经超过了最“合理”的值,从而导致每次减小K所带来的“收益”大幅减小,因此最佳的K值为3。由于图像看起来像手肘,因此这种选取最佳K值的方式被称为“手肘法”。
k-means的实现
首先编写一个计算“有序属性”距离的函数,也可以使用matlab中自带的pdist或者是norm函数,推荐使用norm。
function dist = cal_dist(X,p)
%计算两个样本点之间的闵可夫斯基距离,当p=2时即为欧氏距离,当p=1时即为曼哈顿距离
dim = size(X);
sum = 0;
for i = 1:dim(2)sum = sum + abs(X(1,i)-X(2,i))^p;
end
dist = sum^(1/p);
end
再写一个归一化处理数据的函数。
function data = normalization(x)
%归一化处理数据
d = size(x);
data = zeros(d(1),d(2));
for i = 1:d(2)l = x(:,i);data(:,i) = (l - min(l))/(max(l)-min(l));
end
end
然后进入正题。
function [index,C,sumd] = Kmeans(sample, k, threshold, n)
%K均值算法
%C:k个簇中心
%index:聚类后每个样本的标记
%sumd:样本点到相应的簇心的距离
%sample:需要进行聚类的样本
%k:划分簇的个数
%threshold:差异度阈值
%n最大迭代次数
iter = 0;
dim = size(sample);
index = zeros(dim(1), 1);
dist = zeros(k, 1);
C = sample(randperm(dim(1), k), :);
while 1sumd = zeros(dim(1), 1);for i = 1:dim(1)for j = 1:kX = [sample(i, :);C(j, :)];dist(j) = cal_dist(X, 2);end[d, idx] = min(dist);sumd(i) = d;index(i) = idx;endnew_C = zeros(k, dim(2));c = 0;for i = 1:kcount = 0;for j = 1:dim(1)if index(j) == icount = count + 1;new_C(i, :) = new_C(i, :) + sample(j, :);endendnew_C(i, :) = new_C(i, :) / count;Y = [new_C(i, :);C(i, :)];if cal_dist(Y, 2)<= thresholdc = c + 1;endenditer = iter + 1;if c == kbreakelseif iter > nbreakelseC = new_C;end
end
end
编写一个函数打印K-SSE图像,K值的选取理念已在上文提过。
function Visualize_SSE(sample, k)
%查看SSE随K值变化而变化的图像
dim = size(sample);
coordinate = zeros(k, 2);
for i = 1:kcoordinate(i, 1) = i;if i == 1avg = mean(sample);d = zeros(dim(1), 1);for j = 1:dim(1)X = [sample(j, :);avg];d(j,1) = cal_dist(X, 2);endcoordinate(i, 2) = sum(d);else[~, ~, sumd]=Kmeans(sample, i, 0.1, 9000);sumd = sumd.^2;coordinate(i, 2)=sum(sumd);end
end
plot(coordinate(:, 1),coordinate(:, 2))
xlabel('K')
ylabel('SSE')
end
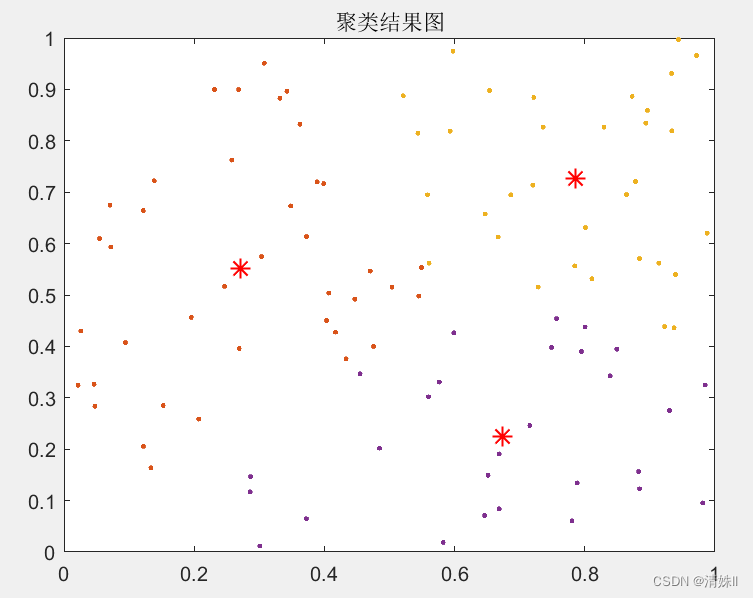
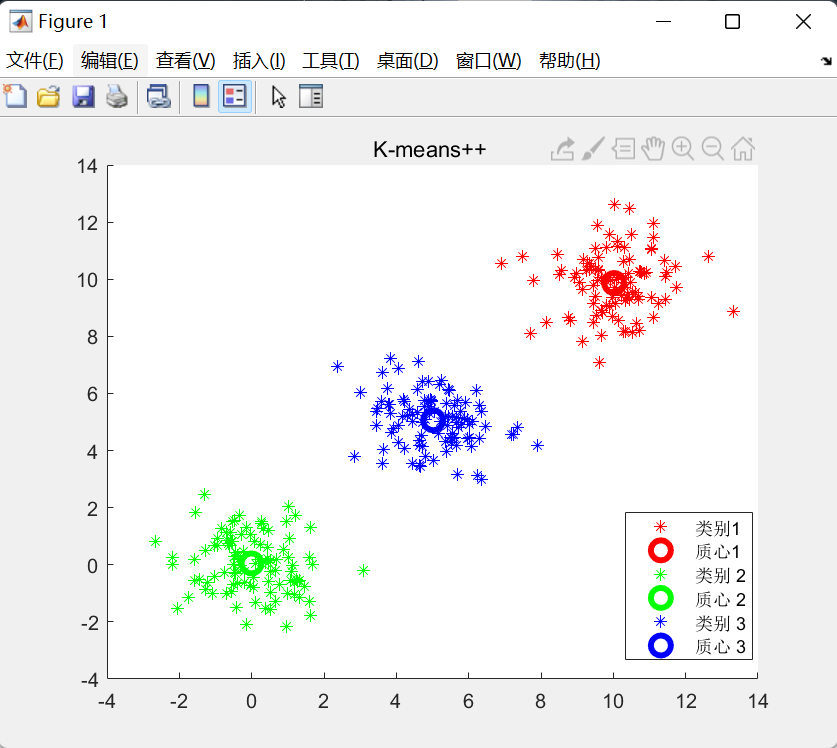
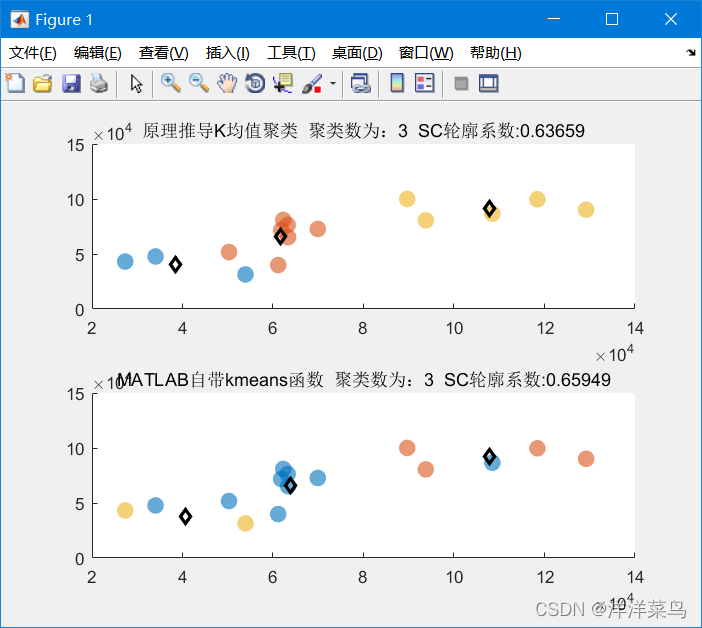
通过分析得出最佳的K值为3,下面编写一个脚本看一下聚类效果(matlab初学者表示不清楚还有哪些数据集只好用fisheriris中meas的前两维来代替。并不是说聚类算法不能对高维空间的数据进行聚类,选择两个维度是为了结果的可视化,也可以选择三个维度。)
load fisheriris
data = normalization(meas);
[idx,C,~] = Kmeans(data(:,1:2),3,0,5000);
figure
gscatter(data(:,1),data(:,2),idx,'bgm')
hold on
plot(C(:,1),C(:,2),'kx')
legend('Cluster 1','Cluster 2','Cluster 3','ClusterCentroid')
聚类效果:

本文为了顺带提一嘴距离度量因此自己十分简陋的写了一个计算距离的函数,实际上使用matlab中自带的norm或者pdist即可。
本文只是对k均值进行了一个简单的介绍。聚类任务相关的性能度量和距离度量还有很多;此外,如何对高维空间中的数据进行聚类本文也不做讨论。
代码
https://github.com/Qyokizzzz/AI-Algorithm/tree/master/K-means