参考:
http://www.csdn.net/article/2012-07-03/2807073-k-means
http://www.cnblogs.com/zhzhang/p/5437778.html
http://blog.csdn.net/qll125596718/article/details/8243404/
K-means属于无监督学习方法
K表示类别数,Means表示均值,K一般由人工来指定,或通过层次聚类(Hierarchical Clustering)的方法获得数据的类别数量作为选择K值的参考
选择较大的K可以降低数据的误差,但会增加过拟合的风险。
K-mean算法如下:
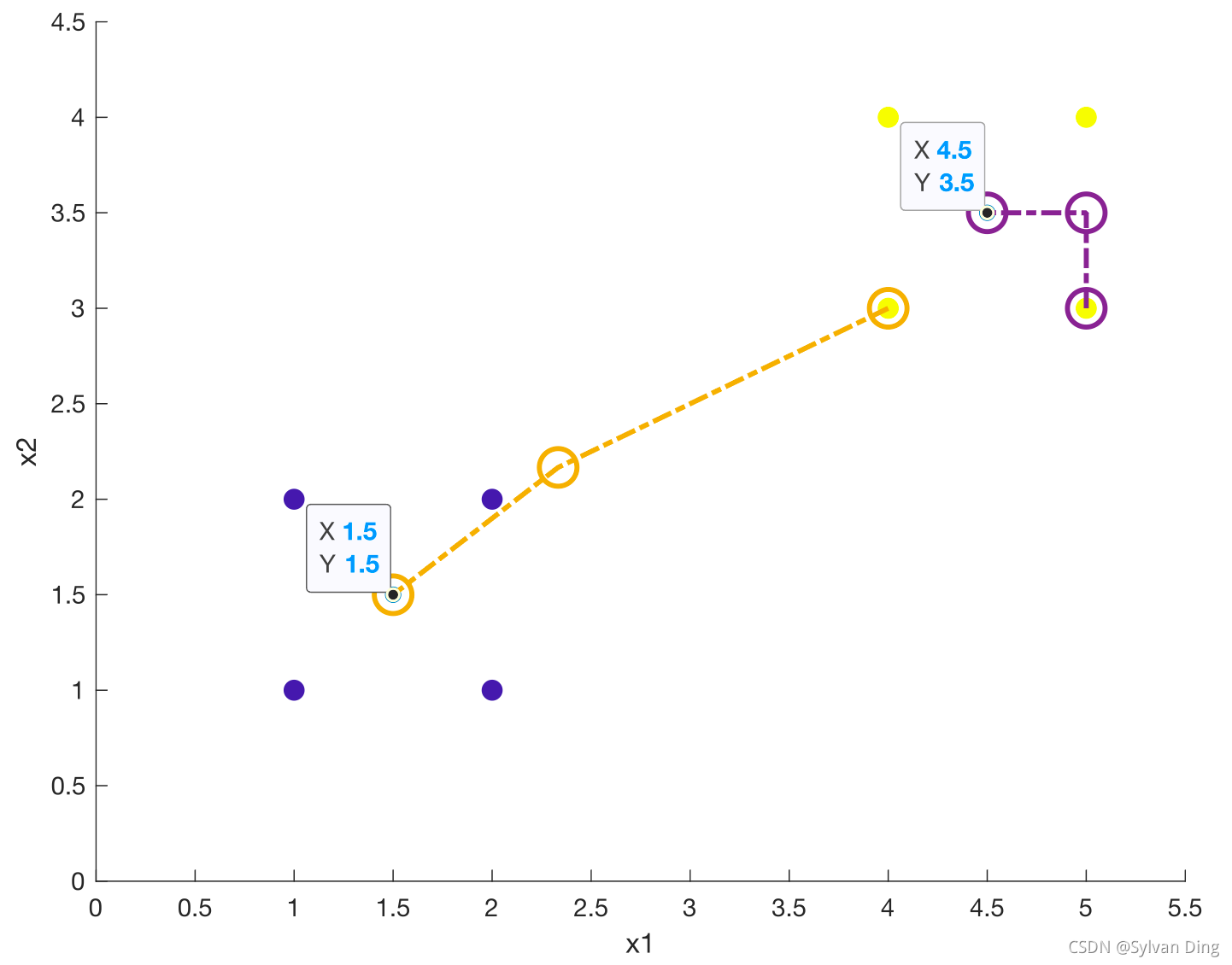
(1)随机选取K个初始质心
(2)分别计算所有样本到这K个质心的距离
(3)如果样本离质心Si最近,那么这个样本属于Si点群;如果到多个质心的距离相等,则可划分到任意组中
(4)按距离对所有样本分完组之后,计算每个组的均值(最简单的方法就是求样本每个维度的平均值),作为新的质心
(5)重复(2)(3)(4)直到新的质心和原质心相等,算法结束
K-mean算法的一些特点、与EM估计的关系:
(1)定义畸变函数J=∑(所有点到质心距离),J是非凸函数,所以最后得到的结果并不是全局最小值,也就是说k-means算法对质心的初始位置选取比较敏感。可以选取不同的处置跑多遍k-means,然后选取最小的J对应的μ和c
(2)通过不断交替更新【质心μ】和【每个样本类别c】,有种坐标上升(coordinate ascent的思想)
(3)k-means算法也有种E-M估计的思想,因为E-M的E步是估计隐变量,对应k-means的第一步估计质心,然后确定类别变量(隐变量);M步是通过调整其他参数,即重新确定质心μ,来使得J最小化
距离的度量:
K-mean算法实现过程如下:
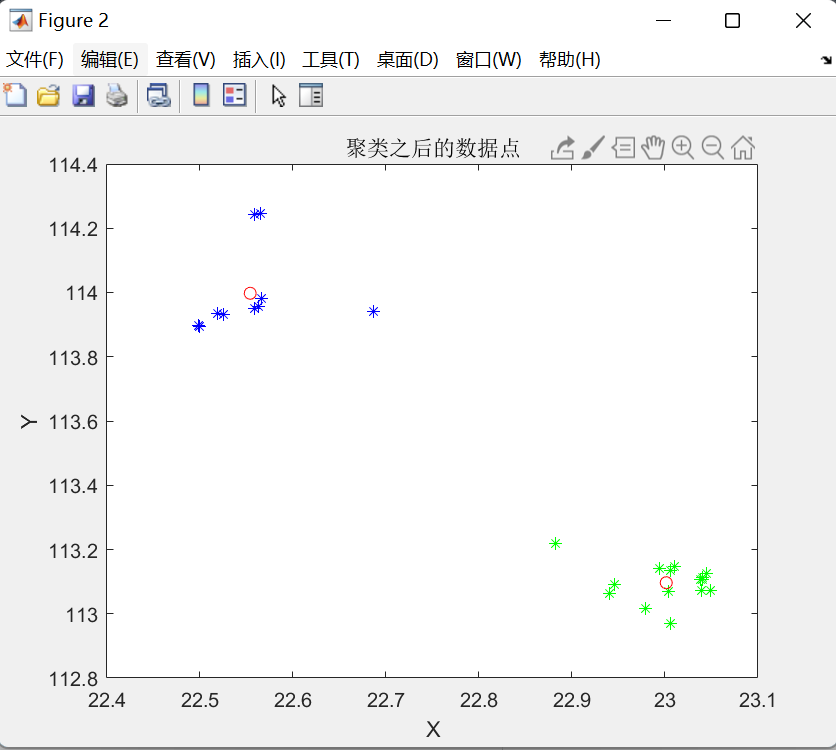
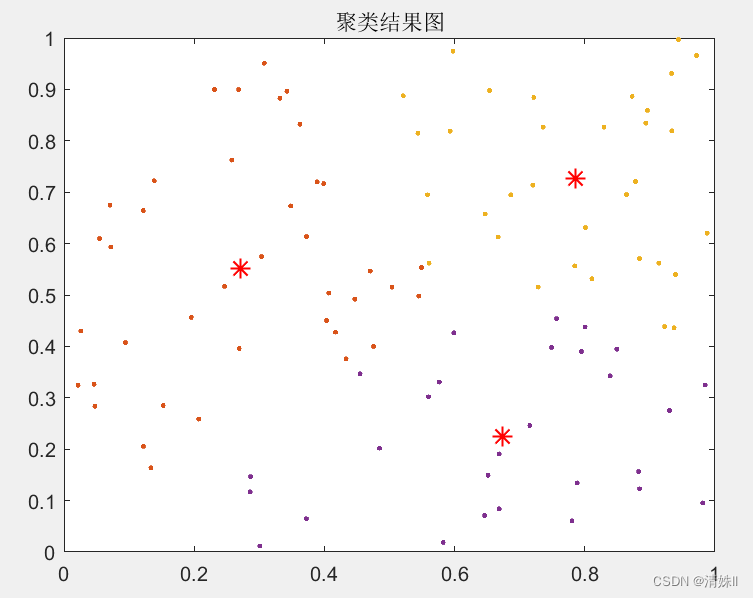
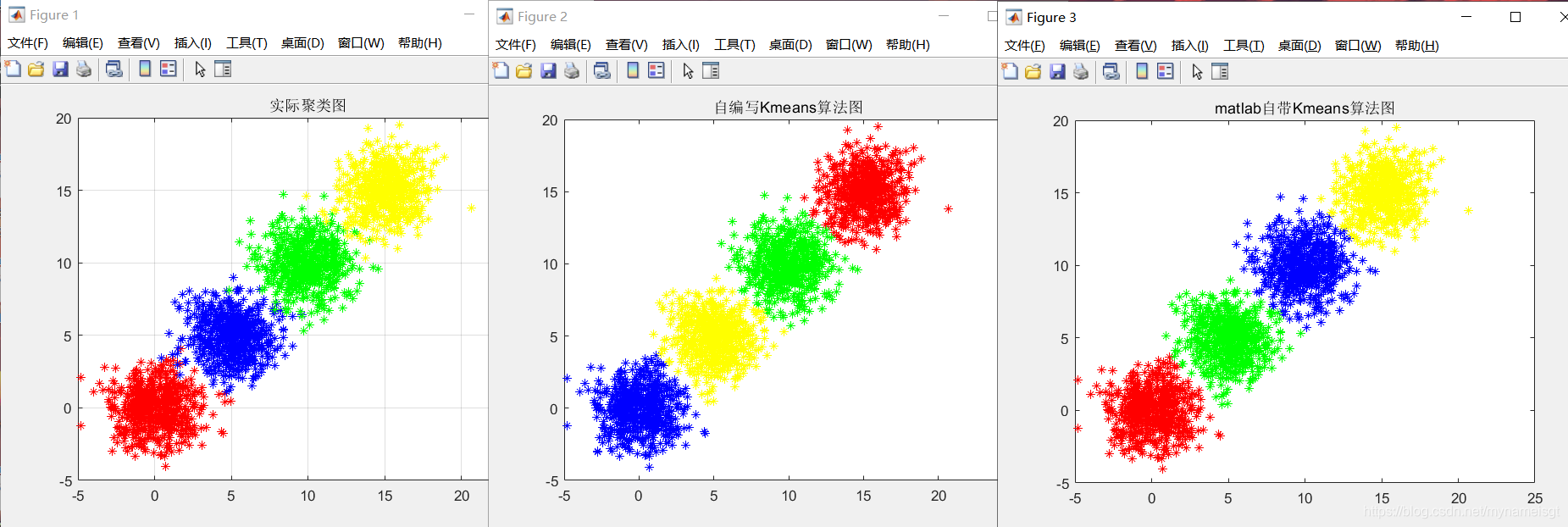
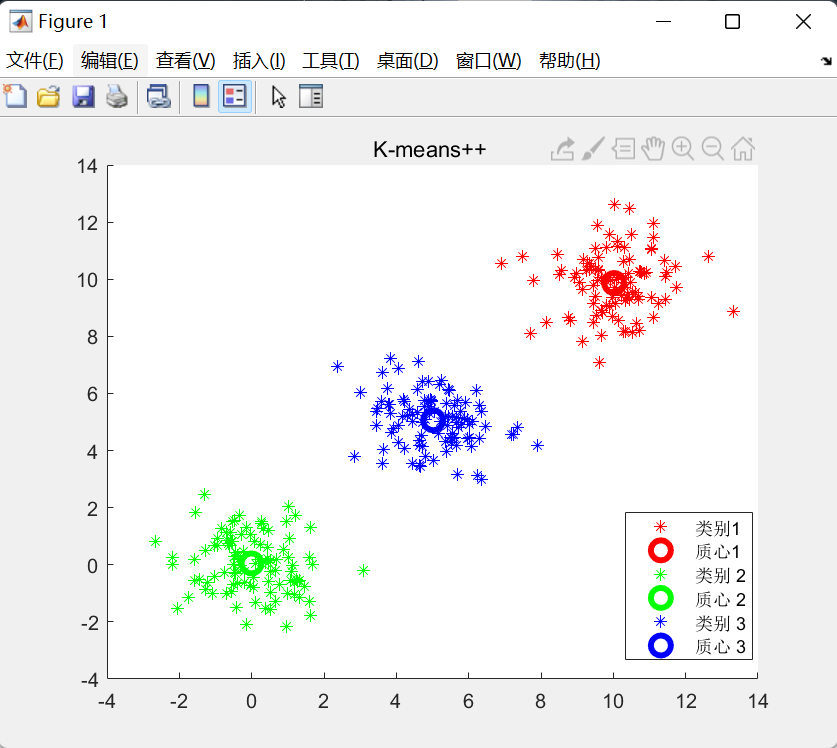
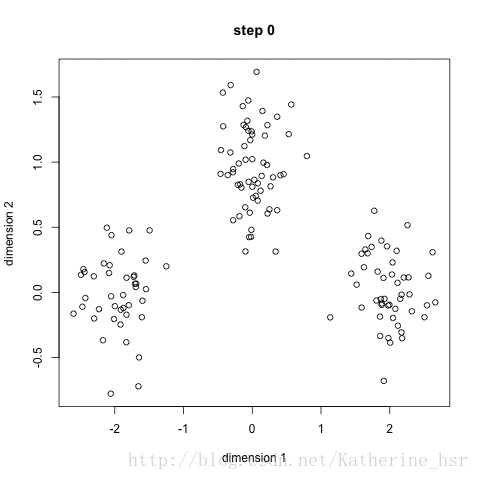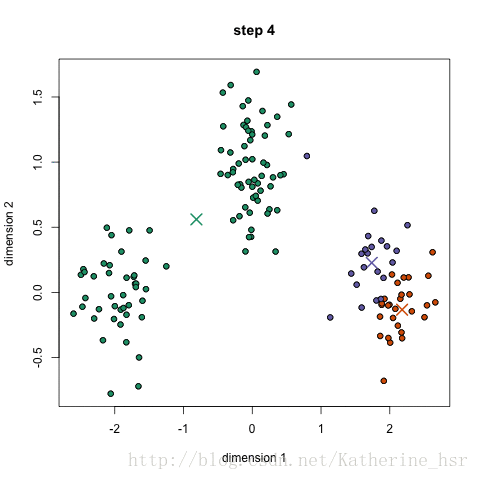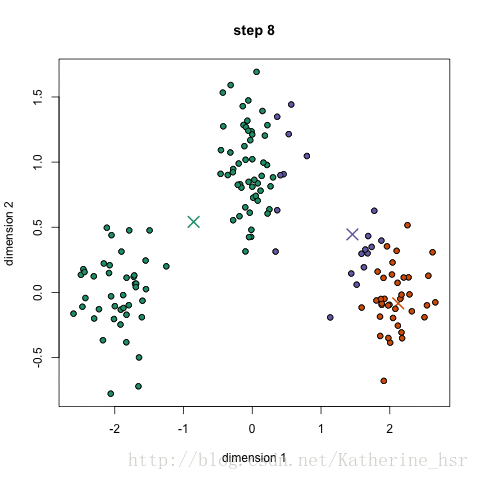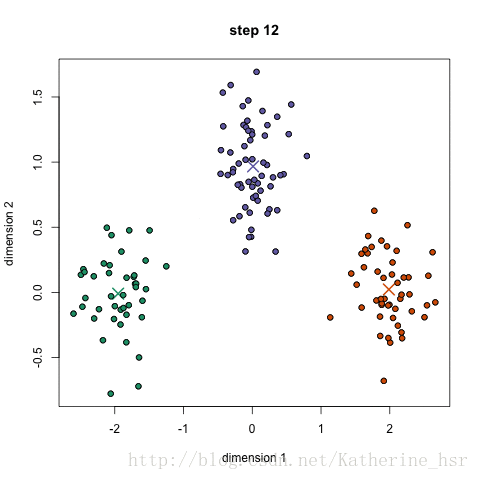
(1)先产生三组不同的高斯分布数据,做为原始数据,如下图:

(2)当聚类中心数N取不同的值,聚类结果不同,如下:
N=2时

N=3时

N=4时

N=5时

另外:即使N相同的情况下,每次聚类的结果也会不同,因为初始质点的选取是随机的
MATLAB实现如下:
clear all;close all;clc;
% 第一组数据
mu1=[0 0 ]; %均值
S1=[.1 0 ;0 .1]; %协方差
data1=mvnrnd(mu1,S1,100); %产生高斯分布数据
%第二组数据
mu2=[1.25 1.25 ];
S2=[.1 0 ;0 .1];
data2=mvnrnd(mu2,S2,100);
% 第三组数据
mu3=[-1.25 1.25 ];
S3=[.1 0 ;0 .1];
data3=mvnrnd(mu3,S3,100);
% 显示数据
plot(data1(:,1),data1(:,2),'b+');
hold on;
plot(data2(:,1),data2(:,2),'r+');
plot(data3(:,1),data3(:,2),'g+');
grid on;
% 三类数据合成一个不带标号的数据类
data=[data1;data2;data3];
N=3;%设置聚类数目
[m,n]=size(data);
pattern=zeros(m,n+1);
center=zeros(N,n);%初始化聚类中心
pattern(:,1:n)=data(:,:);
for x=1:Ncenter(x,:)=data( randi(300,1),:);%第一次随机产生聚类中心
end
while 1
distence=zeros(1,N);
num=zeros(1,N);
new_center=zeros(N,n);for x=1:mfor y=1:Ndistence(y)=norm(data(x,:)-center(y,:));%计算到每个类的距离end[~, temp]=min(distence);%求最小的距离pattern(x,n+1)=temp;
end
k=0;
for y=1:Nfor x=1:mif pattern(x,n+1)==ynew_center(y,:)=new_center(y,:)+pattern(x,1:n);num(y)=num(y)+1;endendnew_center(y,:)=new_center(y,:)/num(y);if norm(new_center(y,:)-center(y,:))<0.1k=k+1;end
end
if k==Nbreak;
elsecenter=new_center;
end
end
[m, n]=size(pattern);%最后显示聚类后的数据
figure;
hold on;
for i=1:mif pattern(i,n)==1 plot(pattern(i,1),pattern(i,2),'r*');plot(center(1,1),center(1,2),'ko');elseif pattern(i,n)==2plot(pattern(i,1),pattern(i,2),'g*');plot(center(2,1),center(2,2),'ko');elseif pattern(i,n)==3plot(pattern(i,1),pattern(i,2),'b*');plot(center(3,1),center(3,2),'ko');elseif pattern(i,n)==4plot(pattern(i,1),pattern(i,2),'y*');plot(center(4,1),center(4,2),'ko');elseplot(pattern(i,1),pattern(i,2),'m*');plot(center(4,1),center(4,2),'ko');end
end
grid on;