上一章我们介绍了iio子系统中的iio event模块,本章我们将介绍iio buffer模块,iio buffer主要用于连续数据采集与缓存功能。IIO buffer模块借助IIO DEVICE字符设备文件与应用程序通信,同时借助iio trigger模块与iio device进行交互,因此本章内容分为如下几部分:
一、 IIO DEVICE字符设备文件操作接口
二、iio buffer相关数据结构
三、IIO trigger-buffer介绍
四、IIO buffer相关接口说明
一、 IIO DEVICE字符设备文件操作接口
在IIO 子系统中,每一个IIO DEVICE均会创建一个字符设备文件,名称为/dev/iio:deviceX,该字符设备文件节点在iio_device_register中调用cdev_init、cdev_add完成字符设备文件节点的创建,且文件操作接口为iio_buffer_fileops(而借助sysfs的kobject uevent,则会将cdev add的信息发送给应用程序,应用层的mdev/udev接收到cdev add的uevent之后,则会调用mknod完成字符设备文件节点的创建,详细内容可参考我之前写的字符设备文件专栏的内容LINUX字符设备驱动模块分析(一)相应的驱动模型分析)。
而/dev/iio:deviceX主要实现两个功能:
- 用于读取iio device缓存的已采集数据,从而让应用程序对采集的数据进行分析;
- 借助该字符设备文件的ioctl接口,实现匿名iio event fd的创建,从而让应用程序借助select/epoll监控该匿名文件是否有event信息可读;
如下即是/dev/iio:deviceX的访问流程,应用程序通过open/read/poll/ioctl接口则会调用内核中VFS提供的操作接口,最终则调用iio_buffer_fileops中定义的接口。
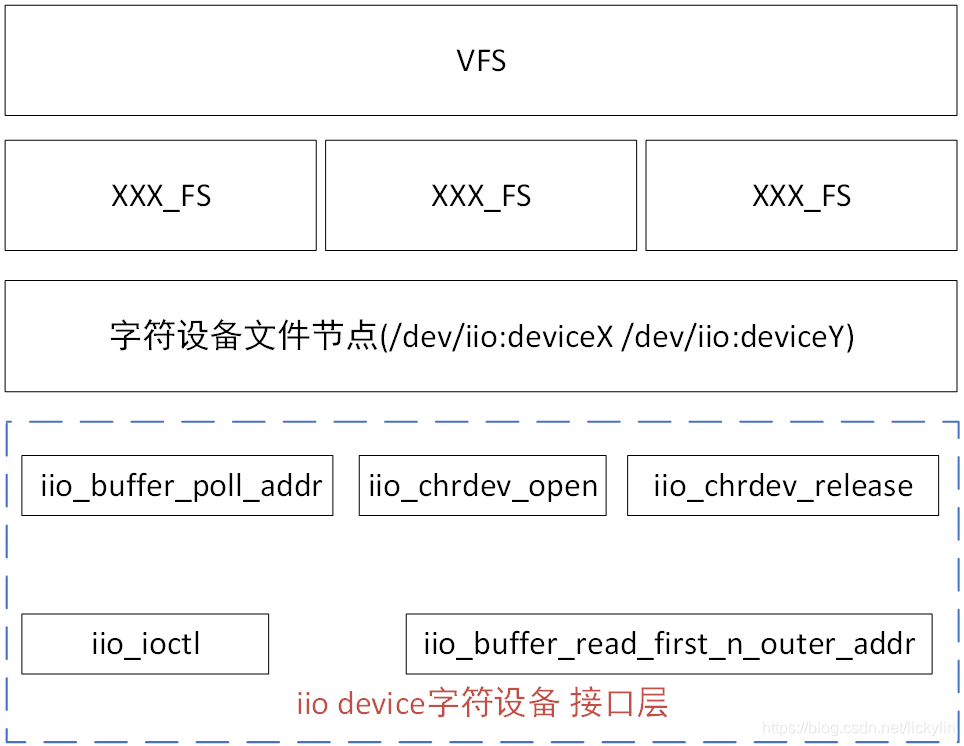
iio_buffer_fileops的定义如下

二、iio buffer相关数据结构
struct iio_buffer与struct iio_buffer_setup_ops
iio_buffer主要是用于存储连续采集数据的缓存,其主要包括两个主要的数据结构struct iio_buffer、struct iio_buffer_access_func(其实是三个数据结构,还有数据结构struct iio_kfifo,其内部包含struct iio_buffer类型变量和struct kfifo类型变量用于缓存数据)。
针对struct iio_buffer主要包括如下几个方面的内容:
- iio_buffer缓存数据的个数(即length);
- iio_buffer每一次采集数据的长度(bytes_per_datum,而bytes_per_datum*length即为kfifo存储数据的内存空间大小);
- Scan_el_dev_attr_list主要用于将所有iio_buffer子模块创建的属性变量集合在一起(iio_buffer);
- scan_el_attrs存储各设备驱动自行定义的静态属性(生成的属性文件在scan_elements子目录下);
- attrs也是存储存储各设备驱动自行定义的静态属性(该变量定义的属性文件在buffer子目录下);
- buffer_group、scan_el_group包含iio buffer子模块下所有属性,其中buffer_group里的属性均在buffer子目录下创建对应的属性文件;scan_el_group里的属性均在scan_elements子目录下创建对应的属性文件;
- pollq为等待队列,主要为iio device的字符设备文件使用(该字符设备文件对应的读接口和poll接口使用,当buffer中不存在数据时则sleep在该等待队列中);
- watermark为缓存多少个数据后,唤醒pollq(实际内存空间大小为watermark*bytes_per_datum)。
针对struct iio_buffer_access_funcs则是该iio_buffer对应的缓存空间的访问访问,目前使用kfifo缓存数据,则其访问方法为iio_store_to_kfifo、iio_read_first_n_kfifo等,主要是将数据存储至kfifo或从kfifo中取出缓存数据等

三、IIO trigger-buffer介绍
借助于IIO trigger机制,iio-device在数据可读时,将数据push 到iio buffer子模块的缓存中,实现缓存连续采集的数据。如下图所示,即为iio trigger-buffer的实现机制,其中红线部分即是iio trigger的部分,而右边黄线部分则是iio buffer的部分。具体说明如下:
- 实现iio trigger的注册,该iio trigger 可支持多个consumer(此处的consumer即为iio buffer),而iio trigger主要是借助其内部实现的虚拟中断控制器,从而实现支持多个consumer;而iio trigger需要与iio device进行绑定,仅在iio device与iio trigger绑定后,iio device driver则可以通过监控iio device触发事件(如中断),然后调用iio_trigger_poll接口,该接口调度所有虚拟中断对应的中断处理函数(即调用iio trigger consumer提供的中断处理接口,而在该中断处理接口中从iio device中读取数据,并调用iio_push_to_buffer,将数据push到iio buffer的kfifo中;
- 而应用程序则通过iio buffer 字符设备文件接口,从iio buffer的kfifo中读取采集的数据信息。)

借助以上的信息,则实现了iio trigger与iio buffer的结合,并实现iio device 采集数据的缓存与读取操作。
四、IIO buffer相关接口说明
iio trigger与iiobuffer关联接口
主要提供接口iio_triggered_buffer_setup用于实现该功能,该接口实现的功能主要包括:
- 申请iio buffer类型的变量,同时完成iio_dev->pollfunc的定义(struct iio_poll_func*类型的变量,该变量主要包含iio trigger内部虚拟中断处理接口的赋值、申请的虚拟中断id等);

- 完成iio_dev->setup_ops的赋值(即struct iio_buffer_setup_ops*类型的变量,该数据结构主要用于实现iio buffer与iiotrigger的绑定与解绑接口,一般使用iio buffer实现的默认变量iio_triggered_buffer_setup_ops), iio_triggered_buffer_setup_ops的定义如下。
- 其中iio_triggered_buffer_postenable则实现iio trigger与iio buffer的绑定,即通过调用iio_trigger_attach_poll_func接口从iio trigger中申请一个虚拟的irq,并完成该irq的中断处理函数的设置;当iio device调用iio_trigger_poll接口将触发信息发送给iio trigger时,iio trigger则会触发所有虚拟中断处理接口,由各中断的中断处理函数从iio device中进行数据的采集,并调用iio_push_buffer接口,将采集的数据push到iio buffer的kfifo中。
- 而iio_triggered_buffer_predisable则解除iio trigger与iio buffer的绑定,即free申请的虚拟irq。
static const struct iio_buffer_setup_ops iio_triggered_buffer_setup_ops = {.postenable = &iio_triggered_buffer_postenable,.predisable = &iio_triggered_buffer_predisable,};
iio buffer相关的sysfs属性文件创建接口
iio_buffer_alloc_sysfs_and_mask接口用于实现iio buffer相关sysfs属性文件的创建,其中创建两类sysfs属性文件:
- iio buffer使能、iio kfifo长度、应用程序可读取数据的最小等待个数,主要是在/sys/bus/iio/devices/iio:deviceX目录下创建子目录buffer,该子目录下创建三个属性文件,分别为enable、length、watermark;
- 其中enable用于实现iio buffer使能的设置及查看,当通过该文件使能iio buffer时,则完成iio buffer的kfifo大小申请、单次采集数据大小更新、已使能的采集通道数据等更新,并最终调用iio_buffer_setup_ops->postenable接口,实现iio trigger与iio buffer的绑定;
- length主要设置iio buffer的kfifo的容量大小;
- watermark则主要修改应用程序一次可读取数据的最小等待个数,当buffer中存储的数据个数超过该值后,则在poll接口iio_buffer_poll中标记该文件可读(epoll、select监控该标记);
- iio buffer相关的采集通道的使能与否相关的sysfs属性文件,主要是在/sys/bus/iio/devices/iio:deviceX目录下创建子目录scan_elements,创建采集通道使能属性文件、采集数据的格式、采集通道的index等,如本专栏实现的虚拟温度芯片(virt0824型号),为两个通道创建了采集通道使能相关的属性文件,如下图所示:

scan_elements目录下的属性文件,则主要是根据iio device driver中定义的struct iio_chan_spec类型变量进行创建,上面的文件主要是根据下面的定义进行创建的(如下蓝色阴影部分,定义了scan index的值、scan type,其中scan index即对应io_tempX_index,而in_tempX_type则主要为scan_type定义的值,这两个属性文件的属性为只读属性):

此处以该device为例,说明如何开启iio buffer,主要分为如下几步:
- 使能采集通道:
echo 1 >scan_elements/in_temp0_en
- 设置iio buffer kfifo长度
echo 16 > buffer/length
- 设置iio buffer watermark
echo 2 > buffer/watermark
- 使能iio buffer
echo 1 > buffer/enable
执行以上各步骤,即可完成iio buffer的使能,现在我们让virt0824xinp触发两次中断,从而触发iio-
trigger-buffer进行数据的采集

然后执行如下命令,看获取到采集数据:

以上即是iio buffer的主要功能,主要说明了iio trigger与iio buffer的绑定部分、iio buffer字符设备文件访问流程、iio buffer相关sysfs属性文件的定义及使用过程。下一章我们分析iio device的注册流程。







![Apache Kudo: 1.0版和未来 [session]](https://img-blog.csdnimg.cn/img_convert/a84cb36325c24b39dbcfe69b0a9a343c.png)