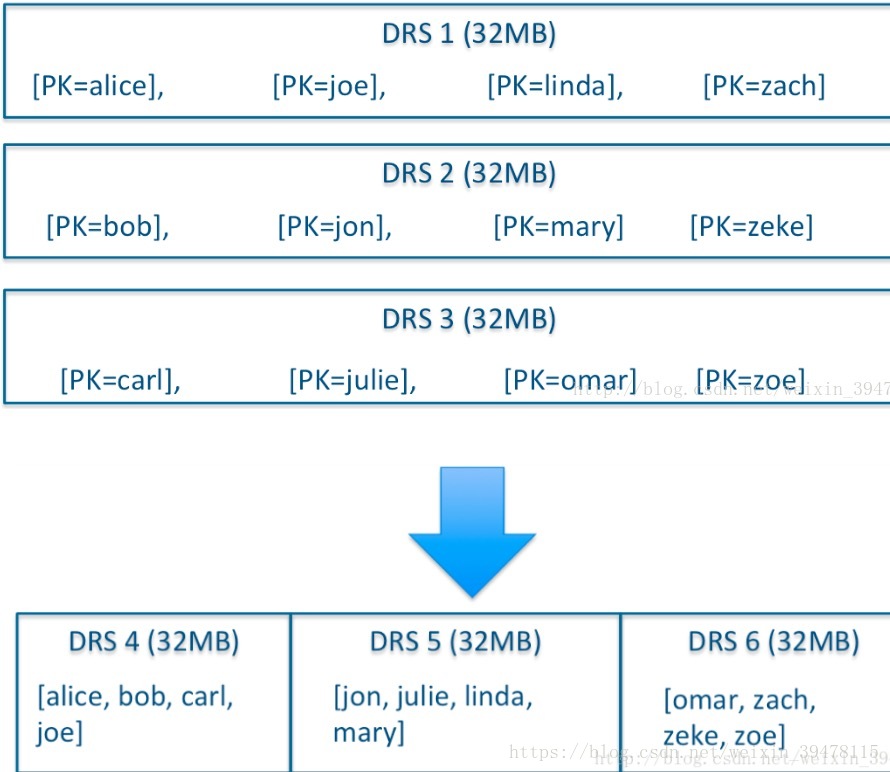
##kudu教程(一)——简介
学习kudu先从kudu官网开始,进入主页https://kudu.apache.org/
我们看到的第一句话就是
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop’s storage layer to enable fast analytics on fast data.
翻译成中文就是说:kudu是新加入hadoop生态系统的开源组件,实现快速数据分析的数据存储。
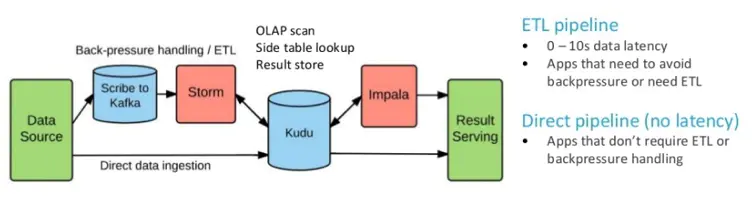
既然kudu处于hadoop生态系统存储层,那么我们就需要了解为什么要用kudu作为存储层,下一章我们就来弄清楚kudu的产生背景。

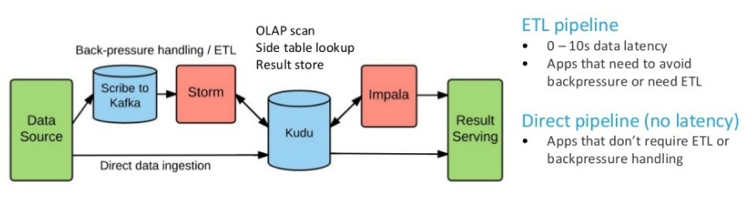






![Apache Kudo: 1.0版和未来 [session]](https://img-blog.csdnimg.cn/img_convert/a84cb36325c24b39dbcfe69b0a9a343c.png)