redis所以的操作都是基于内存的,而每台机器的内存大小都有限制,且全没有磁盘空间那么大,所以如何高效的使用内存对于redis来说是非常关键的。
一、Redis过期策略
如果我们一直往redis中存储数据的话,总会有占满内存的那一刻,为了不数据占满内存,这时候我们就会想的将一些不需要永久保持的数据设置一个过期时间。接下来我们看下以下几个问题:
-
如何设置key的过期时间?
redis提供了四种命令来设置key的过期时间:
(1)EXPIRE key seconds // 设置多少秒后过期
(2)EXPIREAT key timestamp 设置 key 过期时间的时间戳(unix timestamp) 以秒计
(3)PEXPIRE key milliseconds // 设置多少毫秒后过期
(4)PEXPIREAT key milliseconds-timestamp // 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计
移除redis的过期时间:
PERSIST key // 移除key的过期时间,key将保持永久
查询剩余生存时间:
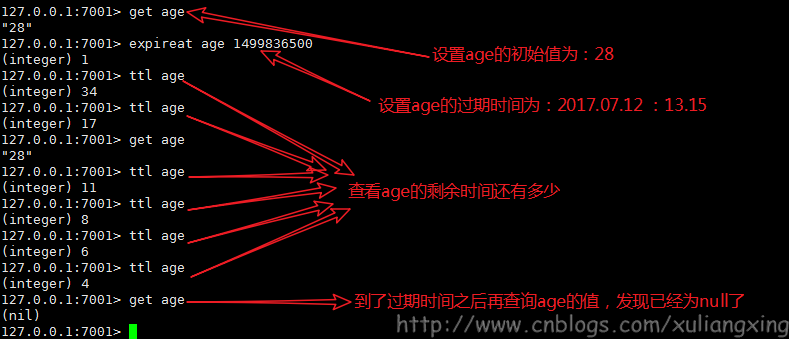
TTL key // 以秒为单位,返回给定 key 的剩余生存时间
PTTL key // 以毫秒为单位返回 key 的剩余的过期时间 -
设置完一个key的过期时间后,到了这个过期时间,这个key保存的数据还占据着内存吗?
当key过期后,该key保存的数据还是会占据内存的,因为每当我们设置一个键的过期时间时,Redis会将该键带上过期时间存放到一个过期字典中。当key过期后,如果没有触发redis的删除策略的话,过期后的数据依然会保存在内存中的,这时候即便这个key已经过期,我们还是能够获取到这个key的数据。 -
redis什么时候去删除过期的数据?
redis过期删除策略通常有三种:定时删除,定期删除,惰性删除。redis使用的是:“定期删除+惰性删除”。
(1) 定时删除
在设置某个key 的过期时间同时,我们创建一个定时器,让定时器在该过期时间到来时,立即执行对其进行删除的操作。
优点:定时删除对内存是最友好的,能够保存内存的key一旦过期就能立即从内存中删除。
缺点:对CPU最不友好,在过期键比较多的时候,删除过期键会占用一部分 CPU 时间,对服务器的响应时间和吞吐量造成影响。
(2) 定期删除
每隔一段时间,我们就对一些key进行检查,删除里面过期的key。Redis默认每隔100ms就随机抽取部分设置了过期时间的key,检测这些key是否过期,如果过期了就将其删除。这里有两点需要注意下:- 默认的每隔100ms是在Redis的配置文件redis.conf中有一个属性"hz",默认为10,表示1s执行10次定期删除,即每隔100ms执行一次,可以修改这个配置的值来设置默认的间隔时间。

- 随机抽取部分,而不是全部key。因为如果Redis里面有大量key都设置了过期时间,全部都去检测一遍的话CPU负载就会很高,会浪费大量的时间在检测上面,甚至直接导致redis挂掉。所有只会抽取一部分而不会全部检查。
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对 CPU 的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好。如果执行的太少,那又和惰性删除一样了,过期键长时间占用的内存没有及时释放的话,当我们再次获取这个过期的key时,依然会返回这个key的值,就相当于这个过期时间是无效的了。
(3) 惰性删除
设置该key 过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。
优点:对 CPU友好,我们只会在使用该键时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查。
缺点:对内存不友好,如果一个键已经过期,但是一直没有使用,那么该键就会一直存在内存中,如果数据库中有很多这种使用不到的过期键,这些键便永远不会被删除,内存永远不会释放,从而造成内存泄漏。所以redis还引入了另一种内存淘汰机制。 - 默认的每隔100ms是在Redis的配置文件redis.conf中有一个属性"hz",默认为10,表示1s执行10次定期删除,即每隔100ms执行一次,可以修改这个配置的值来设置默认的间隔时间。
二、内存淘汰机制
Redis的内存淘汰机制是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
-
如何设置redis内存大小?
在配置文件redis.conf 中,可以通过参数 maxmemory 来设定最大内存。不设定该参数默认是无限制的,但是通常会设定其为物理内存的四分之三。

-
内存淘汰方式有哪些?
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。(默认选项,一般不会选用)
- allkeys-lru:当内存不足以容纳新写入数据时,在整个键空间中,移除最近最少使用的key。(这个是最常用的)
- allkeys-lfu:当内存不足以容纳新写入数据时,在整个键空间中,移除最不经常(最少)使用的key。
- allkeys-random:当内存不足以容纳新写入数据时,在整个键空间中,随机移除某个key。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-lfu:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最不经常(最少)使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
-
如何设置内存淘汰方式?
在配置文件redis.conf 中,可以通过参数maxmemory-policy来设置淘汰的方式。

三、常用的淘汰算法
- FIFO 算法(Fist in first out:先进先出)
FIFO 算法是一种比较容易实现的算法。它的思想:是基于队列的先进先出原则,最先进入的数据会被最先淘汰掉。这是最简单、最公平的一种思想。
(1)实现:维护一个FIFO队列,按照时间顺序将各数据(已分配页面)链接起来组成队列,并将置换指针指向队列的队首。再进行置换时,只需把置换指针所指的数据(页面)顺次换出,并把新加入的数据插到队尾即可。
(2)缺点:这种算法有个很严重的缺点,就是会导致缺页率增加。缺页率指的是判断一个页面置换算法优劣的指标。随着分配页面的增加,被置换的内存页面往往是被频繁访问的,因此FIFO算法会使一些页面频繁地被替换和重新申请内存,从而导致缺页率增加。由于缺页率会随着分配页面的增加而增加,使得redis的开销也逐渐增加,所以这种算法已经不再使用。 - LRU算法(Least recently used:最近最少使用)
LRU算法是一种常见的缓存算法,它的思想是:最近最少使用的会被优先淘汰。如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最久没有访问的数据最先被淘汰掉。
(1)实现:最简单的实现方法是用数组+时间戳的方式,不过这样做效率较低。因此,我们可以用双向链表(LinkedList)+ 哈希表(HashMap)实现(链表用来表示位置,哈希表用来存储和查找),在Java里有对应的数据结构LinkedHashMap。

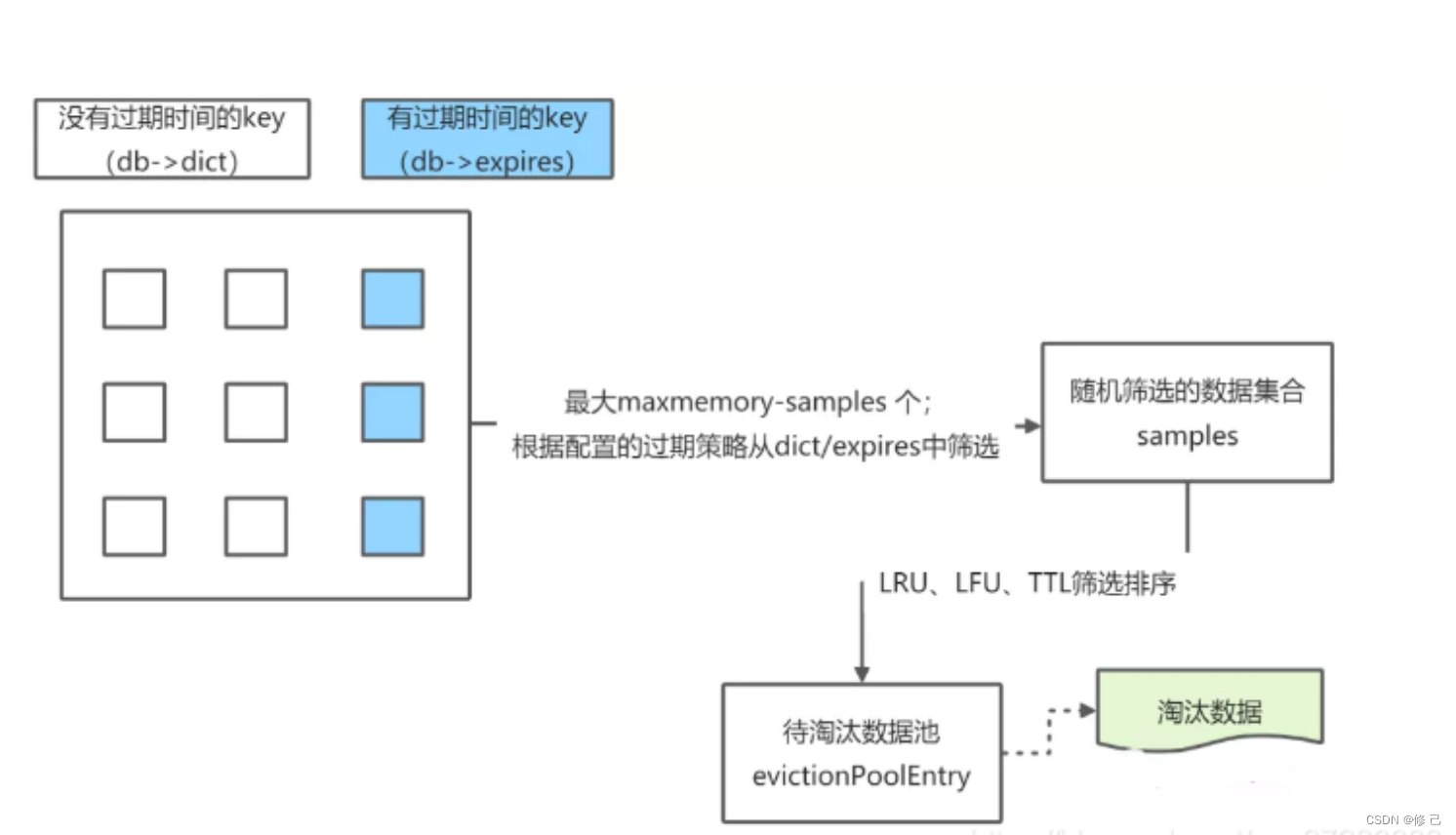
(2)缺点:它在需要淘汰时,只是随机选取有限的key进行对比,排除掉访问时间最久的元素,也就意味着它不能选择整个候选元素的最优解,只是局部最优。默认随机选取的key的数目为5,在配置文件redis.conf 中由maxmemory_samples属性的值决定,采样数量越大越接近于标准LRU算法,但也会带来性能的消耗。在Redis 3.0以后增加了LRU淘汰池,进一步提高了与标准LRU算法效果的相似度。淘汰池即维护的一个数组,数组大小等于抽样数量 maxmemory_samples,在每一次淘汰时,新随机抽取的key和淘汰池中的key进行合并,然后淘汰掉最旧的key,将剩余较旧的前面5个key放入淘汰池中待下一次循环使用。假如maxmemory_samples=5,随机抽取5个元素,淘汰池中还有5个元素,相当于变相的maxmemory_samples=10了,所以进一步提高了与LRU算法的相似度。 - LFU算法(Least frequently used:最不常使用)
LFU算法的思想是:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
实现:如果只为每个key维护了一个计数器,每次key被访问的时候,计数器增大,计数器越大,则认为访问越频繁。这样还是远远不够的,还会存在两个问题:
(1)因为可能存在在开始一个小时内,某个key1有100万的访问量,但是在之后的一个小时内,这个key1的访问量为0了,而在这第二个小时内另外有个key2的访问量达到了20万,虽然这20万不如前面那个key1开始那个小时的100万访问量大,但是在第二个小时内这key2的访问量远大于key1的访问量,所以在第二个小时内key1依然会优先于key2被淘汰掉。
(2)当新加入的key,由于没有被访问过,所以初始的计数器为0,如果这时候触发淘汰机制的话,就会把最先添加到key最先淘汰掉。
所以在LFU算法中维护了这个24bit的字段,不过被分成了16 bits与8 bits两部分。第一部分:高16 bits用来记录计数器的上次缩减时间,时间戳,单位精确到分钟。第二部分:低8 bits用来记录计数器的当前数值,这个数值反映了访问频率,而不是次数。
在redis.conf配置文件中还有2个属性可以调整LFU算法的执行参数:lfu-log-factor、lfu-decay-time。其中lfu-log-factor用来调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。lfu-decay-time是一个以分钟为单位的数值,用来调整counter的缩减速度。
四、总结
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。