前文:
过往采用Hive的离线处理时效性低,计算任务过于集中,查询效率低。SparkStreaming+Hive的数据清洗线使得多套数据流过于复杂。未来的数据仓库场景越来越趋向于实时数仓。
一、引入

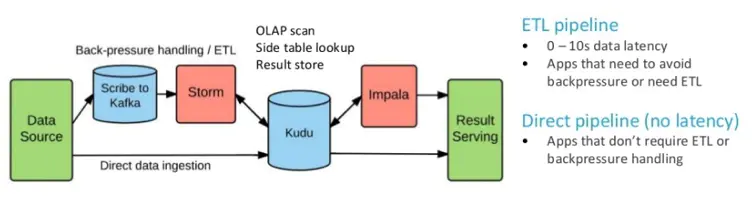
二、架构图

2、架构及数据量

3、文件结构

4、目录结构

5、读写流程及分区策略

三、分区及策略

四、代码
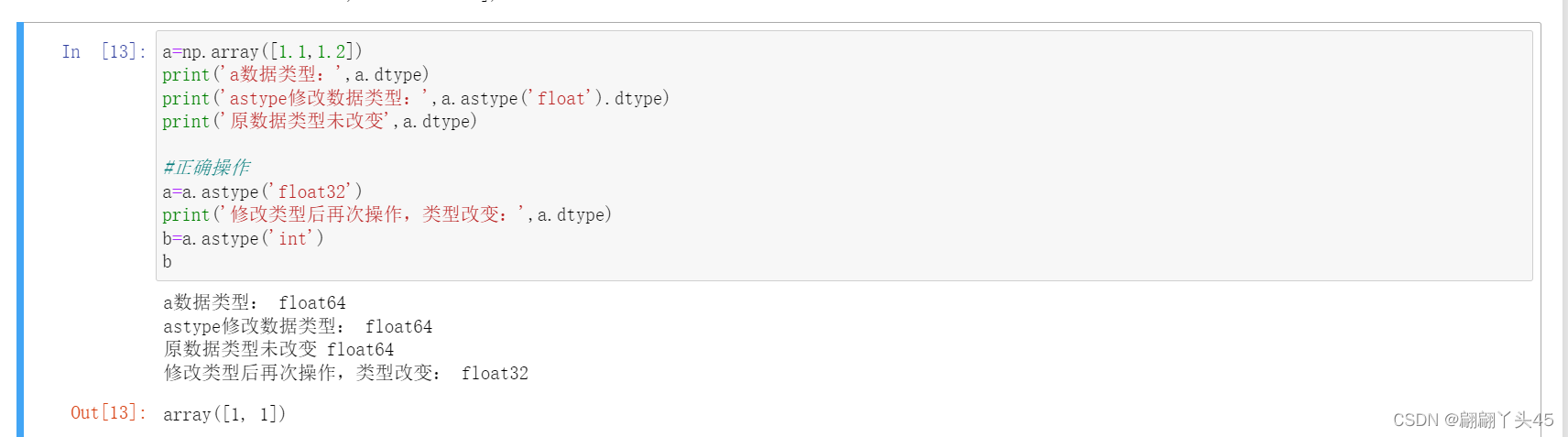
1、通过SparkSql操作数据
object kudu_02_Main {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("kudu_02_Main").getOrCreate()val df = spark.read.options(Map("kudu.master" -> "kudu-01:7051","kudu.table" -> "impala::test.my_table_kudu")).format("org.apache.kudu.spark.kudu").load()//.kududf.show();/*** +------+---------------------+---------+* | name | time | message |* +------+---------------------+---------+* | joey | 2018-01-01 00:00:00 | hello |* | ross | 2018-02-01 00:00:00 | goodbye |* +------+---------------------+---------+*/df.select("name").where("name = 'joey'").show()println("######################################################################")// //注册全局视窗
// df.createGlobalTempView("my_table_kudu1")
// spark.sql("select * from global_temp.my_table_kudu1").show()//注册临时视窗df.createOrReplaceTempView("my_table_kudu2")spark.sql("select * from my_table_kudu2 where name = 'joey'").show()/*** create table test.my_tb2_kudu(* name string,* age int,* city string,* primary key(name)* )* partition by hash(name) partitions 2* stored as kudu;*/val students: Array[Student] = Array(Student("jack", 30, "new york"),Student("jason", 20, "beijing"),Student("cesar", 18, "guangzhou"),Student("anderson", 25, "dongguang"))import spark.implicits._val stuRDD: RDD[Student] = spark.sparkContext.parallelize(students)val stuDF = stuRDD.toDF()stuDF.write.options(Map("kudu.master"-> "bt-03:7051", "kudu.table"-> "impala::test.my_tb2_kudu")).mode("append").format("org.apache.kudu.spark.kudu").save}
}
2、通过kuduContext操作数据
object kudu_03_Main {case class Student(name: String, age: Int, city: String)case class delStu(name:String)def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("kudu_03_Main").getOrCreate()val kuduContext = new KuduContext("kudu-01:7051", spark.sparkContext)println(kuduContext.tableExists("impala::test.my_table_kudu"))/*** 建表语句* create table test.my_tb3_kudu(* name string,* age int,* city string,* primary key(name)* )* partition by hash(name) partitions 2* stored as kudu;*///增加val students: Array[Student] = Array(Student("jack", 30, "new york"),Student("jason", 20, "beijing"),Student("cesar", 18, "guangzhou"),Student("anderson", 25, "dongguang"))//RDD与DF互相转换import spark.implicits._val studentsRDD: RDD[Student] = spark.sparkContext.parallelize(students)val df: DataFrame = studentsRDD.toDF()df.show()//kuduContext.insertRows(df,"impala::test.my_tb3_kudu")val new_stu: Array[Student] = Array(Student("jack", 31, "dongbei"),Student("jason", 21, "shanghai"))val new_setRDD: RDD[Student] = spark.sparkContext.parallelize(new_stu)val df4 = new_setRDD.toDF()kuduContext.upsertRows(df4,"impala::test.my_tb3_kudu")//删除val delStus: Seq[delStu] = Seq(delStu("jason"),delStu("cesar"))//RDD与DF互相转换import spark.implicits._val delStusRDD: RDD[delStu] = spark.sparkContext.parallelize(delStus)val df1: DataFrame = delStusRDD.toDF()df1.show()//kuduContext.deleteRows(df1,"impala::test.my_tb3_kudu")val df2 = spark.read.options(Map("kudu.master" -> "bt-03:7051","kudu.table" -> "impala::test.my_tb3_kudu")).format("org.apache.kudu.spark.kudu").load()df2.show()df2.createOrReplaceTempView("my_tb3_kudu")val df3: DataFrame = spark.sql("select name from my_tb3_kudu where name = 'anderson'")//kuduContext.deleteRows(df3,"impala::test.my_tb3_kudu")}}
五、Kudu和HBase的对比

六、配置
master.gflagfile
# Do not modify these two lines. If you wish to change these variables,
# modify them in /etc/default/kudu-master.
--fromenv=rpc_bind_addresses
--fromenv=log_dir--fs_wal_dir=/data/kudu/wal/master
--fs_data_dirs=/data/kudu/data/master
--master_addresses=kudu-01:7051,kudu-02:7051,kudu-03:7051
-rpc_encryption=disabled
-rpc_authentication=disabled
-trusted_subnets=0.0.0.0/0--rpc_num_acceptors_per_address=5
--master_ts_rpc_timeout_ms=60000
--rpc_service_queue_length=1000tserver.gflagfile
# Do not modify these two lines. If you wish to change these variables,
# modify them in /etc/default/kudu-tserver.
--fromenv=rpc_bind_addresses
--fromenv=log_dir--fs_wal_dir=/data/kudu/wal/server
--fs_data_dirs=/data/kudu/data/server
--tserver_master_addrs=kudu-01:7051,kudu-02:7051,kudu-03:7051
-rpc_encryption=disabled
-rpc_authentication=disabled
-trusted_subnets=0.0.0.0/0#性能调优
--memory_limit_hard_bytes=27917287424
--block_cache_capacity_mb=7680
--maintenance_manager_num_threads=3--rpc_num_acceptors_per_address=5
--master_ts_rpc_timeout_ms=60000
--rpc_service_queue_length=1000







![[高通SDM450][Android9.0]adb无法进行remount的解决方案](https://img-blog.csdnimg.cn/8cd70d682083497fa1a65107184fa104.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATXIuIEhlYmlu,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)