由于需要对ADC进行驱动设计,因此学习了一下Linux驱动的IIO子系统。本文翻译自《Linux Device Drivers Development 》--John Madieu,本人水平有限,若有错误请大家指出。
IIO Framework
工业I / O(IIO)是专用于模数转换器(ADC)和数模转换器(DAC)的内核子系统。随着越来越多的具有不同代码实现的传感器(具有模拟到数字或数字到模拟,功能的测量设备)分散在内核源上,收集它们变得必要。这就是IIO框架以通用的方式所做的事情。自2009年以来,Jonathan Cameron和Linux-IIO社区一直在开发它。

加速度计,陀螺仪,电流/电压测量芯片,光传感器,压力传感器等都属于IIO系列器件。
IIO模型基于设备和通道架构:
l 设备代表芯片本身。它是层次结构的顶级。
l 通道代表设备的单个采集线。设备可以具有一个或多个通道。例如,加速度计是具有 三个通道的装置,每个通道对应一个轴(X,Y和Z)。
IIO芯片是物理和硬件传感器/转换器。它作为字符设备(当支持触发缓冲时)暴露给用户空间,以及包含一组文件的sysfs目录条目,其中一些文件代表通道。单个通道用单个sysfs文件条目表示。
下面是从用户空间与IIO驱动程序交互的两种方式:
l /sys/bus/iio/iio:deviceX/:表示传感器及其通道
l /dev/iio:deviceX: 表示导出设备事件和数据缓冲区的字符设备
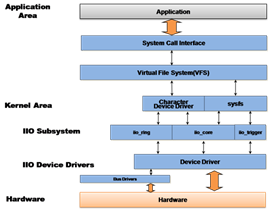
IIO框架架构和布局
上图显示了如何在内核和用户空间之间组织IIO框架。 驱动程序使用IIO核心公开的一组工具和API来管理硬件并向IIO核心报告处理。 然后,IIO子系统通过sysfs接口和字符设备将整个底层机制抽象到用户空间,用户可以在其上执行系统调用。
IIO API分布在多个头文件中,如下所示:
#include <linux/iio/iio.h> /* mandatory */ #include <linux/iio/sysfs.h> /* mandatory since sysfs is used */ #include <linux/iio/events.h> /* For advanced users, to manage iio events */ #include <linux/iio/buffer.h> /* mandatory to use triggered buffers */ #include <linux/iio/trigger.h>/* Only if you implement trigger in your driver (rarely used)*/
在以下文章中,我们将描述和处理IIO框架的每个概念,例如
遍历其数据结构(设备,通道等)
触发缓冲支持和连续捕获,以及其sysfs接口
探索现有的IIO触发器
以单次模式或连续模式捕获数据
列出可用于帮助开发人员测试其设备的可用工具
(一):IIO data structures:IIO数据结构
IIO设备在内核中表示为struct iio_dev结构体的一个实例,并由struct iio_info结构体描述。 所有重要的IIO结构都在include/linux/iio/iio.h中定义。
iio_dev structure(iio_dev结构)
该结构代表IIO设备,描述设备和驱动程序。 它告诉我们:
l 设备上有多少个通道?
l 设备可以在哪些模式下运行:单次,触发缓冲?
l 这个驱动程序可以使用哪些hooks钩子?
struct iio_dev {[...]int modes;int currentmode;struct device dev;struct iio_buffer *buffer;int scan_bytes;const unsigned long *available_scan_masks;const unsigned long *active_scan_mask;bool scan_timestamp;struct iio_trigger *trig;struct iio_poll_func *pollfunc;struct iio_chan_spec const *channels;int num_channels;const char *name;const struct iio_info *info;const struct iio_buffer_setup_ops *setup_ops;struct cdev chrdev;};
完整的结构在IIO头文件中定义。 我们将不感兴趣的字段在此处删除。
modes: 这表示设备支持的不同模式。 支持的模式有:
INDIO_DIRECT_MODE表示设备提供的sysfs接口。
INDIO_BUFFER_TRIGGERED表示设备支持硬件触发器。使用iio_triggered_buffer_setup()函数设置触发缓冲区时,此模式会自动添加到设备中。
INDIO_BUFFER_HARDWARE表示设备具有硬件缓冲区。
INDIO_ALL_BUFFER_MODES是上述两者的联合。
l currentmode: 这表示设备实际使用的模式。
l dev: 这表示IIO设备所依赖的struct设备(根据Linux设备型号)。
l buffer: 这是您的数据缓冲区,在使用触发缓冲区模式时会推送到用户空间。 使用iio_triggered_buffer_setup函数启用触发缓冲区支持时,它会自动分配并与您的设备关联。
l scan_bytes: 这是捕获并馈送到缓冲区的字节数。 当从用户空间使用触发缓冲区时,缓冲区应至少为indio-> scan_bytes字节大。
l available_scan_masks: 这是允许的位掩码的可选数组。 使用触发缓冲器时,可以启用通道捕获并将其馈入IIO缓冲区。 如果您不想允许某些通道启用,则应仅使用允许的通道填充此数组。 以下是为加速度计(带有X,Y和Z通道)提供扫描掩码的示例:
/** Bitmasks 0x7 (0b111) and 0 (0b000) are allowed.* It means one can enable none or all of them.* one can't for example enable only channel X and Y*/static const unsigned long my_scan_masks[] = {0x7, 0}; indio_dev->available_scan_masks = my_scan_masks;
l active_scan_mask: 这是启用通道的位掩码。 只有来自这些通道的数据能被推入缓冲区。 例如,对于8通道ADC转换器,如果只启用第一个(0),第三个(2)和最后一个(7)通道,则位掩码将为0b10000101(0x85)。 active_scan_mask将设置为0x85。 然后,驱动程序可以使用for_each_set_bit宏遍历每个设置位,根据通道获取数据,并填充缓冲区。
l scan_timestamp: 这告诉我们是否将捕获时间戳推入缓冲区。 如果为true,则将时间戳作为缓冲区的最后一个元素。 时间戳大8字节(64位)。
l trig: 这是当前设备触发器(支持缓冲模式时)。
l pollfunc:这是在接收的触发器上运行的函数。
l channels: 这表示通道规范结构,用于描述设备具有的每个通道。
l num_channels: 这表示通道中指定的通道数。
l name: 这表示设备名称。
l info: 来自驱动程序的回调和持续信息。
l setup_ops: 启用/禁用缓冲区之前和之后调用的回调函数集。 这个结构在include / linux / iio / iio.h中定义,如下所示:
struct iio_buffer_setup_ops {int (* preenable) (struct iio_dev *);int (* postenable) (struct iio_dev *);int (* predisable) (struct iio_dev *);



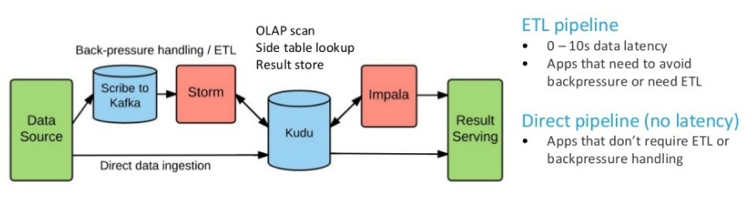






![Apache Kudo: 1.0版和未来 [session]](https://img-blog.csdnimg.cn/img_convert/a84cb36325c24b39dbcfe69b0a9a343c.png)