目录
介绍:
基础架构:
关于Tablet:
Kudu与Impala集成
安装Kudu
配置Impala支持Kudu:
使用案例:
创建表:
查询Impala中现有的Kudu表
使用CREATE TABLE AS SELECT语句查询Impala中的任何其他表或来创建表:
不支持Kudu表的Impala关键字:
将数据插入Kudu表:
参考—Apache-kudu官网-https://kudu.apache.org/overview.html
介绍:
Apache kudu是为hadooop平台开放的柱状(列式)存储管理器。kudu拥有hadoop生态系统应用程序的常见技术:它在商用硬件上运行,可横向扩展,并支持高可用性操作。
kudu的好处:
1. 快速处理OLAP平台负载
2.与mapreduce,spark和其它hadoop生态系统组件集成
3.与impala紧密集成,使其成为Apache Parquent中使用HDFS的一个好的,可变的替换方案
4.强大但灵活的一致性模型,允许您根据每个请求选择一致性要求,包括严格可序列化的选项
5.同时运行顺序和随机负载的强大性能
6.易于管理和administer
7.高可用性,Tablet Servers and masters 使用Raft Consensus Algorithm,该算法可确保只要副本总数的一半以上Tablet Servers就可以进行读写操作。例如有3个副本中的2个副本,或者5个副本中的3个副本可用,就可以使用tablet Servers。即使在leader tablet 发生故障的时候read-only follower也可以为Reders提供读取服务。
基础架构:
kudu采用了Master-slave形式的中心节点架构,管理节点被称为Kudu Master,数据节点被称为Tablet Server(可以对比理解HBase中的RS)。一个表的数据被分割成1个或者多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
kudu Master在Kudu集群中发挥着以下的作用:
1.用来存放一些表的schema信息,且负责处理建表等请求
2.跟踪管理集群中的所有Tablet Server,并且在Tablet Server异常之后协调数据的重新部署
3.存放Tablet到Tablet Server的部署信息。
关于Tablet:
Tablet和Hbase的Region大致相似,但存在以下以一些明显的区别点:
Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。另外一种是基于Rang Partition方式,数据将按照用户数据指定的有序的Primary Key Columns的组合String 的顺序进行分区。而Hbase中仅仅提供了一种按用户数据Rowkey的Rang Partition方式。
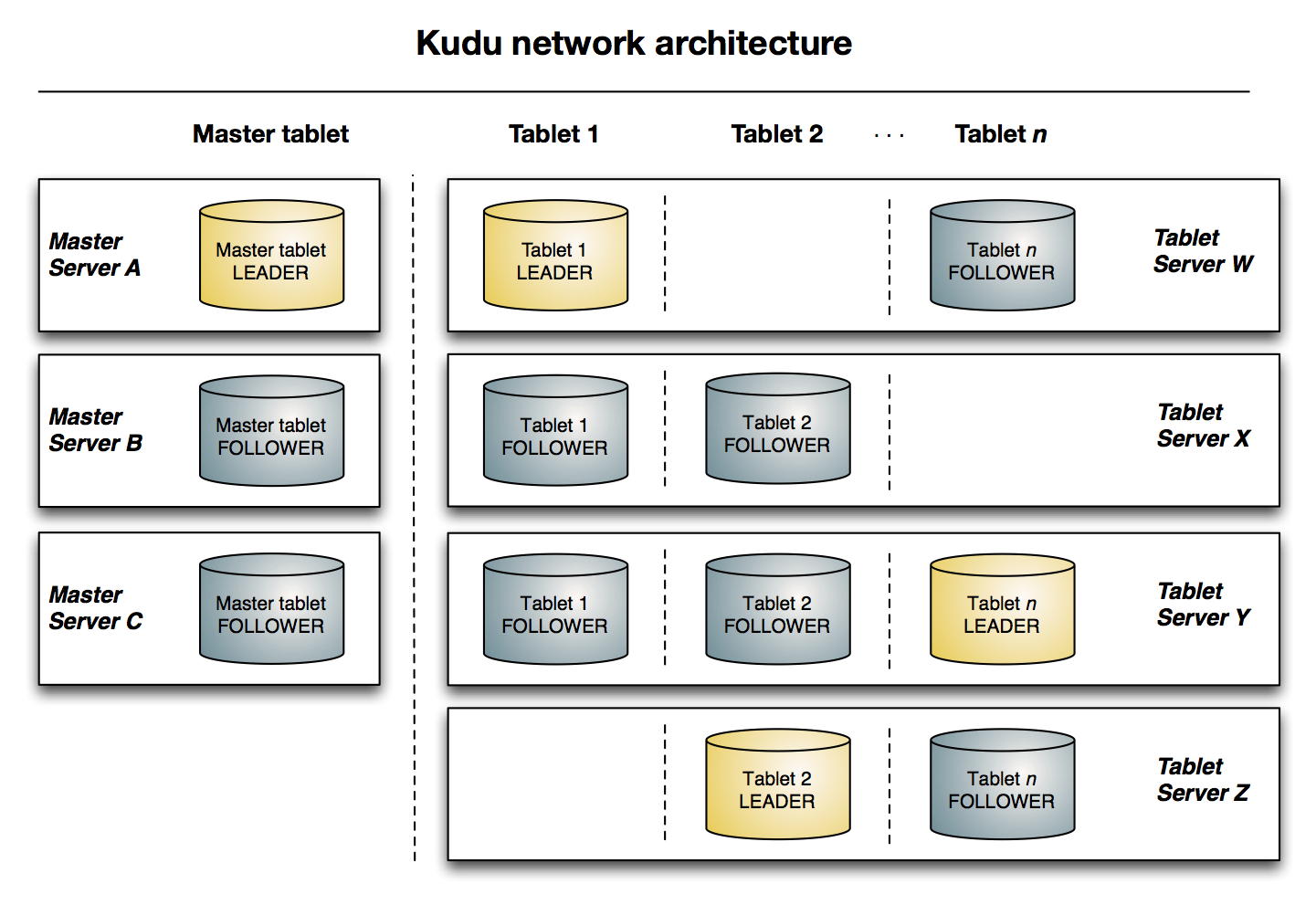
Apache kudu官方架构图配图
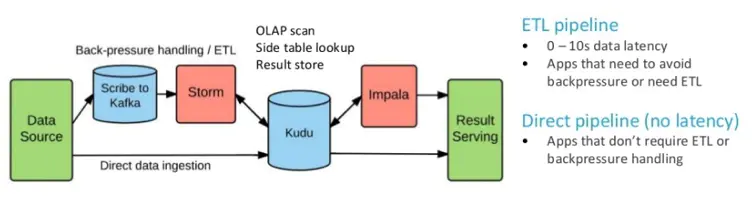
Kudu与Impala集成
CREATE/ALTER/DROP TABLEImpala支持使用Kudu作为持久层创建,更改和删除表,这些表遵循与Impala中其他表相同的内部/外部方法,允许灵活的数据提取和查询。
INSERT可使用与任何其它Impala表相同的语法将数据插入Impala中的kudu表,例如使用HDFS或者HBASE进行持久化的表。
UPDATE / DELETEImpala支持UPDATE 和 DELETE sql命令逐行或批量修改kudu表中的现有数据。选择SQL命令的语法与现有标准尽可能多的兼容。除了simple DELETE 或 UPDATE命令之外,还可以使用FROM子查询中的子句指定复杂链接。
--灵活的分区
与Hive中的表分区类似,Kudu允许您通过散列或者范围动态地将表预分割为预定义数量的平板电脑,以便在整个集群中均匀分配写入和查询。您可以按任意数量的主键列,任意数量的哈希值和可选的拆分列表进行分区。
---并行扫描
为了在现在硬件上实现最高性能,Impala使用的Kudu客户端在多个 Tablet Servers上并行扫描。
--高效查询
在可能的情况下,Impala将为此下推到Kudu,以便尽可能接近数据评估为此。在许多工作负载中,查询性能与Parquent相当。
安装Kudu

点击主机下面的Parcel:
点击Kudu对应的下载,之后点击分配,激活

回到首页-点击添加服务--选择kudu-选择继续--分配角色

设置master和Tablet的路径

配置Impala支持Kudu:
点击Impala,点击配置--找到kudu服务,选择kudu后重启Implala
使用案例:
创建表:
从Impala中在Kudu中创建一个新表类似于现有的Kudu表映射到Impala表,但需要自己指定模式和分区信息。
在CREATE TABLE 语句中,必须首先列出构成主键的列,此外,主键列隐式的标记为NOT NULL.
创建新的Kudu表时们需要指定一个分配方案:
CREATE TABLE kudu_table(id INT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU查询Impala中现有的Kudu表
通过Kudu API或者其它集成(Spark等)创建的表不会再Impala中自动显示。要查询它们,必须在Impala中创建外部表以将Kudu表映射到Impala数据库中。
CREATE EXTERNAL TABLES my_mapping_table
STORED AS KUDU
TBLPROPERTIES ('kudu.table_name' = 'kudu中的tableName'
);使用CREATE TABLE AS SELECT语句查询Impala中的任何其他表或来创建表:
以下示例在现有表old_table中的所有行导入到Kudu表new_table中。new_table中的列的名称和类型将根据SELECT语句的结果集中的列确定。
注意--------必须另外指定主键和分区。
CREATE TABLE new_table
PRIMARY KEY(id)
PARTITION BY HASH(id) PARTITIONS 8
STORED AS KUDU
AS SELECT id,name FROM old_table;不支持Kudu表的Impala关键字:
创建Kudu表时不支持以下Impala关键字:
- PARTITIONED- LOCATION
- ROW FORMAT
将数据插入Kudu表:
Impala允许使用SQL语句将数据插入Kudu表。但是不支持update操作修改主键的值。其它与标准的SQL语法相同。


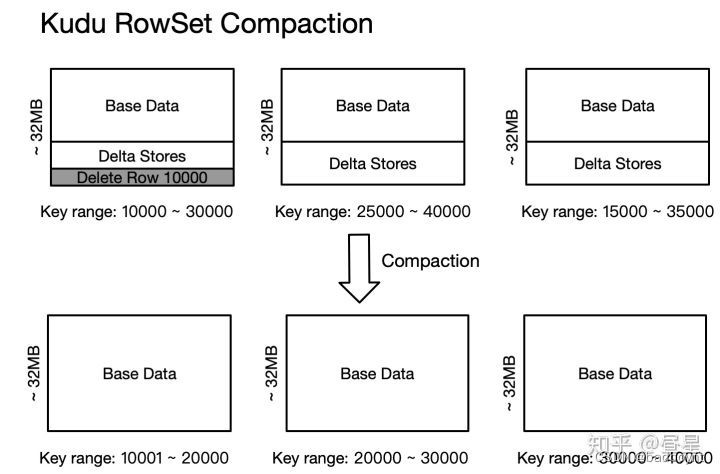
![Apache Kudo: 1.0版和未来 [session]](https://img-blog.csdnimg.cn/img_convert/a84cb36325c24b39dbcfe69b0a9a343c.png)
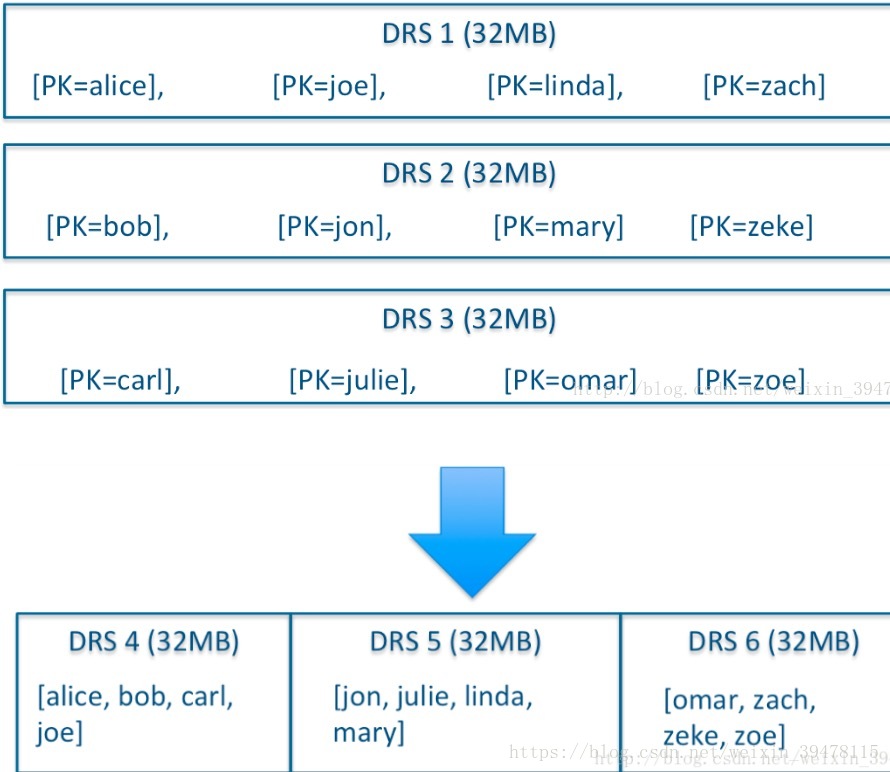









![[高通SDM450][Android9.0]adb无法进行remount的解决方案](https://img-blog.csdnimg.cn/8cd70d682083497fa1a65107184fa104.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATXIuIEhlYmlu,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)


