redis为什么这么快,原因之一就是Redis操作都是基于内存的,既然是基于内存的,而内存的大小是有限的,当内存不足或占用过高时,Redis会采用内存淘汰机制进行数据淘汰。
一、Redis的过期策略
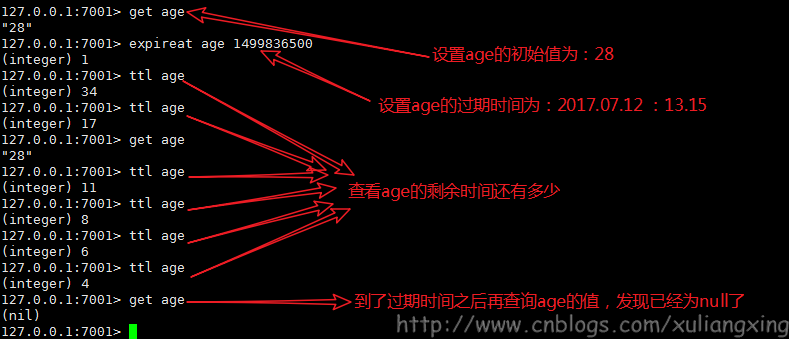
Redis在设置缓存数据时指定了过期时间,到了过期时间数据就失效了,这其中就用到了Redis的过期策略——"定期删除+惰性删除" 。
1、定期删除
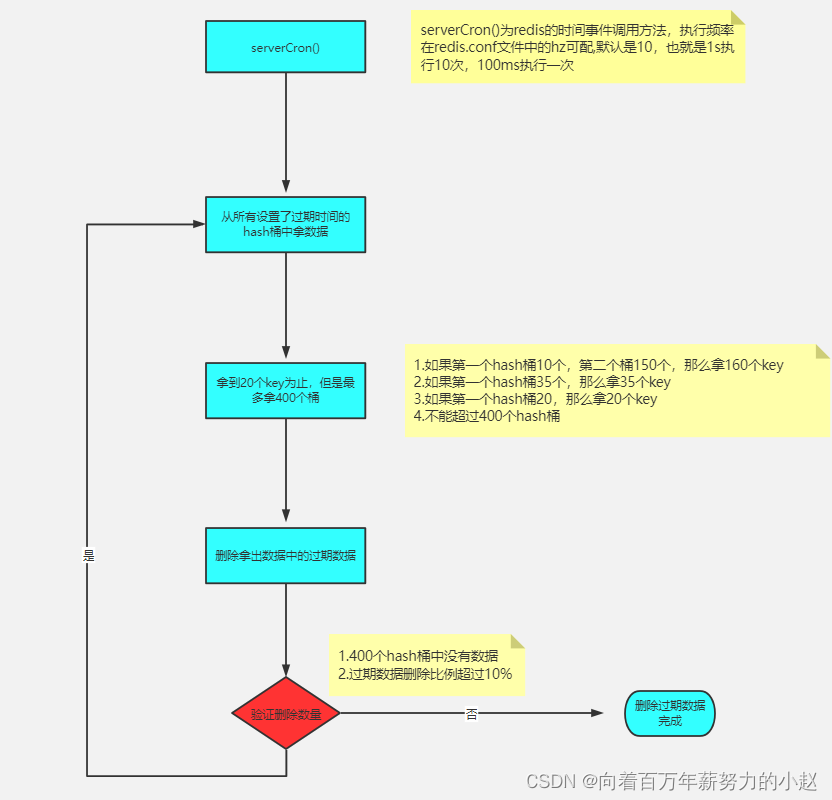
定期删除是指Redis默认每隔 100ms 就 随机抽取 一些设置了过期时间的key,检测这些key是否过期,如果过期了就将其删除。
※ 100ms怎么来的?
在Redis的配置文件redis.conf中有一个属性"hz",默认为10,表示1s执行10次定期删除,即每隔100ms执行一次,可以修改这个配置值。
※ 随机抽取一些检测,一些是多少?
同样是由redis.conf文件中的maxmemory-samples属性决定的,默认为5。
※ 为什么是随机抽取部分检测,而不是全部?
因为如果Redis里面有大量key都设置了过期时间,全部都去检测一遍的话CPU负载就会很高,会浪费大量的时间在检测上面,甚至直接导致redis挂掉。所有只会抽取一部分而不会全部检查。
正因为定期删除只是随机抽取部分key来检测,这样的话就会出现大量已经过期的key并没有被删除,这就是为什么有时候大量的key明明已经过了失效时间,但是redis的内存还是被大量占用的原因 ,为了解决这个问题,Redis又引入了“惰性删除策略”。
2、惰性删除
惰性删除不是去主动删除,而是在你要获取某个key 的时候,redis会先去检测一下这个key是否已经过期,如果没有过期则返回给你,如果已经过期了,那么redis会删除这个key,不会返回给你。
二、Redis内存淘汰机制
"定期删除+惰性删除"就能保证过期的key最终一定会被删掉 ,但是只能保证最终一定会被删除,要是定期删除遗漏的大量过期key,我们在很长的一段时间内也没有再访问这些key,那么这些过期key不就一直会存在于内存中吗?不就会一直占着我们的内存吗?这样不还是会导致redis内存耗尽吗?由于存在这样的问题,所以redis又引入了“内存淘汰机制”来解决。
内存淘汰机制就能保证在redis内存占用过高的时候,去进行内存淘汰,也就是删除一部分key,保证redis的内存占用率不会过高,那么它会淘汰哪些key呢?Redis目前共提供了8种内存淘汰策略,含Redis 4.0版本之后又新增的两种LFU模式:volatile-lfu和allkeys-lfu。

1、什么时候会执行内存淘汰策略,内存占用率过高的标准是什么?
redis.conf配置文件中的 maxmemory 属性限定了 Redis 最大内存使用量,当占用内存大于maxmemory的配置值时会执行内存淘汰策略。
2、内存淘汰策略的配置
内存淘汰机制由redis.conf配置文件中的maxmemory-policy属性设置,没有配置时默认为no-eviction模式。
3、 淘汰策略的执行过程
1、客户端执行一条命令,导致Redis需要增加数据(比如set key value);
2、 Redis会检查内存使用情况,如果内存使用超过 maxmemory,就会按照配置的置换策略maxmemory-policy删除一些key;
3、 再执行新的数据的set操作;
三、其他场景对过期key的处理
1、快照生成RDB文件时
过期的key不会被保存在RDB文件中。
2、服务重启载入RDB文件时
Master载入RDB时,文件中的未过期的键会被正常载入,过期键则会被忽略。Slave 载入RDB 时,文件中的所有键都会被载入,当主从同步时,再和Master保持一致。
3、AOF 文件写入时
因为AOF保存的是执行过的Redis命令,所以如果redis还没有执行del,AOF文件中也不会保存del操作,当过期key被删除时,DEL 命令也会被同步到 AOF 文件中去。
4、重写AOF文件时
执行 BGREWRITEAOF 时 ,过期的key不会被记录到 AOF 文件中。
5、主从同步时
Master 删除 过期 Key 之后,会向所有 Slave 服务器发送一个 DEL命令,Slave 收到通知之后,会删除这些 Key。
Slave 在读取过期键时,不会做判断删除操作,而是继续返回该键对应的值,只有当Master 发送 DEL 通知,Slave才会删除过期键,这是统一、中心化的键删除策略,保证主从服务器的数据一致性。
四、LRU&LFU算法
在上面的8种Redis内存淘汰机制中有xxxLru、xxxLfu模式,这些模式的实现其实是基于LRU或LFU算法实现的
1、LRU
标准LRU算法是这样的:它把数据存放在链表中按照“最近访问”的顺序排列,当某个key被访问时就将此key移动到链表的头部,保证了最近访问过的元素在链表的头部或前面。当链表满了之后,就将"最近最久未使用"的,即链表尾部的元素删除,再将新的元素添加至链表头部。
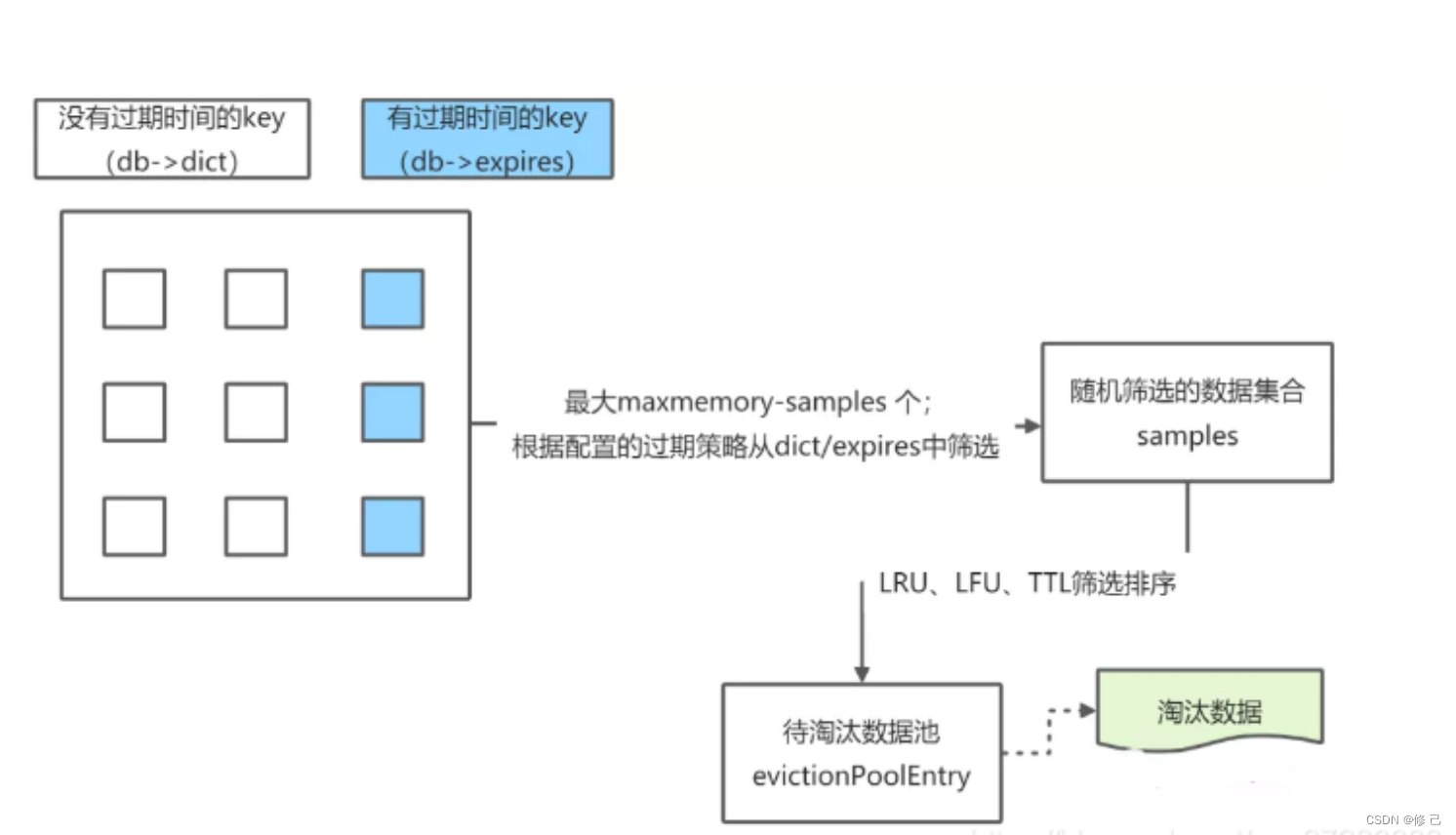
因为标准LRU算法需要消耗大量的内存,所以Redis采用了一种近似LRU的做法:给每个key增加一个大小为24bit的属性字段,代表最后一次被访问的时间戳。然后随机采样出5个key,淘汰掉最旧的key,直到Redis占用内存小于maxmemory为止。其中随机采样的数量可以通过Redis配置文件中的 maxmemory_samples 属性来调整,默认是5,采样数量越大越接近于标准LRU算法,但也会带来性能的消耗。
在Redis 3.0以后增加了LRU淘汰池,进一步提高了与标准LRU算法效果的相似度。淘汰池即维护的一个数组,数组大小等于抽样数量 maxmemory_samples,在每一次淘汰时,新随机抽取的key和淘汰池中的key进行合并,然后淘汰掉最旧的key,将剩余较旧的前面5个key放入淘汰池中待下一次循环使用。假如maxmemory_samples=5,随机抽取5个元素,淘汰池中还有5个元素,相当于变相的maxmemory_samples=10了,所以进一步提高了与LRU算法的相似度。
※ 利用LinkedHashMap手写一个LRU算法的简单实现!
public class LRU {public static void main(String[] args) {// 定义最大容量为10final int maxSize = 10;// 参数boolean accessOrder含义:false-按照插入顺序排序;true-按照访问顺序排序。Map<Integer, Integer> map = new LinkedHashMap<Integer, Integer>(0, 0.75f, true) {// LinkedHashMap加入新元素时会自动调用该方法,若返回true,则会删除链表尾部的元素@Overrideprotected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {return size() > maxSize;}};// 先往map中加入10个元素(定义的最大容量为10)for (int i = 1; i <= 10; i++) {map.put(i, i);}// 访问一下第6个元素,看看是否会排到链表的头部map.get(6);System.out.println("发现第6个元素排到了链表的头部:" + map.toString());// 再加数据map.put(11, 11);System.out.println("删除链表尾部的元素,再将新的元素添加至链表头部 :" + map.toString());}
}
执行结果:
2、LFU【最近最少使用】
假设在位置※时需要删除一个元素,对比A和B,如果使用LRU,那么删除的应该是A,因为A上次被访问距现在的时间更长,但我们发现这是不合理的,因为其实A元素被访问更频繁、更热点,所以我们实际希望删除的是B,保留A,LFU就是为应对这种情况而生的。
在Redis LFU算法中,为每个key维护了一个计数器,每次key被访问的时候,计数器增大,计数器越大,则认为访问越频繁。但其实这样会有问题,
1、因为访问频率是动态变化的,前段时间频繁访问的key,之后也可能很少再访问(如微博热搜)。为了解决这个问题,Redis记录了每个key最后一次被访问的时间,随着时间的推移,如果某个key再没有被访问过,计数器的值也会逐渐降低。
2、新生key问题,对于新加入缓存的key,因为还没有被访问过,计数器的值如果为0,就算这个key是热点key,因为计数器值太小,也会被淘汰机制淘汰掉。为了解决这个问题,Redis会为新生key的计数器设置一个初始值。
上面说过在Redis LRU算法中,会给每个key维护一个大小为24bit的属性字段,代表最后一次被访问的时间戳。在LFU中也维护了这个24bit的字段,不过被分成了16 bits与8 bits两部分
16 bits 8 bits
+--------------------+------------+
+ Last decr time | LOG_C |
+--------------------+-----------+
其中高16 bits用来记录计数器的上次缩减时间,时间戳,单位精确到分钟。低8 bits用来记录计数器的当前数值。
在redis.conf配置文件中还有2个属性可以调整LFU算法的执行参数:lfu-log-factor、lfu-decay-time。其中lfu-log-factor用来调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。lfu-decay-time是一个以分钟为单位的数值,用来调整counter的缩减速度
原文链接:https://blog.csdn.net/yuanlong122716/article/details/104420880