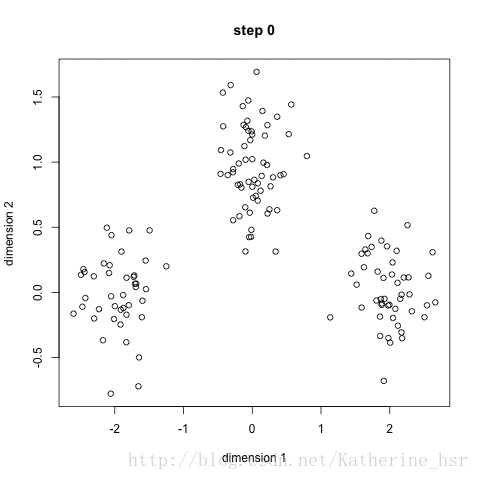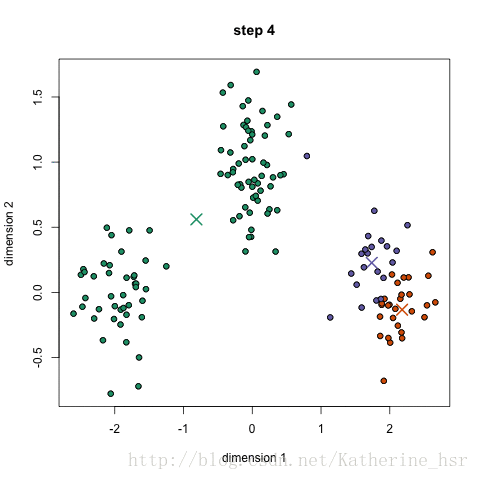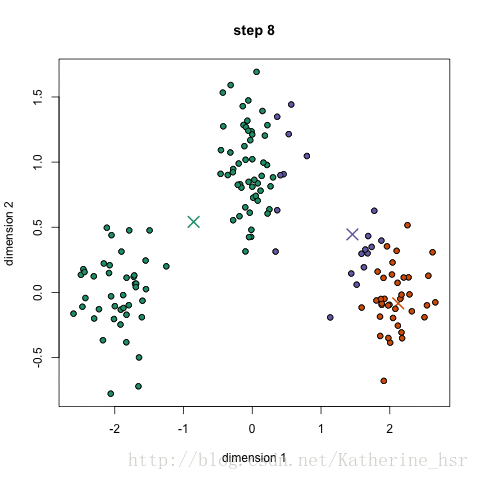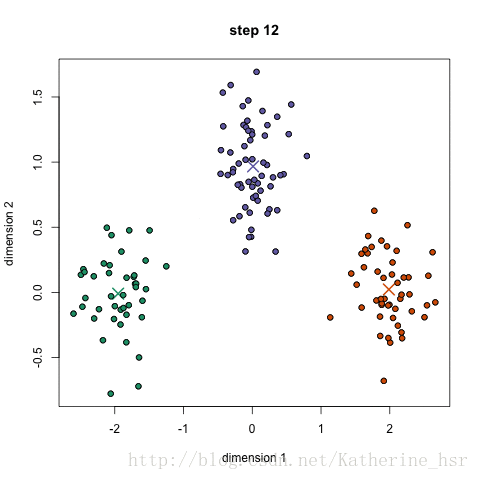
聚类算法—k-Means实验
k-平均(k-Means),也被称为k-均值,是一种得到最广泛使用的聚类算法[1]. k-Means算法以k为参数,把n个对象分为k个簇,使得簇内具有较高的相似度。
实验目的
- 了解常用聚类算法及其优缺点;
- 掌握k-Means聚类算法对数据进行聚类分析的基本原理和划分方法;
- 利用k-Means聚类算法对数据集进行聚类实验;
- 熟悉使用Matlab进行算法的实现。
聚类算法的主要思想
主要思想
给定一个有n个对象的数据集,划分聚类技术将构造数据k个划分,每一个划分就代表一个簇, k ≤ n k\le n k≤n. 每一个簇至少包含一个对象,每一个对象属于且仅属于一个簇。
对于给定的k,算法首先给出一个初始的划分方法,以后通过反复迭代的方法改变划分,使得每一次改进之后的划分较前一次更好。
评价函数
更好的标准是:同一簇中的对象越接近越好,而不同簇中的对象越远越好,目标是最小化所有对象与其簇中心之间相异度之和。
各个簇应该是紧凑的,各个簇间的距离应当尽可能远。因此,用聚类C的类内差异(Within cluster variation) w ( C ) w(C) w(C) 和类间差异(Between cluster variation) b ( C ) b(C) b(C) 分别衡量上述两要求。
w ( C ) = ∑ i = 1 k w ( C i ) = ∑ i = 1 k ∑ x ∈ C i d ( x , x i ‾ ) 2 w(C)=\sum_{i=1}^{k}w(C_i)=\sum_{i=1}^{k}\sum_{x\in C_i}d(x,\overline{x_i})^2 w(C)=i=1∑kw(Ci)=i=1∑kx∈Ci∑d(x,xi)2
b ( C ) = ∑ 1 ≤ j ≤ i ≤ k d ( x j ‾ , x i ‾ ) 2 b(C)=\sum_{1\le j\le i\le k}d(\overline{x_j},\overline{x_i})^2 b(C)=1≤j≤i≤k∑d(xj,xi)2
其中, x i ‾ \overline{x_i} xi 是类 C i C_i Ci 的聚类中心,d 为距离函数。聚类C的总体质量可以被定义为 b ( C ) w ( C ) \frac{b(C)}{w(C)} w(C)b(C).
k-Means算法原理
k-Means算法用类内均值作为聚类中心、用欧氏距离定义d,并使上述 w ( C ) w(C) w(C) 最小化。
优化目标
arg max C ∑ i = 1 k ∑ x ∈ C i ∥ x − x i ‾ ∥ 2 \mathop{\arg\max}\limits_{C} \sum_{i=1}^k \sum_{x\in C_i} \parallel x-\overline{x_i}\parallel ^2 Cargmaxi=1∑kx∈Ci∑∥x−xi∥2
表示选取合适的C使得所有对象的平方误差总和最小,其中x是空间中的点, x i ‾ \overline{x_i} xi 是簇 C i C_i Ci 的平均值,这个优化目标可以保证生成的结果簇尽可能的紧凑和独立。
算法描述
首先随机选择k个对象,每个对象初始地代表了一个簇的平均值或中心。对剩余的每个对象根据其与各个簇中心的距离,将它赋给最近的簇。然后重新计算每个簇的平均值。这个过程不断重复,直到上述平方误差总和收敛。
k-Means算法分析
优点
- 对处理大数据集,该算法是相对可伸缩和高效率的,时间复杂度约为 O ( k ⋅ n ⋅ t ) \mathcal{O} (k\cdot n\cdot t) O(k⋅n⋅t),t是迭代次数。k-Means算法经常以局部最优结束;
- 算法尝试找出使平方误差最小的k个划分,当结果簇是密集的,而簇与簇之间区别明显时,k-Means的效果较好。
缺点
- 若涉及离散属性,其平均值无法定义,无法使用k-Means聚类;
- 必须事先给出参数k,k的选取对聚类质量和效果影响很大;
- k-Means算法不适合发现非凸面形状的簇,或者大小差别很大的簇。而且对于“噪声”和孤立点数据是敏感的,少量的该类数据对平均值产生较大影响。
算法改进
k-模算法:将k-Means的应用扩大到离散数据。k-原型可以对离散与数值属性两种混合的数据进行聚类,在k-原型中定义了一个对数值与离散属性都计算的相异性度量标准。[2]
k-中心点算法:解决了k-Means算法对孤立点敏感的问题,不采用簇中的平均值作为参照点,而使用簇中位置最靠近中心的对象作为参照点。基本思路是反复用非代表对象来替代代表对象,以改进聚类的质量。PAM(Partition Around Medoid)是最早提出的k-中心点算法之一。[3]
代码
clc;clear;
k = 2;
data = [1 1; 2 1; 1 2; 2 2; 4 3; 5 3; 4 4; 5 4;];
eps = 0.1;
epochs = 100;
[n,~] = size(data);
% initialize the last column of data as classes
data(:,end+1) = 0;
% assign initial value for means
rng('default') % For reproducibility
clusters = data(randperm(n,k),1:end-1);
% initialize E
E = inf;
% save means steps
cnt = 0; % counter
cls_steps = [];
while epochs>0% to save means stepscnt = cnt + 1;cT = clusters';cls_steps(cnt,:) = cT(:)';% assign each xj to the cluster which has the closet meanD = pdist2(data(:,1:end-1),clusters);[~,I] = min(D');data(:,end) = I';% calculate new means for each classesclusters = grpstats(data(:,1:end-1),data(:,end));% calculate criterion function ElastE = E;E = .0;for i=1:nE = E + pdist2(data(i,1:end-1),clusters(data(i,end),:));endif lastE-E<=epsbreakendepochs = epochs - 1;
end
Matlab2021a
结果验证
结果数据
在data.csv数据集上运行上述代码,得到结果如下:
Clusters: 聚类中心
| x1 | x2 |
|---|---|
| 1.5 | 1.5 |
| 4.5 | 3.5 |
E = 5.65685424949238
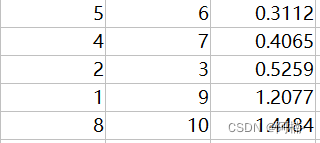
cls_steps: 聚类中心移动记录
| c1x1 | c1x2 | c2x1 | c2x2 |
|---|---|---|---|
| 4 | 3 | 5 | 3 |
| 2.33333333 | 2.16666667 | 5 | 3.5 |
| 1.5 | 1.5 | 4.5 | 3.5 |
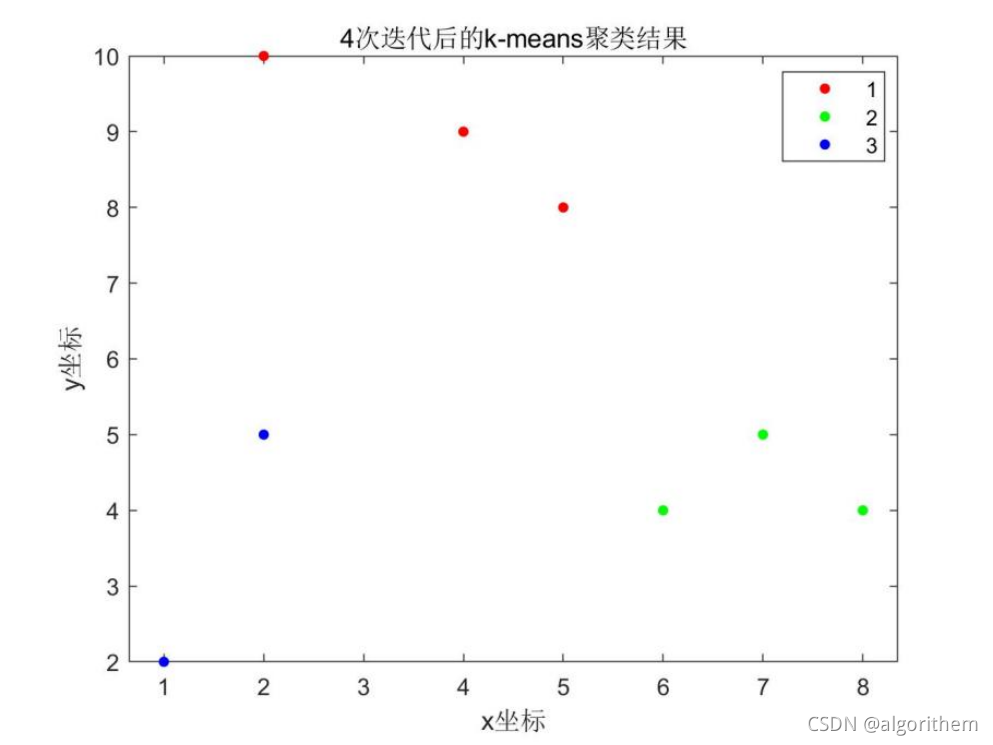
结果图像
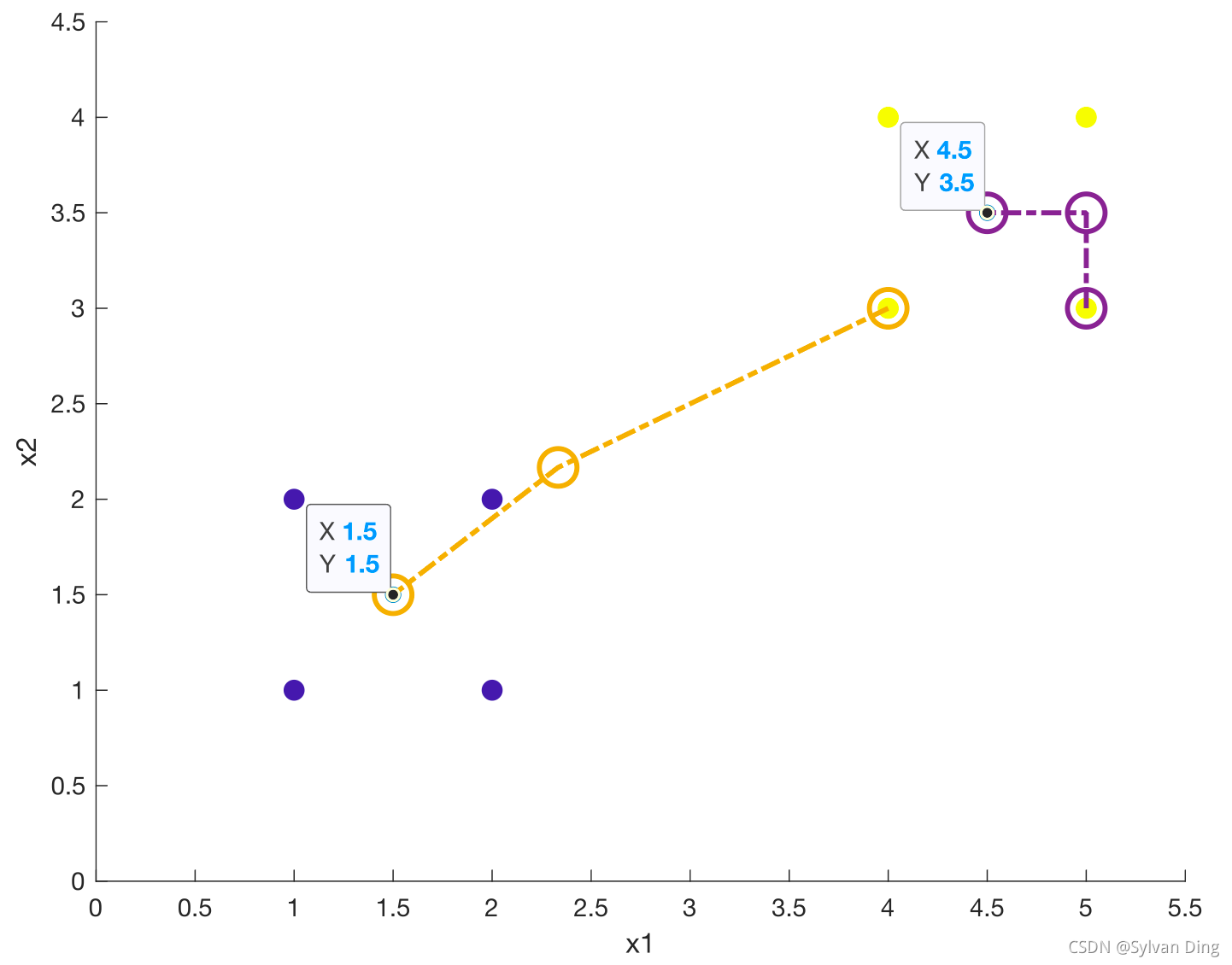
其中,蓝色/黄色实心点表示不同分类下的数据点,空心橙色/紫色圆环表示k-Means聚类中心的变化情况。
附录(data.csv)
| Index | Attr1 | Attr2 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 1 |
| 3 | 1 | 2 |
| 4 | 2 | 2 |
| 5 | 4 | 3 |
| 6 | 5 | 3 |
| 7 | 4 | 4 |
| 8 | 5 | 4 |
参考
- 毛国君、段立娟, 《数据挖掘原理与算法》, 清华大学出版社, 2016-01-01, ISBN:9787302415817
- Ramasubramanian P , Kumar S P , Anandam D . Experimental work on Data Clustering using Enhanced Random KMode Algorithm. 2020.
- Bhat A . K-Medoids Clustering Using Partitioning Around Medoids for Performing Face Recognition. 2014.